


Коротко (TL;DR)
NVIDIA DGX Spark — це компактна «коробка» з чипом GB10 Grace Blackwell і 128 ГБ єдиної пам’яті, у яку цілком вантажаться моделі, що не вміщуються у звичайну відеокарту. За ємністю це прямий конкурент міні-ПК на Ryzen AI Max+ 395 (Strix Halo): ті самі 128 ГБ, майже та сама пропускна здатність пам’яті (273 ГБ/с проти 256 у Strix Halo).
Але купувати DGX Spark заради швидкості — помилка. Його головне обмеження — та сама пропускна здатність: на щільній моделі Llama 70B він видає близько 4 токенів/с, а швидко працюють лише компактні та MoE-моделі (gpt-oss-120B — приблизно 38–50 ток/с, за незалежними замірами). За ті самі гроші і Mac Studio, і збірка на відеокартах генерують у рази швидше.
Реальна цінність DGX Spark в іншому — це девкіт із повним програмним стеком NVIDIA (DGX OS, CUDA, NIM, NemoClaw), точна копія архітектури дата-центрових DGX у міні-форматі. Ви платите $4 699 (на червень 2026; на старті було $3 999) не за токени в секунду, а за те, щоб прототип, обкатаний на столі, без переробок поїхав на сервери H100. Нижче — що саме він тягне з цифрами, скільки коштує і з чим чесно порівнювати.
(Дані актуальні на 15 червня 2026; ціни та бенчмарки — з датами в тексті.)
Завдання і бюджет
DGX Spark — це готовий пристрій під два пов’язані завдання: локальний інференс відкритих LLM (чат, код, RAG, агенти без хмари) і прототипування/донавчання моделей у нативному середовищі NVIDIA з прицілом на подальше перенесення в дата-центр. Не його мета — вичавлювати максимум токенів за секунду за гроші: для цього є дискретні GPU.

Бюджет — це ціна одного бокса: $4 699 за Founders Edition (на червень 2026). Пам’ять розпаяна, графіка інтегрована — ви купуєте готовий прилад із передвстановленою ОС, а не збираєте його по компонентах. Далі все вирішує софт.
Важливе застереження щодо очікувань: це не «локальний ChatGPT». Топові хмарні моделі (Gemini, Claude, клас GPT-5) для такого пристрою завеликі — локально ви запускаєте відкриті моделі (Llama, Qwen, gpt-oss, DeepSeek), а не їхніх хмарних конкурентів.
Що таке DGX Spark і чип GB10
NVIDIA позиціонує DGX Spark як «суперкомп’ютер на стіл». Ключове залізо:
- Чип: GB10 Grace Blackwell — 20-ядерний Arm (10× Cortex-X925 + 10× Cortex-A725) плюс GPU на архітектурі Blackwell з тензорними ядрами 5-го покоління.
- Пам’ять: 128 ГБ LPDDR5x, когерентна єдина для CPU і GPU, шина 256-біт, пропускна здатність 273 ГБ/с.
- Compute: до 1 PFLOP у FP4 — але це розріджений (sparse) FP4 і теоретичний максимум; у реальних замірах MAMF чип видає ~99,8 TFLOPs у BF16 і ~207,7 TFLOPs у FP8 (за даними StorageReview, 2025). «Один петафлоп» — маркетингова цифра, реальний щільний compute приблизно вдвічі нижчий за пікову.
- Накопичувач і мережа: 4 ТБ NVMe із самошифруванням, мережева карта ConnectX-7 на 200 Гбіт/с, 10 GbE, Wi-Fi 7.
- Живлення і габарити: блок 240 Вт (TDP самого чипа GB10 — 140 Вт), корпус 150×150×50,5 мм (~1,13 л), маса 1,2 кг, шум 35 дБ під навантаженням.
Навіщо потрібна єдина пам’ять. У звичайної відеокарти фіксована VRAM (16–32 ГБ), і модель, яка в неї не влізла, переходить у повільний режим із вивантаженням у системну пам’ять. DGX Spark, як і Strix Halo, стирає цю межу: CPU і GPU звертаються до одного пулу на 128 ГБ. Це дозволяє тримати в пам’яті моделі до 200 млрд параметрів — те, що не запустити на жодній споживчій карті.
Що реально потягне
Головне питання — не «чи влізе», а «з якою швидкістю». DGX Spark чудово читає промпт (prefill — стадія, де чип упирається в compute і він сильний), але повільно генерує відповідь (decode — стадія, де все вирішує пропускна здатність пам’яті). Нижче — незалежні заміри (llama.cpp від Георгі Герганова та офіційні тести Ollama; дані жовтня 2025 — січня 2026).Модель Параметри / квант Prefill, ток/с Decode, ток/с Llama 3.1 8B 8B Q4 ~7 600 ~38 gpt-oss-20B 20B MXFP4 (MoE) ~3 200–3 700 ~50–85 DeepSeek-R1 14B 14B Q4 ~5 900 ~20 gemma 3 27B 27B Q4 ~830 ~11 gpt-oss-120B 120B MXFP4 (MoE) ~1 720–1 820 ~38–50 Llama 3.1 70B 70B Q4 ~1 900 ~4,4
Закономірність видно одразу. Щільна Llama 70B генерує близько 4 токенів/с — це повільніше, ніж людина читає: для живого чату неприйнятно, вузьке місце — 273 ГБ/с. А ось MoE-моделі та FP4-формати ламають правило «більше параметрів — повільніше»: gpt-oss-120B (це MoE, де на кожен токен активується лише частина ваг) працює у 9–10 разів швидше за щільну 70B, хоча формально «більша». Той самий ефект ми бачили й на Strix Halo — для такого класу заліза MoE-моделі підходять значно краще за щільні.
Для batch-навантажень (багато паралельних запитів) числа виглядають солідніше: на Llama 3.1 8B у FP4 DGX Spark видає до ~924 ток/с за 128 одночасних запитів (StorageReview, 2025) — це вже про обслуговування сервісу, а не про одиночний чат.
Скільки коштує і чому ціна зросла
З ціною DGX Spark окрема історія, і більшість оглядів (особливо російськомовних) висять на застарілих цифрах. Повна траєкторія:
- $2 999 — анонс на CES 2025 (тоді проєкт називався DIGITS);
- $3 999 — старт реальних поставок (жовтень 2025);
- $4 699 — з 27 лютого 2026 NVIDIA підняла ціну Founders Edition на 18%, пославшись на дефіцит пам’яті LPDDR5X.
Разом +56,7% від анонсу до сьогодні — і відкочувати ціну назад NVIDIA не обіцяла. Це важливо для планування: при купівлі кількох боксів у лабораторію цифра ще може рухатися, доки на ринку пам’яті дефіцит.
Окрім Founders Edition, той самий чип GB10 продають OEM-партнери (ASUS Ascent GX10, Dell Pro Max, HP ZGX Nano, Lenovo, MSI, Gigabyte AI-TOP ATOM, Acer Veriton GN100) — специфікації ті самі, інколи краще охолодження або нижча ціна. Якщо 200-гігабітна мережа ConnectX-7 вам не потрібна (а локальному користувачу вона найчастіше не потрібна), варто придивитися до OEM-версій — за неї у Founders Edition ви переплачуєте.
DGX Spark проти альтернатив
Тут — головне питання статті: чи вартий DGX Spark переплати над конкурентами. Порівняємо за однією й тією самою моделлю (gpt-oss-120B, decode) і за ціною за гігабайт швидкої пам’яті (дані на квітень 2026).Рішення Пам’ять / ПЗ Ціна $ за ГБ 120B decode, ток/с NVIDIA DGX Spark 128 ГБ / 273 ГБ/с $4 699 $36,7 38,6 Strix Halo (Framework Desktop) 128 ГБ / 256 ГБ/с $2 348 $18,3 34,1 Mac Studio M3 Ultra 256 ГБ / 819 ГБ/с $4 999+ $19,5 70,8 Збірка 3× RTX 3090 (б/в) 72 ГБ / 936 ГБ/с ~$2 400 $33,3 124,0 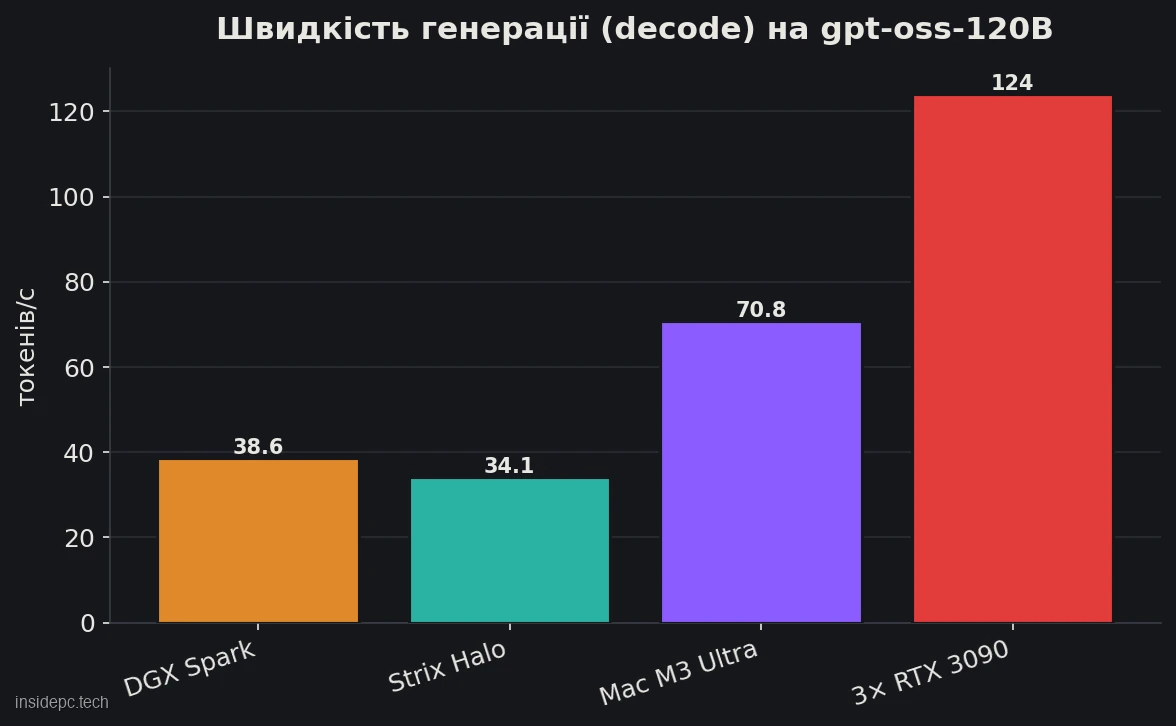
Висновки чесні й незручні для NVIDIA:
- Проти Strix Halo. Та сама ємність (128 ГБ), майже та сама пропускна здатність, майже та сама швидкість генерації (38,6 проти 34,1 ток/с) — але DGX Spark коштує вдвічі дорожче. Єдина реальна перевага в інференсі — потужний prefill: довгий промпт DGX Spark «ковтає» приблизно у 5 разів швидше (1 720 проти ~340 ток/с у Strix Halo). За решту ви доплачуєте ~$2 350 не за токени, а за екосистему CUDA. Докладний розбір самого Strix Halo — у нашому огляді Ryzen AI Max+ 395 для локального LLM.
- Проти Mac Studio. За зіставної ціни Mac Studio M3 Ultra дає втричі більшу пропускну здатність (819 ГБ/с) і майже вдвічі швидше генерує (70,8 ток/с), та ще й удвічі більше пам’яті. Якщо вам важлива швидкість на моделях, що вже влізли, — Mac вигідніший.
- Проти збірки на відеокартах. Три б/в RTX 3090 (72 ГБ сумарно) за ті самі ~$2 400 видають 124 ток/с — утричі швидше за DGX Spark. Ціна: 1 050 Вт проти 240, шум, розмір і день поратися з драйверами. Зате стелю швидкості недосяжна для «коробок». Про дискретні збірки — у розділі залізо для ШІ: відеокарти.
Вердикт спільноти прямий: за співвідношенням «інференс за гроші» DGX Spark програє всім трьом. Його купують не за це.
За що тоді платять: софт-стек і налаштування
Цінність DGX Spark — у програмному паритеті з дата-центром. З коробки йде DGX OS (по суті Ubuntu 24.04 з передвстановленими драйверами та стеком NVIDIA), повноцінний CUDA, контейнери NIM, агентний фреймворк NemoClaw, опційно NVIDIA AI Enterprise. Для розробника це означає: те, що запрацювало на DGX Spark, без переробок поїде на сервери з H100 — ті самі драйвери, той самий CUDA-тулкіт, ті самі інструменти.
Запускати моделі можна звичними рушіями: Ollama і LM Studio — для простоти, llama.cpp — для гнучкості, vLLM і TensorRT-LLM — для високої пропускної здатності та паралельних запитів. Корисний нюанс — формат NVFP4 (нативний для Blackwell): моделі, навчені або донавчені саме під нього, прискорюються кратно, тоді як звичайний інференс лишається «скромним» (за офіційними замірами NVIDIA). Тобто стеля DGX Spark розкривається не на будь-яких вагах, а на підготовлених під його формат.
Окремо варто знати про софт-апдейт CES 2026 (січень): TensorRT-LLM, NVFP4 і спекулятивне декодування Eagle3 дали до 2,5× приросту на частині навантажень (пропускна здатність Qwen-235B зросла більш ніж удвічі, gpt-oss-20B дістався 49,7 ток/с, відеогенерація прискорилася у 8 разів). Тому огляди з жовтневого запуску занижують реальну сьогоднішню швидкість — дивіться свіжі цифри.
Після налаштування софту покроковий розбір локального інференсу (Ollama, кванти, бекенди) — у нашому розділі локальні нейромережі.
Масштабування і апгрейд
Пам’ять розпаяна, тому «доставити планку» не можна — шлях зростання інший:
- Два DGX Spark у зв’язці. Та сама 200-гігабітна мережа ConnectX-7 дозволяє з’єднати два бокси й працювати з моделями до 405 млрд параметрів — основний сценарій, заради якого у Founders Edition узагалі вбудована дорога мережа.
- Гібрид із Mac Studio. Оскільки DGX Spark сильний у prefill, а Mac — у decode, їх можна об’єднати через EXO: DGX Spark обробляє промпт, Mac генерує відповідь. Така «рознесена» схема дає до 2,8× прискорення проти одного Mac Studio (за замірами EXO Labs).
Ризики і слабкі місця
Чесний список того, про що маркетинг мовчить (з датами):
- Повільний decode на щільних моделях. Llama 70B — ~4 ток/с; усе, що упирається в пропускну здатність 273 ГБ/с, гальмуватиме (Ollama/LMSYS, жовт. 2025). Для довгого контексту та щільних моделей це відчутно.
- Ціна зросла і може зростати далі. $3 999 → $4 699 (+18%, 27 лют. 2026) через дефіцит LPDDR5X; +56,7% від анонсу. Купівля «на піку хайпу» окупається погано.
- Єдина пам’ять — це і сила, і ризик. Окремої VRAM немає: помилка браку пам’яті (OOM) під час інференсу або тюнінгу може покласти всю систему. Власники повідомляють про краші під час тренування, зависання мережі та часті жорсткі перезавантаження (r/LocalLLM, червень 2026).
- Софт ще «на вістрі». DGX OS гарантує лише 2 роки підтримки; архітектура ARM64 ламає частину прекомпільованих бінарників (наприклад, окремі збірки PyTorch); помічено термотротлінг із рестартами на довгих прогонах (Jeff Geerling, 2025).
- Маркетинговий «1 PFLOP». Це розріджений FP4; реальний щільний compute помітно нижчий за піковий: незалежний замір дав ~480 TFLOPS у FP4 (Banandre, 2025), а в BF16 чип видає лише ~99,8 TFLOPs (MAMF-замір StorageReview, 2025). Рахуйте за реальними цифрами, а не за піковими.
- Переплата за мережу. У Founders Edition вбудована дорога ConnectX-7 на 200 Гбіт/с, яка одиночному локальному користувачу не потрібна (robert-mcdermott, 2025) — звідси частина ціни та інтерес до OEM-версій.
Заради справедливості — плюси реальні: день-у-день робоче середовище без поратися з драйверами, унікальна ємність (запускає те, що не влазить у споживчі карти на 24–32 ГБ; у вірусній демонстрації в X у травні 2026 бокс тримав чотири ШІ-агенти і ~126 ГБ заразом — карта з 96 ГБ VRAM стільки б не вмістила, але це заява спільноти, а не наш замір), сильний prefill, повнопараметричний тюнінг до 8B локально і до 70B загалом, тихий компактний корпус на 240 Вт, кластеризація до 405B.
Кому підходить, а кому ні
- Беріть DGX Spark, якщо ви ШІ-розробник, дослідник або ML-інженер, якому важливий паритет із дата-центром NVIDIA: прототип на столі → продакшн на H100 без переробок. Плюс приватність і «безкоштовні» локальні токени.
- Беріть Strix Halo (міні-ПК на Ryzen AI Max+ 395), якщо потрібна та сама ємність 128 ГБ під локальні моделі вдвічі дешевше, а CUDA-екосистема не критична.
- Беріть Mac Studio, якщо пріоритет — швидкість генерації та великі моделі: утричі вища пропускна здатність за зіставної ціни.
- Зберіть систему на відеокартах, якщо потрібен максимум токенів за секунду і ви готові до шуму, потужності та налаштування.
FAQ
Скільки коштує NVIDIA DGX Spark у 2026 році? Founders Edition — $4 699 (з 27 лютого 2026; на старті у жовтні 2025 було $3 999, на анонсі CES 2025 — $2 999). Ціну підняли через дефіцит пам’яті LPDDR5X. OEM-версії на тому самому чипі GB10 (ASUS, Dell, HP, Lenovo, MSI) бувають дешевшими.
Які моделі реально запустить DGX Spark? У пам’ять на 128 ГБ влазять моделі до 200 млрд параметрів, а зв’язка з двох боксів — до 405 млрд. Але швидкість залежить від типу моделі: щільна Llama 70B працює лише ~4 ток/с, а MoE-моделі на кшталт gpt-oss-120B — ~38–50 ток/с. Для комфортного локального ШІ обирайте MoE та компактні моделі.
DGX Spark чи Strix Halo (Ryzen AI Max+ 395)? За ємністю та швидкістю генерації вони майже рівні, але Strix Halo вдвічі дешевший. DGX Spark виправданий, лише якщо вам потрібні екосистема CUDA і перенесення напрацювань у дата-центр NVIDIA. Якщо важлива ціна за гігабайт пам’яті — Strix Halo вигідніший.
Чому DGX Spark повільніший за відеокарту в генерації? Швидкість генерації (decode) майже повністю упирається в пропускну здатність пам’яті. У DGX Spark це 273 ГБ/с, у RTX 3090 — ~936 ГБ/с, у RTX 5090 — 1 792 ГБ/с. Тому відеокарти генерують у рази швидше на моделях, що вміщуються в їхню VRAM; перевага DGX Spark — в ємності, а не у швидкості.
Чи можна на DGX Spark донавчати моделі? Так. NVIDIA заявляє тюнінг до 70 млрд параметрів, а в незалежних тестах підтверджено повнопараметричний fine-tuning 8B-моделей локально. Це один із головних сценаріїв пристрою — поряд із прототипуванням у середовищі, ідентичному дата-центру.
Як зібрати конфігурацію під свою модель і бюджет — у гіді із заліза для локального ШІ.









