


Коротко (TL;DR)
Більшість локальних нейромереж працюють лише з текстом. Але є окремий клас — vision-моделі (vision-language, VLM), які «бачать» зображення: описують картинку, читають текст із фотографії (OCR), розбирають скриншоти, діаграми й документи, відповідають на питання за зображенням. І все це можна запустити в себе, без надсилання картинок у хмару.
- Коротко (TL;DR)
- Що таке vision-модель і навіщо вона потрібна
- Як це працює: архітектура за дві хвилини
- Лінійка локальних vision-моделей на червень 2026
- Скільки VRAM потрібно: пастка «файл ≠ відеопам’ять»
- OCR локально: хто краще читає текст
- Запуск: Ollama, LM Studio, llama.cpp
- Налаштування під себе: розширення, контекст, API
- Крихітні vision-моделі для агентів
- Порівняння: коли що обрати
- Ризики й граблі
- FAQ
- Головний довід — приватність. Скани паспортів і договорів, медичні знімки, особисті фото — усе, що ви показуєте локальній моделі, лишається на вашому комп’ютері. Для чутливих документів це вирішує.
- Лідери на 2026 рік. Найкращий відкритий вибір за розпізнаванням тексту й багатомовністю — Qwen2.5-VL. Для слабкого заліза є крихітні MiniCPM-V і Moondream. LLaVA — родоначальник жанру, з якого все почалося.
- Головна пастка — не модель, а пам’ять. Vision-модель «з’їдає» куди більше відеопам’яті, ніж здається за розміром файлу: картинка перетворюється на сотні й тисячі токенів. Файл на 7,8 ГБ може вимагати 24 ГБ VRAM під час роботи із зображеннями.
Мінімальне залізо залежить від моделі: легка Moondream запускається на 4 ГБ, Qwen2.5-VL-7B — на 16 ГБ. Дані актуальні на 16 червня 2026 року.
Що таке vision-модель і навіщо вона потрібна
Звичайна мовна модель уміє працювати лише зі словами. Vision-модель додає до цього «очі»: вона приймає зображення й розуміє, що на ньому. Під капотом це зв’язка з двох частин — візуального енкодера (він «дивиться» на картинку й переводить її в набір чисел-ознак) і звичайної мовної моделі (вона за цими ознаками міркує й відповідає текстом). Між ними — невеликий шар-«перехідник», який і навчили з’єднувати зір із мовою. Саме таку архітектуру у 2023 році популяризувала LLaVA, відкривши дорогу всьому сегменту. Відтоді підхід став стандартом, а якість зросла на порядок: ранні моделі ледь описували прості сцени, а сучасні читають дрібний текст, розуміють графіки й відповідають на складні питання за зображенням. LLaVA дала ім’я цілому класу моделей, і хоча сьогодні лідирують інші, термін «LLaVA-подібні» прижився як позначення всієї родини відкритих vision-моделей.
Навіщо це локально? Головне — приватність і офлайн. Хмарні сервіси на кшталт ChatGPT з картинками зручні, але ви віддаєте їм свої зображення. Для документів із персональними даними, комерційних креслень чи медичних знімків це часто неприйнятно. Локальна vision-модель розв’язує задачу на вашому залізі: жоден піксель не йде назовні. Сценарії — розпізнати текст зі скана, занести дані з фото чека в таблицю, описати зображення для незрячого, розібрати скриншот помилки, витягти цифри з діаграми.

Список реальних застосувань ширший, ніж здається: оцифрувати паперовий архів, перетворити фото дошки після наради на текст, описати товар за фотографією для каталогу, допомогти людині з порушенням зору «прочитати» оточення, розібрати схему чи креслення, перевірити, що саме зображено на надісланому користувачем скриншоті. Усюди, де задача — «зрозуміти, що на картинці», і де саму картинку небажано надсилати на чужий сервер, локальна vision-модель опиняється на місці.

Як це працює: архітектура за дві хвилини
Щоб розуміти обмеження vision-моделей, корисно знати, як вони влаштовані — без формул.
Усередині три блоки. Перший — візуальний енкодер (зазвичай на базі CLIP): він «нарізає» картинку на фрагменти й переводить кожен у набір чисел, що описують, що там зображено. Другий — шар-проектор (невелика нейромережа-«перехідник»): він переводить візуальні ознаки на «мову», зрозумілу текстовій моделі. Третій — сама мовна модель (Llama, Qwen, Vicuna), яка отримує «опис» картинки впереміш із вашим питанням і відповідає текстом.
Ключовий момент, з якого ростуть усі вимоги до пам’яті: картинка перетворюється не на один токен, а на багато візуальних токенів — по суті, на довгий «текст», який модель має прочитати. Зображення середнього розширення легко дає кілька сотень токенів, а велике — кілька тисяч. Мовна модель обробляє їх так само, як слова, тому одна картинка навантажує її сильніше, ніж довгий абзац тексту. Звідси і ненажерливість за відеопам’яттю, і сповільнення на великих зображеннях. Різні моделі «нарізають» картинку по-різному: одні використовують фіксоване розширення, інші — динамічне (адаптуються під розмір і деталізацію), і від цього залежить і якість на дрібному тексті, і витрата пам’яті.
Лінійка локальних vision-моделей на червень 2026
Вибір великий, і моделі сильно різняться за вимогами й сильними сторонами. Ось орієнтир за актуальними відкритими VLM.Модель Параметри VRAM (орієнтир) Швидкість* Сильна в Moondream2 1,9 млрд ~4 ГБ (Q4) дуже висока Легкість, агенти, базовий опис MiniCPM-V (2.6 / 4.6) 1,3–8 млрд ~4–8 ГБ висока OCR і якість на малому залізі Qwen2.5-VL 7B 7 млрд ~16 ГБ (full) ~18 tok/s OCR, документи, 29 мов Pixtral 12B 12 млрд ~24 ГБ (орієнтир) середня Документи, діаграми Llama 3.2 Vision 11B 11 млрд ~24 ГБ ~12 tok/s Опис (англоцентрична) LLaVA / LLaVA-NeXT 7–34 млрд від ~8 ГБ залежить від backbone Класика, експерименти
*Швидкість — орієнтир: ~18 і ~12 токенів/с для Qwen2.5-VL і Llama Vision відповідно за заміром на серверній A100 (джерело: Labellerr, 2026); на домашніх відеокартах буде нижчою. Ліцензії більшості моделей у таблиці — Apache 2.0 або інші відкриті; у Llama 3.2 Vision — Llama Community License.
Короткий розбір: Qwen2.5-VL зараз — найкращий універсал, особливо за розпізнаванням тексту й мовами (про це нижче). MiniCPM-V і Moondream дивують тим, як багато дають за крихітного розміру — їх часто хвалять за співвідношення «якість на гігабайт». Llama 3.2 Vision сильна в описі, але заточена під англійську. Pixtral 12B від Mistral хороший для документів і діаграм. LLaVA-NeXT — остання версія родоначальника жанру, хороша для навчання й експериментів. А універсальні Gemma і Qwen3 теж уміють бачити зображення — якщо вам потрібна одна модель «на все», зазирніть у їхні огляди.

Варто знати й про тенденції 2026 року: vision-сегмент розвивається швидко. З’являються все легші моделі (MiniCPM-V у версії 4.6 ужалася до 1,3 млрд параметрів і запускається на смартфоні), а великі відкриті VLM на кшталт InternVL підбираються за якістю до закритих. Окремий тренд — зір іде з десктопа: у червні 2026 року, за повідомленням TechCrunch, vision-модель Gemma розгорнули прямо на орбітальному супутнику для автономного аналізу знімків. Практичний висновок для нас: вибір відкритих vision-моделей зараз широкий як ніколи, і майже під будь-яке залізо є свій варіант.
Скільки VRAM потрібно: пастка «файл ≠ відеопам’ять»
Це найчастіша помилка новачка, і наш головний information gain. Коли ви завантажуєте текстову модель, розмір файлу приблизно відповідає потрібній відеопам’яті. З vision-моделями це правило ламається.
Причина — у тому, як модель «бачить». Картинка для неї не один об’єкт, а сотні або тисячі «візуальних токенів»: що вище розширення зображення, то більше токенів, і всі вони займають відеопам’ять під час роботи. Тому модель Llama 3.2 Vision 11B важить на диску близько 7,8 ГБ (за даними Roboflow, червень 2026), але під час реальної роботи із зображеннями вимагає порядку 24 ГБ VRAM — утричі більше, ніж «за файлом».
Практичний висновок: при виборі vision-моделі дивіться не на розмір завантажуваного файлу, а на вимоги до відеопам’яті при інференсі з картинками. І пам’ятайте: що більші зображення ви подаєте, то більше пам’яті піде. Якщо вперлися в нестачу VRAM — зменшуйте розширення вхідних картинок, це перший і найдієвіший важіль.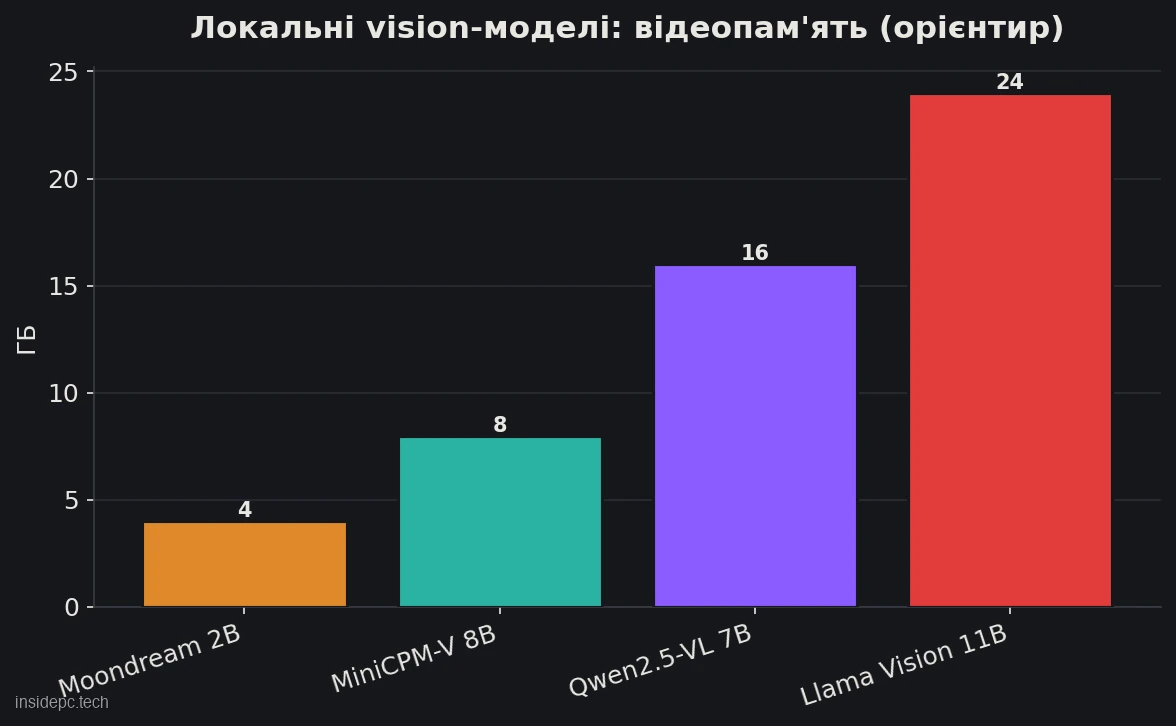
Звідси ж — практичний прийом для слабкого заліза: брати не одну велику мультимодальну модель, а крихітну vision-модель як «інструмент зору» (наприклад, Moondream на 4 ГБ) у зв’язці зі звичайною текстовою LLM-оркестратором. Зорова модель лише описує картинку текстом, а далі міркує текстова — сумарно це часто вимагає менше відеопам’яті, ніж одна велика VLM.
OCR локально: хто краще читає текст
Розпізнавання тексту (OCR) — найзатребуваніший сценарій vision-моделей, і тут є явний лідер. Qwen2.5-VL помітно перевершує конкурентів: за тестом OCRBench він бере близько 864 балів, а на розпізнаванні документів DocVQA — близько 95,7% (за офіційною карткою моделі). Важливо для нас: Qwen2.5-VL підтримує 29 мов, включно з українською, російською та складними східноазійськими, тоді як Llama 3.2 Vision заточена переважно під англійську. Для розпізнавання україно- та російськомовних документів це вирішальний аргумент на користь Qwen.
У локального OCR є реальні обмеження:
- Рукописний текст і погані скани — слабке місце VLM. На розмитих, зім’ятих чи затемнених документах вони нерідко «додумують» текст, який не бачать, спираючись на мовні здогади замість того, щоб визнати, що текст не читається. Це задокументовано свіжим дослідженням (arXiv, червень 2026). Для якісного друкованого тексту моделі справляються добре, для деградованих сканів класичний рушій на кшталт Tesseract часом надійніший.
- Розширення вирішує. Qwen2.5-VL працює з динамічним розширенням (адаптується під картинку), а Llama 3.2 Vision — з фіксованим; на дрібному тексті це помітно впливає на результат.
Для повноти картини — як виглядають конкуренти за роботою з документами. Pixtral 12B від Mistral бере близько 90,7% на DocVQA і сильний у діаграмах (близько 81,8% на ChartQA). MiniCPM-V за свого малого розміру тримається на диво близько до лідерів і часто рекомендується як «бюджетний OCR». InternVL у старших версіях показує один із найкращих результатів серед відкритих моделей на комплексному тесті MMMU. Але для повсякденного розпізнавання документів українською та російською Qwen2.5-VL лишається найзбалансованішим вибором: якість, мови й розумні вимоги до заліза.
Запуск: Ollama, LM Studio, llama.cpp
Запустити vision-модель сьогодні просто. Найлегший шлях — Ollama, який уміє приймати картинки прямо в команді (перевірено за каталогом Ollama, червень 2026):
ollama run qwen2.5-vl "опиши це фото: ./image.jpg"
ollama run llava "describe this image: ./screenshot.png"
ollama run minicpm-v "витягни текст: ./scan.jpg"
ollama run moondream "./photo.jpg"
Ollama одразу піднімає локальний API на localhost:11434, і зображення можна передавати через нього (у base64) — це зручно для скриптів і ботів, які обробляють картинки пачками.
Простий практичний сценарій — перетворити фото чека чи рахунку на структуровані дані. Ви подаєте фотографію й просите: «витягни з цього чека дату, суму й список позицій у вигляді таблиці». Qwen2.5-VL розпізнає текст, розуміє структуру документа й повертає готову таблицю, яку можна вставити в облікову програму. Те саме працює з візитками, бланками, скриншотами листування — усюди, де потрібно перевести «картинку з текстом» у дані. І весь процес іде на вашому комп’ютері: ні чек, ні паспорт, ні договір не потрапляють на чужі сервери.
LM Studio — графічна альтернатива: перетягуєте картинку в чат, і модель її розбирає. Зручно для разових задач без терміналу; тут же легко налаштувати вивантаження шарів на GPU, щоб запустити vision-модель навіть на відеокарті 8 ГБ.
llama.cpp напряму — для максимального контролю. Тут у vision-моделей є особливість: окрім самої моделі потрібен окремий файл mmproj (це і є той самий «перехідник» між зором і мовою) — без нього картинки працювати не будуть. Якщо використовуєте llama.cpp вручну, завантажте обидва файли й укажіть проектор прапором --mmproj:
llama-mtmd-cli -m model.gguf --mmproj mmproj.gguf --image ./photo.jpg -p "опиши зображення"
Типові помилки й рішення:
- Модель «не бачить» картинку — у llama.cpp забуто файл mmproj; завантажте його поряд із моделлю. В Ollama і LM Studio він підтягується сам.
- Нестача відеопам’яті при подачі фото — зображення роздуло контекст; зменшіть розширення картинки або візьміть модель легшу.
- Модель вигадує текст замість розпізнавання — типово для поганого скана; підвищте якість зображення або використайте класичний OCR для деградованих документів.
Налаштування під себе: розширення, контекст, API
У vision-моделей свої тонкощі налаштування.
- Розширення вхідних зображень — головний важіль. Що більша картинка, то більше візуальних токенів і відеопам’яті. Якщо вперлися в нестачу VRAM або модель працює повільно, насамперед зменшуйте розширення поданих зображень. Для OCR дрібного тексту, навпаки, розширення краще не занижувати.
- Довжина контексту. Картинка вже «з’їла» частину контекстного вікна сотнями токенів. Якщо задаєте довге текстове питання на додачу до зображення, вікно може переповнитися — стежте за
num_ctx. - Температура. Для OCR і фактичного опису ставте низьку (0.1–0.3): зору не потрібна «фантазія», а висока температура посилює галюцинації на картинках.
- Чіткий промпт. Vision-моделі краще відповідають на конкретний запит («витягни весь текст із цього чека у вигляді списку») і гірше — на розпливчастий («що тут?»). Що точніша задача, то менше вигадок.
Режим API. Через Ollama модель піднімає сервер на localhost:11434 у форматі OpenAI, і картинки передаються в запиті закодованими в base64. Це зручно для автоматизації: можна зібрати локальний сервіс, який пачкою обробляє скани або скриншоти, і при цьому жодне зображення не йде в хмару — для документообігу з персональними даними це і є головна цінність локального запуску.
Крихітні vision-моделі для агентів
Окремо варто сказати про «малюків», бо у 2026 році вони дивують. Moondream2 (близько 1,9 млрд параметрів) запускається на 4 ГБ і годиться як легке «око» для автоматизацій. MiniCPM-V у версії 4.6 ужалася до 1,3 млрд параметрів і працює навіть на телефонах (Android, iOS), а більша 2.6 за розміру близько 8 млрд за OCR конкурує з моделями вдвічі важчими — за оцінками спільноти (r/LocalLLaMA), її нерідко ставлять вище, ніж Llama 3.2 Vision 11B за співвідношенням якості й відеопам’яті.
Навіщо такі крихітні моделі? Для агентних сценаріїв, де зір — лише один із навичок. Легка VLM підключається як окремий інструмент: «подивися на скриншот і опиши, що бачиш», а основну логіку веде текстова модель. Це економить відеопам’ять і працює швидко. Якщо будуєте локального агента, який має іноді «дивитися» на екран чи документи, починати варто саме з MiniCPM-V або Moondream, а не з важкої 11B.
На практиці зв’язка виглядає так: користувач надсилає скриншот, легка VLM за частки секунди описує його текстом («вікно браузера з помилкою 404 на сторінці оплати»), а основна текстова модель уже ухвалює рішення, що робити далі. Зір тут — дешевий «датчик», а не головний рушій, і саме тому крихітної моделі достатньо. Такий підхід економить і відеопам’ять, і час відгуку, тому його все частіше застосовують у локальних асистентах.
Порівняння: коли що обрати
«Найкращої vision-моделі взагалі» не існує — вибір залежить від задачі, мови й заліза. Ось орієнтир (станом на червень 2026).Задача / умова Рекомендація OCR документів, у т.ч. українською/російською Qwen2.5-VL 7B Слабке залізо (4–8 ГБ VRAM) MiniCPM-V або Moondream Опис зображень англійською Llama 3.2 Vision, LLaVA-NeXT Діаграми й таблиці Pixtral 12B, Qwen2.5-VL Одна модель «на все» (текст + картинки) Gemma або Qwen3 (див. їхні огляди) Агент з епізодичним зором Moondream + текстова LLM
Якщо коротко: для більшості практичних задач (особливо OCR нашими мовами) беріть Qwen2.5-VL 7B, якщо вистачає 16 ГБ відеопам’яті. На скромному залізі — MiniCPM-V. Для агентів — зв’язку з крихітною моделлю.
І ще один орієнтир за навантаженням. Якщо задача разова (раз на день описати пару картинок), підійде майже будь-яка модель із таблиці — беріть ту, що влазить у вашу відеопам’ять. Якщо ж зір потрібен постійно й пачками (потік сканів, моніторинг скриншотів), на перший план виходять швидкість і витрата пам’яті — і тоді вибір між легкою швидкою моделлю і важкою точною перетворюється на усвідомлений компроміс під ваше навантаження.
Ризики й граблі
- Галюцинації на зображеннях. Vision-модель може впевнено «побачити» те, чого немає, особливо на нечітких картинках. Для важливих задач (медицина, документи) перевіряйте вивід — модель помиляється так само переконливо, як і відповідає вірно.
- Поганий OCR деградованих сканів. На розмитому, рукописному чи зім’ятому тексті VLM схильні додумувати. Для таких випадків класичний OCR (Tesseract) буває надійніший; комбінуйте інструменти.
- Пастка VRAM. Розмір файлу оманливий — картинки вимагають значно більше відеопам’яті. Орієнтуйтеся на вимоги при інференсі, а не на вагу моделі.
- Розширення і VRAM. Що більше подаєте зображення, то більше пам’яті й часу йде. Не потрібно — зменшуйте розширення входу.
- Мовні обмеження. Не всі моделі однаково хороші в українській і російській: Llama Vision слабка в кирилиці, Qwen2.5-VL — сильна. Перевіряйте під свою мову.
- Не завжди потрібна саме VLM. Для чистого видобування тексту з якісного PDF класичний OCR (Tesseract, PaddleOCR) швидший і точніший. Vision-модель виправдана там, де потрібно ще й зрозуміти зображення — описати, відповісти на питання, розібрати структуру. Не стріляйте з VLM по простих задачах OCR.
- Перегрів за довгих сесій. Обробка зображень навантажує відеокарту — стежте за температурами на компактних збірках.
FAQ
Яка локальна vision-модель найкраще розпізнає текст українською? Qwen2.5-VL — вона лідирує за OCR (близько 95,7% на тесті DocVQA) і підтримує 29 мов, включно з українською та російською. Для розпізнавання документів нашими мовами це найкращий відкритий вибір. Llama 3.2 Vision у кирилиці помітно слабша.
Чому vision-модель вимагає більше відеопам’яті, ніж важить файл? Тому що зображення модель перетворює на сотні або тисячі «візуальних токенів», і всі вони займають пам’ять під час роботи. Наприклад, Llama 3.2 Vision 11B важить близько 7,8 ГБ на диску, але при роботі з картинками вимагає порядку 24 ГБ VRAM. Що вище розширення картинки, то більше пам’яті потрібно.
Чи можна запустити vision-модель на відеокарті 8 ГБ? Так — для цього є легкі моделі: Moondream (близько 4 ГБ) і MiniCPM-V. Вони поступаються великим у складних задачах, але відмінно справляються з базовим описом і OCR. Важкі моделі на кшталт Llama 3.2 Vision 11B на 8 ГБ цілком не помістяться.
Чим локальна vision-модель краща за хмарну для роботи з документами? Приватністю. Скани паспортів, договорів, медичних довідок при локальній обробці не покидають ваш комп’ютер — їх не бачить жоден сторонній сервіс. Для чутливих документів це вирішальний аргумент, заради якого варто потерпіти скромнішу порівняно з хмарою якість.
Чи варто використовувати vision-модель для розпізнавання рукописного тексту? З обережністю. Рукописний і погано відсканований текст — слабке місце таких моделей: вони схильні «додумувати» нерозбірливі місця. Для якісного друкованого тексту вони працюють добре, а для рукописного чи деградованих сканів класичний OCR-рушій (наприклад, Tesseract) часто виявляється надійнішим.
Скільки місця на диску й відеопам’яті займе vision-модель? По-різному: Moondream — близько 4 ГБ, MiniCPM-V — 4–8 ГБ, Qwen2.5-VL-7B — порядку 16 ГБ при роботі з картинками, Llama 3.2 Vision 11B — близько 24 ГБ. Важливо: орієнтуйтеся саме на відеопам’ять при інференсі, а не на розмір файлу — для vision-моделей вони сильно розходяться.
Чи можна підключити локальну vision-модель до свого скрипта чи бота? Так. Ollama піднімає локальний API у форматі OpenAI, і зображення передаються в запиті (у base64). Це дозволяє зібрати, наприклад, сервіс, який автоматично розпізнає текст із завантажених сканів або описує фотографії, — цілком на вашому залізі, без хмари й оплати за запити.
Які формати зображень розуміють vision-моделі? Стандартні растрові — JPEG, PNG, WebP і подібні. Їх можна подавати напряму файлом (в Ollama) або закодованими в base64 через API. Векторні формати (SVG) і багатосторінкові PDF зазвичай потрібно спершу перетворити на картинки — наприклад, відрендерити сторінки PDF у PNG, а вже їх подавати моделі.
Локальна vision-модель гірша за хмарну (GPT-4o, Gemini)? У складних задачах — так, флагманські хмарні моделі поки точніші, особливо на заплутаних зображеннях і рідкісних мовах. Але розрив скоротився: для OCR документів, опису фото й розбору скриншотів локальні Qwen2.5-VL і MiniCPM-V дають цілком робочу якість. Локальну беруть заради приватності й безкоштовності, хмарну — коли потрібна максимальна точність і не жаль надіслати картинку назовні.









