


Коротко (TL;DR)
Mac Studio з чипом M3 Ultra — це король пам’яті та пропускної здатності серед компактних машин для локального ШІ. До 512 ГБ єдиної пам’яті і 819 ГБ/с роблять його єдиним споживчим десктопом, який тримає frontier-модель цілком: повний DeepSeek R1 на 671 млрд параметрів (у 4-бітному кванті, ~350–400 ГБ) вантажиться і йде приблизно 16–20 токенів/с. Жодна споживча відеокарта, ні DGX Spark, ні міні-ПК на Strix Halo так не вміють.
Пропускна здатність 819 ГБ/с — це втричі більше, ніж у DGX Spark (273) і Strix Halo (256), тому на моделях, що вже влізли, Mac генерує помітно швидше: на gpt-oss-120B — близько 60–71 ток/с проти ~38 у DGX Spark.
Але «512 ГБ» — оманливий аргумент. У M3 Ultra три чесні слабкі місця: повільний prefill (обробка довгого промпту — на контексті 40–50k він стає майже в 10 разів повільнішим), обрив на паралельних запитах (−70% за багатокористувацького або агентного навантаження) і стіна CUDA (тюнінг і продакшн-сервінг майже безальтернативно йдуть на NVIDIA). Ціна топ-конфігурації теж кусається: від $3 999 за базу до ~$9 499 за 512 ГБ і до $14 099 за максимум. Нижче — що саме він тягне з цифрами і кому реально підходить.
(Дані актуальні на 15 червня 2026; ціни та бенчмарки — з датами в тексті.)
Завдання і бюджет
Mac Studio M3 Ultra — готовий пристрій під локальний інференс відкритих LLM одним користувачем: приватний чат-асистент, кодовий помічник, експерименти з дуже великими відкритими моделями. Його сильна сторона — ємність і швидкість генерації в тихому компактному корпусі; не його мета — продакшн-сервінг на багато користувачів, донавчання моделей і максимальний prompt-throughput (для цього потрібен NVIDIA).

Бюджет — це ціна одного пристрою. База M3 Ultra Mac Studio (96 ГБ) — $3 999; конфігурація з 512 ГБ, яка і потрібна для найбільших моделей, — близько $9 499; повністю укомплектований (512 ГБ + 16 ТБ) сягає $14 099 (за даними на червень 2026). Пам’ять розпаяна в чип — обирати об’єм потрібно одразу при купівлі, наростити потім не можна.
Якщо 512 ГБ надмірні, а frontier-моделі не потрібні, розумна альтернатива всередині лінійки — Mac Studio M4 Max (до 128 ГБ, 546 ГБ/с, від ~$3 699): пропускна здатність удвічі нижча, ніж у M3 Ultra, зате й ціна помітно нижча, а для моделей до 70B у Q4 цього достатньо. Врахуйте нюанс біннінгу: базова версія M4 Max з 32-ядерним GPU втрачає ще близько 25% пропускної здатності — під локальний ШІ беріть старшу, 40-ядерну.
Застереження щодо очікувань: локально ви запускаєте відкриті моделі (Llama, Qwen, DeepSeek, gpt-oss), а не хмарні Gemini чи Claude. Зате — без хмари, без оплати за токени і без витоку даних.
Що таке M3 Ultra і до чого тут 819 ГБ/с
M3 Ultra — старший чип Apple: до 32-ядерного CPU, до 80-ядерного GPU, 32-ядерний Neural Engine і, головне, єдина пам’ять до 512 ГБ із пропускною здатністю 819 ГБ/с, спільна для CPU і GPU. На червень 2026 це найвисокопропускніший десктопний чип Apple — M4 Ultra не існує, тож M3 Ultra лишається вершиною лінійки.
Чому пропускна здатність важливіша за ємність. Інференс LLM на кожному кроці стримить ваги моделі з пам’яті, тому швидкість генерації визначається не об’ємом пам’яті, а її пропускною здатністю. Робоча формула: токенів/с ≈ пропускна здатність ÷ розмір моделі, з поправкою на реальну ефективність ~65%. Пам’ять — це парковка (скільки модель влізе), а пропускна здатність — кількість смуг на шосе (як швидко біжать токени). Те, що інференс упирається саме в bandwidth, підтверджено й академічно (стаття «LLM Inference Unveiled», arXiv 2402.16363).
Звідси роль M3 Ultra: його 512 ГБ дозволяють завантажити те, що не завантажить ніхто, а 819 ГБ/с — віддавати токени втричі швидше за бокси з 256–273 ГБ/с. Але щойно модель влізла в 32 ГБ відеокарти, дискретний GPU з його 1 792 ГБ/с обганяє Mac у рази. Це і є головний компроміс.

Що реально потягне
Нижче — швидкість генерації (decode) на M3 Ultra за моделями в кванті Q4. Цифри — розрахунок за формулою «пропускна здатність ÷ розмір × 65%» (методологія BIZON, травень 2026), звірений із реальними замірами (Alex Ziskind, Dave2D).Модель Параметри / тип Розмір Q4 Decode, ток/с Llama 3.1 8B 8B щільна ~4,9 ГБ ~109 Gemma 3 27B 27B щільна ~16,5 ГБ ~32–41 Qwen3 30B-A3B 30B MoE ~18,6 ГБ ~29 Llama 3.3 70B 70B щільна ~42,5 ГБ ~13 gpt-oss-120B 120B MoE ~60 ГБ ~60–71 Qwen3 235B-A22B 235B MoE ~142 ГБ ~4 Llama 3.1 405B 405B щільна ~245 ГБ ~2 DeepSeek R1 671B 671B MoE ~350–400 ГБ ~16–20
Два висновки. Перший: компактні та MoE-моделі біжать чудово (8B — понад сотню ток/с, 27–30B — комфортні 30–40), щільна 70B — терпимі ~13 ток/с. Другий і головний: тільки M3 Ultra з 512 ГБ запускає frontier-моделі. DeepSeek R1 671B (це MoE, тому активується лише частина ваг — звідси ~16–20 ток/с, а не «повільніше за 405B») реально працює на максимально укомплектованому Mac. Dave2D наміряв на ньому 16,08 ток/с у Q4; на Hacker News повідомляють про ~20 ток/с на 512-ГБ конфігурації.
Важливе застереження «влазить ≠ зручно». У hands-on тесті MacStories (травень 2026) повний DeepSeek R1 685B у 4-бітному кванті завантажився, але велике контекстне вікно не вмістилося: 163 840 токенів не вийшло зовсім, 32k завантажилося з 363 ГБ зайнятої пам’яті й вилітало при першому ж запиті, робочим виявилося скромне вікно ~8 192 токени. Тобто запустити frontier-модель можна, але з тісним контекстом.
Скільки коштує і що з доступністю
Цінова драбина M3 Ultra Mac Studio (на червень 2026): база 96 ГБ — $3 999, конфігурація з 512 ГБ — близько $9 499, повний максимум (512 ГБ + 16 ТБ) — $14 099. Для локального ШІ об’єм пам’яті — єдине, на чому не можна економити: саме він визначає, які моделі ви взагалі завантажите.
Окремо варто знати про ринок. Дефіцит пам’яті розігрів і вторинку: за зведенням із Кореї (X, 8 травня 2026) б/в M3 Ultra на 512 ГБ пішов з ~$11k до $15,7k (+43%), а версія на 256 ГБ — з $6,2k до $11k (+77%). Цікаво, що DGX Spark за той самий період на вторинці, навпаки, подешевшав (−22%): ринок локального ШІ голосує за пропускну здатність. У спільноті трапляється думка, що Mac Studio згортають перед оновленням лінійки — це заява спільноти, а не офіційні дані, але доступність топових конфігурацій зараз напружена.
M3 Ultra проти альтернатив
Порівняємо за тією самою моделлю (gpt-oss-120B, decode) і ключовими параметрами (дані на квітень 2026).Рішення Пам’ять / ПЗ Ціна 120B decode, ток/с Що унікального Mac Studio M3 Ultra до 512 ГБ / 819 ГБ/с $3 999–9 499+ ~70 тримає 671B цілком NVIDIA DGX Spark 128 ГБ / 273 ГБ/с $4 699 ~38 стек CUDA/датацентр Strix Halo (Framework) 128 ГБ / 256 ГБ/с $2 348 ~34 дешевше за всіх на 128 ГБ Збірка на RTX 5090 32 ГБ / 1 792 ГБ/с ~$2 500+ (карта) не влазить у 32 ГБ максимум швидкості ≤32 ГБ 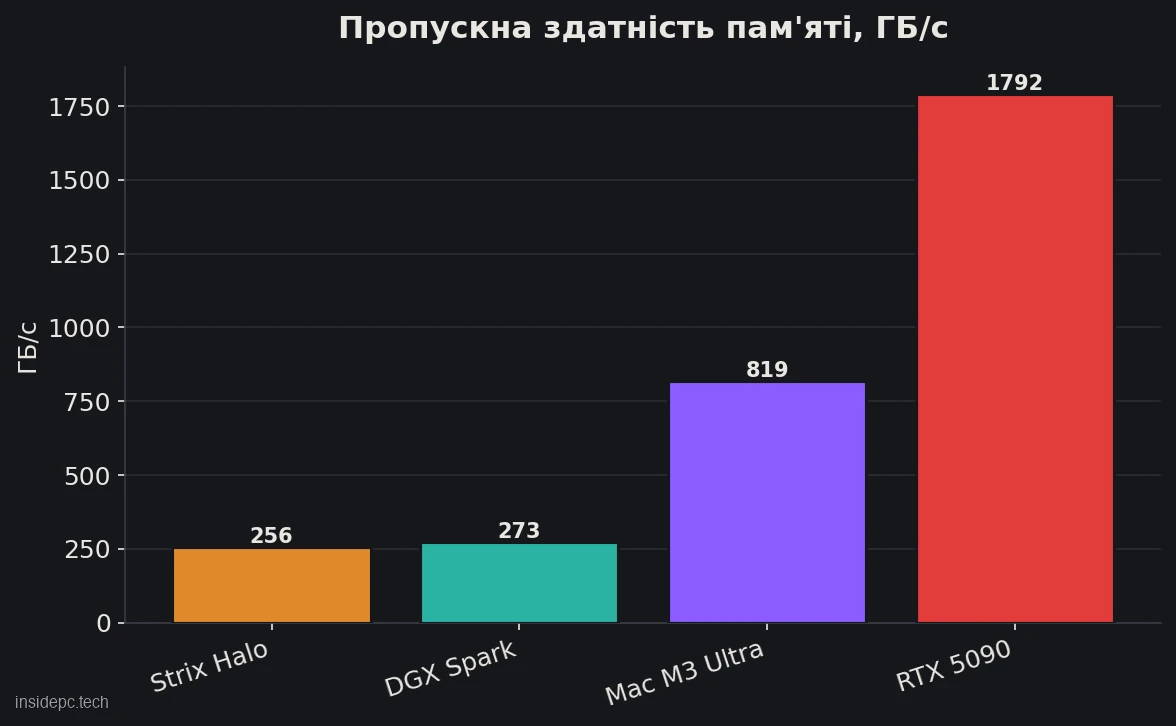
Картина чесна:
- Проти DGX Spark і Strix Halo. Mac швидший на токенах: пропускна здатність 819 ГБ/с проти 256–273 у боксів — утричі вища, і на gpt-oss-120B це ~70 ток/с проти ~38 у DGX Spark (майже вдвічі на цій моделі). Плюс тримає вдвічі-вчетверо більше пам’яті. Але є дзеркальний нюанс: DGX Spark сильний у prefill (обробці промпту), а Mac — у decode (генерації). Тому ентузіасти об’єднують їх через EXO: DGX Spark читає промпт, Mac генерує відповідь — гібрид дає до 2,8× прискорення. Докладний розбір DGX Spark — у нашому огляді NVIDIA DGX Spark, а Strix Halo — в огляді Ryzen AI Max+ 395.
- Проти відеокарти. RTX 5090 з 1 792 ГБ/с (удвічі вище, ніж у M3 Ultra) генерує приблизно вдвічі швидше за Mac — але на моделях, що влазять у її 32 ГБ. 70B Q4 у неї вже не вміщається, а 671B — й поготів. Mac виграє рівно там, де ємність важливіша за швидкість: завантажити модель, яку дискретний GPU не завантажить у принципі.
Короткий підсумок: Mac Studio — найкращий вибір, коли вузьке місце — вмістити модель цілком; відеокарта — коли модель уже влізла і потрібна максимальна швидкість.
Софт, налаштування і масштабування
Екосистема Apple для локального ШІ за 2025–2026 помітно підтягнулася. Базовий набір: MLX (фреймворк Apple під Apple Silicon), LM Studio (із вбудованим MLX-інтерпретатором — найпростіший шлях), Ollama і llama.cpp на Metal. Для одиночного чат-інференсу на готових моделях це зрілий і комфортний стек.
Далі — два сценарії зростання. Перший — кластер: кілька Mac Studio з’єднують по Thunderbolt 5 і через EXO розподіляють одну модель на кілька машин (корисно для моделей більших, ніж тримає один бокс). Другий, згаданий вище, — гібрид із DGX Spark, що закриває слабкий prefill Mac сильним prefill NVIDIA.
Чого на Mac робити не варто: розраховувати на продакшн-сервінг під навантаженням і на донавчання. vLLM і TensorRT-LLM — CUDA-first (порт під Metal з’явився на початку 2026, але сирий і лише для тексту), а інструменти тюнінгу (LoRA, QLoRA, DeepSpeed, FSDP) — майже повністю CUDA-нативні. Покроковий розбір локального інференсу (Ollama, кванти, бекенди) — у нашому розділі локальні нейромережі.
Ризики і слабкі місця
Чесний список того, про що мовчать соло-демки на YouTube (з датами):
- Повільний prefill і довгий контекст. Apple Silicon сильний у генерації, але слабкий в обробці промпту (упор у compute, а не в пам’ять). На контексті 40–50k токенів модель стає майже в 10 разів повільнішою, ніж без контексту (Billy Newport, 2025; практики на Threads, 2026). Для важкого RAG і довгих агентних промптів це відчутно.
- Обрив на паралельних запитах. Другий користувач або агент роняє пропускну здатність M3 Ultra на ~70% (з ~84 до ~25 ток/с), тоді як NVIDIA на vLLM втрачає ~48% (бенчмарки Olares, листопад 2025). Єдина шина пам’яті спільна для CPU, GPU і всіх процесів — агентний стек на 5–10 паралельних запитів насичує її поодинці.
- Стіна CUDA. Тюнінг і продакшн-сервінг ідуть на NVIDIA; Metal/MLX добрі для одиночного чату, але не для цих завдань (BIZON, травень 2026).
- Ціна і перегріта вторинка. 512 ГБ ~$9 499, максимум $14 099; на б/в топові конфіги злетіли на 43–77% через дефіцит пам’яті (Корея, травень 2026).
- «Влазить ≠ зручно». Навіть на 512 ГБ велике контекстне вікно frontier-моделі не вміщається: 685B вантажиться, але робочий контекст — близько 8k токенів, не 163k (MacStories, 2025).
Заради справедливості — плюси вагомі: це єдиний десктоп, що тримає 671B/405B цілком; найшвидший на токенах серед unified-memory машин (3× ПЗ DGX Spark/Strix Halo); тихий компактний корпус без GPU-вентиляторів і з мінімальним енергоспоживанням (проти ~1 050 Вт у збірки з трьох RTX 3090); зрілий MLX-стек для одиночного інференсу.
Кому підходить, а кому ні
- Беріть Mac Studio M3 Ultra, якщо ви один користувач, якому треба запускати дуже великі відкриті моделі (235B–671B) удома, важливі тиша, компактність і приватність, а важкий довгий контекст і донавчання не в пріоритеті.
- Беріть DGX Spark, якщо потрібен паритет зі стеком NVIDIA/CUDA і перенесення напрацювань у дата-центр, і ви готові до повільнішої генерації.
- Беріть Strix Halo (Ryzen AI Max+ 395), якщо вистачає 128 ГБ і важлива мінімальна ціна за гігабайт.
- Зберіть систему на відеокартах, якщо ваші моделі влазять у 24–48 ГБ і потрібні максимальна швидкість, multi-user і донавчання.
FAQ
Які моделі реально запустить Mac Studio M3 Ultra? У 512 ГБ єдиної пам’яті влазить практично будь-яка відкрита модель, включно з DeepSeek R1 671B (MoE) — це єдиний споживчий десктоп із такою можливістю. Швидкість: компактні та MoE-моделі йдуть бадьоро (8B — ~109 ток/с, gpt-oss-120B — ~60–71), щільна 70B — ~13, а 671B — ~16–20 ток/с. Для зручної роботи обирайте конфігурацію під розмір ваших моделей.
Mac Studio M3 Ultra чи DGX Spark для локального LLM? Mac швидше генерує (819 проти 273 ГБ/с — майже вдвічі більше токенів/с) і тримає більше пам’яті. DGX Spark бере стеком CUDA, паритетом з дата-центром і сильнішим prefill. Ідеально — гібрид: DGX Spark обробляє промпт, Mac генерує відповідь (до 2,8× через EXO).
Чому відеокарта швидша за Mac, якщо у Mac більше пам’яті? Швидкість генерації визначається пропускною здатністю пам’яті, а не її об’ємом. У RTX 5090 це 1 792 ГБ/с проти 819 у M3 Ultra — звідси приблизно вдвічі більше токенів/с. Але відеокарта на 32 ГБ не завантажить 70B і тим паче 671B — там, де потрібна ємність, виграє Mac.
Скільки коштує Mac Studio M3 Ultra для ШІ? База 96 ГБ — $3 999, конфігурація з 512 ГБ (для найбільших моделей) — близько $9 499, повний максимум з 16 ТБ — $14 099 (червень 2026). Пам’ять розпаяна, обирайте об’єм одразу. На вторинці топові конфіги зараз перегріті дефіцитом пам’яті.
Чи можна на Mac Studio донавчати моделі й тримати багатокористувацький сервіс? Це слабкі місця платформи. Донавчання (LoRA/QLoRA) і продакшн-сервінг (vLLM/TensorRT-LLM) — CUDA-first, на Mac вони або неможливі, або сирі. За другого-восьмого користувача швидкість падає на ~70%. Для таких завдань беруть NVIDIA; Mac — для одиночного інференсу.
Як зібрати конфігурацію під свою модель і бюджет — у гіді із заліза для локального ШІ.









