



Коротко (TL;DR)
Якщо у 2026 році запитати у спільноті r/LocalLLaMA, «що поставити локально», у відповіді майже напевно буде Qwen3 від Alibaba. За півтора року це сімейство тихо стало вибором за замовчуванням — і не через маркетинг, а через три конкретні речі, що зійшлися в одній моделі.
- Коротко (TL;DR)
- Чому Qwen3 — вибір за замовчуванням у 2026
- Сімейство Qwen3: хто є хто
- Thinking і Non-Thinking: два режими в одній моделі
- Скільки потрібно заліза: VRAM, кванти і швидкість
- Dense 32B чи MoE 30B-A3B: що обрати
- Apache 2.0 проти Llama Community License
- Українська і російська: де Qwen3 попереду
- Запуск: Ollama, LM Studio, llama.cpp, vLLM
- Налаштування під себе: контекст, міркування і режим API
- Qwen3 проти Llama, Gemma і Mistral
- Ризики й граблі: цензура та не тільки
- FAQ
- Вільна ліцензія Apache 2.0. На відміну від Llama, Qwen3 можна вбудовувати в комерційний продукт без порогів за кількістю користувачів і без особливих обмежень. Це знімає юридичний головний біль.
- Українська і російська — рідні. Qwen3 офіційно навчений на 119 мовах, і обидві наші мови явно перелічені у списку. За якістю української Qwen3 вважається найкращим серед відкритих моделей — це його сильний бік для нашої аудиторії.
- Два режими в одній моделі. Qwen3 вміє «думати» покроково для складних задач і відповідати миттєво для простих — перемикається однією командою. Не потрібно тримати окремо «швидку» та «розумну» версії.
Мінімальне залізо: модель Qwen3 8B у кванті Q4 вміщується у 8 ГБ відеопам’яті, а флагманські для дому 32B і MoE-варіант 30B-A3B заходять у 24 ГБ. Головний чесний мінус — політична цензура в готових (instruct) версіях: модель уникає гострих тем про Китай. Розберемо, коли це заважає, а коли ні.
Дані у статті актуальні на 16 червня 2026 року.
Чому Qwen3 — вибір за замовчуванням у 2026
Сильних відкритих моделей багато, але Qwen3 зібрав рідкісну комбінацію переваг, жодна з яких окремо не унікальна, а разом вони й дають «ефект дефолту».
По-перше, широка й логічна лінійка. Від 0,6 млрд параметрів для телефона до 235 млрд для сервера — під будь-яке залізо є свій розмір, і всі вони навчені за одним рецептом, тож перехід між ними передбачуваний.

По-друге, сильні результати в коді та математиці. Флагман Qwen3-235B-A22B набирає 85,7 на математичному бенчмарку AIME’24 і 70,7 на LiveCodeBench v5 (за технічним звітом Qwen, травень 2025). Важливе застереження: ці цифри — для найбільшої моделі в режимі міркувань, і локально таку не запустити (про причини нижче). Але й середні моделі Qwen3 у своїй вазі показують результати на рівні або вище за конкурентів.
По-третє, зріла екосистема: на платформі Ollama сімейство набрало 30,5 млн завантажень (за даними каталогу на червень 2026), а це означає готові кванти, інструкції й підтримку в усіх популярних бекендах.
Далі — за порядком: з чого складається сімейство, як працюють режими міркувань, що потрібно по залізу й де підводні камені.
Сімейство Qwen3: хто є хто
Qwen3 вийшов 29 квітня 2025 року і включає вісім відкритих моделей — шість «щільних» (dense) і дві на архітектурі «суміші експертів» (MoE). Передтренування йшло приблизно на 36 трильйонах токенів — майже вдвічі більше, ніж у минулого покоління Qwen2.5.Модель Тип Параметри Контекст Під яке залізо Qwen3 0.6B / 1.7B dense 0,6 / 1,7 млрд 32K Телефон, слабкий ПК, CPU Qwen3 4B dense 4 млрд 128K Відеокарта від 6–8 ГБ Qwen3 8B dense 8 млрд 128K 8 ГБ VRAM — робоча конячка Qwen3 14B dense 14 млрд 128K 12–16 ГБ VRAM Qwen3 30B-A3B MoE 30 млрд (3 активних) 128K 24 ГБ VRAM, швидка Qwen3 32B dense 32 млрд 128K 24 ГБ VRAM, максимум якості Qwen3 235B-A22B MoE 235 млрд (22 активних) 128K Сервер, не для дому
У моделей MoE у дужках — число активних параметрів: на кожен токен вмикається лише частина мережі (8 експертів зі 128). Це робить їх швидшими за «щільні» моделі того самого розміру, але в пам’ять усе одно вантажаться всі ваги — про це докладніше в розділі про залізо.
Окремо варто знати про еволюцію лінійки, інакше легко заплутатися. Після оригінального Qwen3 (квітень 2025) вийшли Qwen3-Next (вересень 2025), потім Qwen3.5 (лютий 2026) і Qwen3.6 (квітень 2026). Нові покоління розширили число мов до 201 і додали мультимодальність. Якщо вам потрібен максимум свіжості й робота із зображеннями — дивіться у бік Qwen3.5/3.6; якщо потрібна перевірена база з купою готових квантів — оригінальний Qwen3, як і раніше, відмінний вибір. Ліцензія Apache 2.0 в усіх поколінь однакова.
Thinking і Non-Thinking: два режими в одній моделі
Головна архітектурна фішка Qwen3 — гібридний режим міркувань. Та сама модель уміє працювати у двох режимах:
- Thinking Mode (режим міркування) — модель спершу покроково розмірковує (вивід обгорнутий у теги
<think></think>), а потім дає відповідь. Повільніше, але помітно точніше на математиці, коді та логіці. - Non-Thinking Mode (швидкий режим) — миттєва відповідь без видимих міркувань. Підходить для простих запитань, чату, переформулювання.
Перемикання — без перезавантаження моделі. У коді це параметр enable_thinking=True/False, а прямо в діалозі можна дописати до повідомлення команду /think або /no_think. Тобто для чорнового листування ви тримаєте модель у швидкому режимі, а на складній задачі вмикаєте міркування однією командою.
Практична тонкість, про яку мовчать туторіали: за даними дослідження (arXiv, жовтень 2025), Qwen3-8B у режимі /no_think усе одно іноді генерує внутрішні міркування — повністю «вимкнути мислення» вдається не завжди. На повсякденних задачах це непомітно, але якщо ви рахуєте токени в API-режимі, майте на увазі.
Ще один механізм — бюджет міркувань (thinking budget): можна обмежити, скільки токенів модель витрачає на роздуми. Коли ліміт досягнуто, вона примусово переходить до відповіді на основі того, що встигла обдумати. Зручно, коли потрібен баланс між швидкістю та якістю.
Скільки потрібно заліза: VRAM, кванти і швидкість
Це ядро статті. Як і інші локальні моделі, Qwen3 запускають у квантованому вигляді — зі стисненням ваг до 4–8 біт у форматі GGUF. Найходовіший квант — Q4_K_M: мінімальна втрата якості за максимальної економії пам’яті.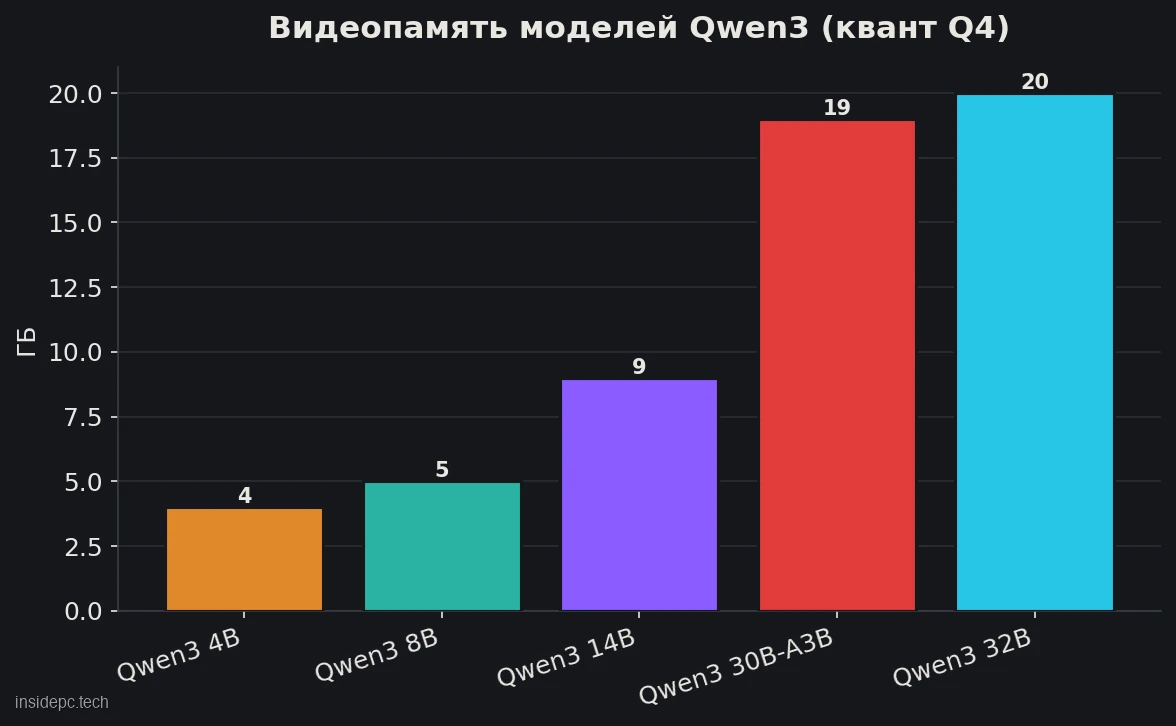
Ось скільки потрібно під кожну модель (розміри файлів — за каталогом Ollama, червень 2026; швидкість — за замірами спільноти на RTX 4090 і RX 7900 XTX, кванти вказані):Модель (Q4) Розмір файлу Комфортне залізо Швидкість* Qwen3 0.6B–4B ~1–4 ГБ 8 ГБ VRAM, 0.6B — навіть CPU дуже висока Qwen3 8B ~5 ГБ (файл) RTX 3060 8 ГБ і вище ~120+ tok/s (RTX 4090, 9B Q5) Qwen3 14B ~9 ГБ (файл) 12–16 ГБ VRAM висока Qwen3 30B-A3B ~19 ГБ (файл) 24 ГБ VRAM ~34 tok/s (RX 7900 XTX) Qwen3 32B ~20 ГБ (файл) 24 ГБ VRAM ~52 tok/s (RTX 4090, 27B Q4)
*Швидкість указана за замірами покоління Qwen3.5 (найближчого за розміром) на RTX 4090, окрім 30B-A3B (RX 7900 XTX); для оригінального Qwen3 результати близькі, але можуть відрізнятися. Розмір у стовпці — це файл моделі в каталозі Ollama, а не повна потреба у відеопам’яті.
Що це означає на практиці:
- 8 ГБ VRAM — ваш дім це Qwen3 8B у Q4_K_M. Відмінний універсал: чат, переклад, код, базова логіка.
- 12–16 ГБ VRAM — Qwen3 14B, помітний приріст якості, або 8B у високому кванті із запасом під контекст.
- 24 ГБ VRAM (RTX 3090/4090) — тут живуть обидва «домашні флагмани»: dense 32B і MoE 30B-A3B. Обидві в Q4 уміщуються у відеопам’ять цілком.
Важлива поправка про пам’ять: відеокарта витрачає її не лише на ваги, а й на KV-кеш під контекст діалогу. Розмір файлу моделі — це мінімум; під довгий контекст додайте ще кілька гігабайтів. Тому модель, яка за файлом влазить впритул, на вікні у 128K токенів може не запуститися.
І окрема грабля Ollama: за замовчуванням він обмежує контекст приблизно 40 тисячами токенів, навіть якщо модель підтримує 128K. Щоб задіяти повне вікно, явно задайте параметр num_ctx (наприклад, 131072) у чаті або в Modelfile — інакше довгі документи мовчки обрізатимуться.
Цифри швидкості — орієнтир: вони залежать від версії Ollama і llama.cpp, довжини контексту й кванта. Свіжі заміри під конкретну модель звіряйте на її сторінці в каталозі Ollama.
Dense 32B чи MoE 30B-A3B: що обрати
На 24 ГБ відеопам’яті у вас постає цікавий вибір між двома майже однаковими за «вагою» моделями — і більшість оглядів їх не порівнюють чесно. Ось суть.
- Qwen3 32B (dense) — задіює всі 32 млрд параметрів на кожен токен. Максимум якості у своєму класі, але повільніше: ~52 токени/с на RTX 4090.
- Qwen3 30B-A3B (MoE) — займає в пам’яті приблизно стільки ж (~19 ГБ проти ~20 ГБ), але на кожен токен активує лише 3 млрд параметрів із 30. Підсумок — помітно швидше й холодніше, за якості, близької до dense на багатьох задачах.
Просте правило: потрібна максимальна точність і не шкода швидкості — беріть dense 32B. Потрібен швидкий чуйний помічник під повсякденні задачі на тій самій карті — 30B-A3B часто приємніший у роботі. На залізі з обмеженим охолодженням (міні-ПК, ноутбук) MoE-варіант кращий через менше навантаження.
Apache 2.0 проти Llama Community License
Тут Qwen3 об’єктивно сильніший за головного конкурента. Усі відкриті моделі Qwen3 ідуть під ліцензією Apache 2.0 — однією з найвільніших. Що це дає на практиці:
- комерційне використання без порогів за кількістю користувачів;
- жодних роялті й обов’язкових погоджень із правовласником;
- право вбудовувати, модифікувати та поширювати модель, зокрема навчати на ній свої моделі.
Порівняйте з оглядом Llama: там діє Llama Community License з порогом у 700 млн користувачів на місяць, забороною вчити на виходах Llama інші моделі та обмеженнями для конкурентів. Для домашнього використання різниця непомітна, але якщо ви будуєте продукт — особливо з прицілом на масштаб або на навчання своєї моделі — Apache 2.0 у Qwen3 знімає цілий клас юридичних ризиків.Модель Ліцензія Поріг користувачів Навчати свої моделі на виходах Qwen3 Apache 2.0 немає можна Llama 4 / 3.x Llama Community 700 млн MAU не можна
Українська і російська: де Qwen3 попереду
Це наш головний information gain. Qwen3 офіційно підтримує 119 мов і діалектів, і в таблиці індоєвропейської групи офіційного блогу Qwen українська й російська перелічені явно. Це не «випадково розуміє», а заявлена підтримка з репрезентацією в навчальних даних.
На практиці це виводить Qwen3 в лідери відкритих моделей за якістю слов’янських мов. За відгуками спільноти r/LocalLLaMA і незалежними тестами саме Qwen3 регулярно називають найкращою відкритою моделлю для україно- та російськомовних задач, тоді як у Llama ці мови взагалі не входять до офіційно підтримуваних. Для текстів, перекладу та діалогу українською або російською Qwen3 — найрозумніший локальний вибір.
Якщо вам потрібен ще ширший обхват мов, нові покоління Qwen3.5 і Qwen3.6 розширили список до 201 мови. Але й оригінального Qwen3 з його 119 мовами для української та російської більш ніж достатньо.
Практична порада: навіть на сильному в українській Qwen3 не нехтуйте системним промптом із явним указанням мови та стилю — це прибирає рідкісні зіслизання в англійську на технічних термінах і робить відповіді стабільнішими. А для перекладу, редактури й сумаризації українських і російських текстів локального Qwen3 8B часто достатньо, щоб повністю відмовитися від хмарних сервісів: якість прийнятна, дані не покидають комп’ютер, а платити за токени не потрібно.
Запуск: Ollama, LM Studio, llama.cpp, vLLM
Під капотом — усе той самий рушій llama.cpp, поверх якого працюють зручні обгортки. Вибір залежить від сценарію.
Ollama — найпростіший старт. Модель завантажується й запускається однією командою (перевірено за каталогом Ollama, червень 2026):
ollama run qwen3:8b # робоча конячка, 8 ГБ VRAM
ollama run qwen3:14b # середній клас
ollama run qwen3:30b # MoE 30B-A3B, швидка на 24 ГБ
ollama run qwen3:32b # dense, максимум якості на 24 ГБ
Ollama одразу піднімає локальний API, сумісний із форматом OpenAI, — зручно для підключення до редакторів коду й ботів. Не забудьте про num_ctx, якщо потрібен довгий контекст (див. розділ про залізо).
LM Studio — графічний інтерфейс із каталогом моделей і повзунками налаштувань, включно з перемикачем режиму міркувань. Хороший вибір, якщо не любите термінал.
vLLM і SGLang — для продуктивного інференсу й серверних сценаріїв. Тут режим міркувань вмикається явним прапором, наприклад (потрібен vLLM не нижче 0.8.4):
vllm serve Qwen/Qwen3-30B-A3B --enable-reasoning --reasoning-parser deepseek_r1
Версії фреймворків швидко змінюються — перед запуском звіряйтеся з актуальною документацією Qwen.
Якщо плануєте докуповувати відеокарту під Qwen3, орієнтуйтеся на обсяг VRAM — докладний розбір у гіді з вибору GPU для ШІ.
Налаштування під себе: контекст, міркування і режим API
Після встановлення Qwen3 варто підлаштувати під свої задачі. Ключові параметри:
- Довжина контексту (num_ctx). Головне налаштування для Qwen3: модель тримає 128K токенів, але Ollama за замовчуванням дає лише ~40K. Для довгих документів піднімайте
num_ctxвручну — пам’ятаючи про витрату відеопам’яті на KV-кеш. - Режим міркувань. Тримайте модель у швидкому режимі (
/no_think) для чату і перемикайте в/thinkна складних задачах — це заощаджує час і токени там, де покрокові міркування не потрібні. - Температура. Загальноприйняті орієнтири спільноти: для коду та фактичних задач — 0.1–0.3, для вільного тексту — 0.6–0.8. У режимі міркувань температуру краще не задирати, щоб ланцюжок думки лишався зв’язним.
- Системний промпт. Для української та російської явна інструкція відповідати потрібною мовою покращує результат, хоча Qwen3 і так сильний у цих мовах.
В Ollama параметри задаються на льоту (/set parameter num_ctx 32768) або через Modelfile, де базова модель, системний промпт і налаштування фіксуються в один свій варіант командою ollama create.
Режим API — чому локальний Qwen3 зручний у роботі. Ollama одразу піднімає сервер на localhost:11434 з інтерфейсом, сумісним з OpenAI. Будь-який інструмент, розрахований на ChatGPT через API, перемикається на локальний Qwen3 зміною адреси. Так його підключають до:
- редакторів коду й плагінів автодоповнення;
- Telegram- і Discord-ботів;
- скриптів на Python через стандартну бібліотеку OpenAI;
- систем RAG і обробки документів.
Усі дані при цьому лишаються на вашому комп’ютері, а за токени платити не потрібно. І окремий плюс саме Qwen3: завдяки ліцензії Apache 2.0 результати його роботи можна використовувати в комерційних продуктах без огляду на обмеження.
Qwen3 проти Llama, Gemma і Mistral
«Найкращої моделі взагалі» не буває. Ось чесне порівняння Qwen3 з трьома головними суперниками в локальному сегменті (станом на червень 2026).Критерій Qwen3 Llama Gemma Mistral Small Українська/російська Найкращий Середньо Добре Середньо Код і математика Дуже добре Добре Дуже добре Добре Ліцензія Apache 2.0 Community (пороги) Apache 2.0 Apache 2.0 Режим міркувань Вбудований (гібрид) Немає (окремі моделі) Частково Частково Цензура політики Є (в instruct) Мінімальна Мінімальна Мінімальна Екосистема / кванти Дуже велика Найбільша Велика Середня
Де Qwen3 об’єктивно попереду: слов’янські мови, вільна ліцензія і вбудований гібридний reasoning. Де варто обрати інакше: якщо для вас критична свобода від будь-якої політичної цензури — у Llama, Gemma і Mistral її фактично немає (про це нижче); якщо потрібна максимально велика екосистема готових збірок — у Llama вона ширша.
Ризики й граблі: цензура та не тільки
- Політична цензура (головний чесний мінус). Готові (instruct) версії Qwen3 уникають гострих тем, пов’язаних із політикою Китаю, — це задокументовано і незалежними дослідженнями (arXiv, 2026), і аналізом на Hugging Face, і досвідом користувачів r/LocalLLaMA. Важливий нюанс: цензура додається на етапі тонкого налаштування, тому базові (Base) версії моделі практично вільні від неї — якщо фільтр вам заважає, беріть Base і донастроюйте під себе. На 99% задач розробки, перекладу й аналізу цензура не проявляється зовсім, але знати про неї потрібно.
- Витік міркувань у швидкому режимі. Як зазначено вище,
/no_thinkне завжди повністю вимикає роздуми — для економії токенів в API це варто перевіряти на своїх сценаріях. - Контекст Ollama за замовчуванням урізаний. Без явного
num_ctxдовгі документи мовчки обрізаються на ~40K токенів. - Плутанина версій. Qwen3, Qwen3-Next, Qwen3.5, Qwen3.6 — різні покоління з різними можливостями. Звіряйте точне ім’я моделі та її дату.
- Бенчмарки флагмана ≠ домашній досвід. Рекордні цифри (85,7 на AIME) належать моделі 235B у режимі міркувань; локально її не запустити — потрібен сервер. Орієнтуйтеся на результати тієї моделі, яка реально влазить у ваше залізо.
- MoE не економить відеопам’ять. 30B-A3B швидша, але в пам’ять вантажаться всі 30 млрд ваг — на 8 ГБ вона не запуститься, попри «3B активних».
- Перегрів за довгих сесій. Важкі моделі надовго навантажують відеокарту — стежте за температурами, особливо на компактних збірках.
FAQ
Яку модель Qwen3 обрати для відеокарти на 8 ГБ? Qwen3 8B у кванті Q4_K_M — оптимальний варіант: уміщується у 8 ГБ з робочим контекстом і добре тягне чат, переклад і код. Якщо потрібен запас під довгий контекст, беріть 4B у вищому кванті. Моделі 14B і більші на 8 ГБ уже не помістяться цілком.
Чи працює Qwen3 на процесорі без відеокарти? Так, найменші версії (0.6B і 1.7B) запускаються на CPU, хоч і повільно. Це годиться для легких задач і експериментів. Для комфортної роботи все ж потрібна відеокарта хоча б на 8 ГБ.
У чому різниця між Qwen3 і Qwen3.5/3.6? Qwen3 (квітень 2025) — перевірена база з величезним числом готових квантів. Qwen3.5 (лютий 2026) і Qwen3.6 (квітень 2026) — нові покоління з підтримкою 201 мови та мультимодальністю (робота із зображеннями). Для текстових задач українською оригінального Qwen3 достатньо; якщо потрібні картинки або максимум свіжості — беріть старші версії.
Як вимкнути режим міркувань в Ollama?
Допишіть до свого повідомлення команду /no_think — модель відповість без покрокових роздумів. Урахуйте, що за даними досліджень повне вимкнення працює не завжди: модель може генерувати частину міркувань навіть у швидкому режимі.
Чи сильно заважає цензура Qwen3 у звичайній роботі? Для розробки, перекладу, написання текстів і аналізу даних — практично ні: цензура стосується вузького кола політичних тем про Китай. Якщо ці теми важливі для ваших задач, використовуйте базову (Base) версію моделі замість instruct — вона майже вільна від фільтрів.
Qwen3 чи Llama — що брати для української мови? Qwen3. Українська й російська офіційно входять до його 119 мов, і за незалежними оцінками він лідирує серед відкритих моделей у слов’яномовних задачах, тоді як у Llama ці мови до офіційної підтримки не входять.
Скільки місця на диску займе Qwen3?
Залежить від моделі та кванта: Qwen3 8B у Q4 — близько 5 ГБ, 14B — близько 9 ГБ, а 32B і 30B-A3B — порядку 19–20 ГБ. Якщо плануєте тримати кілька моделей під різні задачі, закладайте 50–100 ГБ вільного місця. Ollama зберігає завантажені моделі у своїй папці (~/.ollama/models на Linux і macOS, C:\Users\<ім'я>\.ollama на Windows); змінити шлях можна змінною оточення OLLAMA_MODELS.
Як обрати модель під свою задачу та залізо серед інших варіантів — у загальному гіді з локальних LLM.









