Коротко (TL;DR)
Llama від Meta — найпопулярніше сімейство open-weight моделей у світі й одне з найбільш завантажуваних у каталозі Ollama. Для локального запуску це означає величезну екосистему, готові збірки під будь-який бекенд і безліч гайдів. Але перш ніж писати ollama run, варто розібратися в трьох речах, про які мовчить більшість оглядів.
- Коротко (TL;DR)
- Лінійка Llama у червні 2026: які версії існують і навіщо
- Скільки потрібно заліза: VRAM, кванти і швидкість
- MoE-пастка Scout: чому 17B «активних» займають пам’ять як 109B
- Як обрати версію під своє залізо
- Ліцензія Llama Community: що дозволено і де підступ
- Запуск: Ollama, LM Studio, llama.cpp
- Налаштування під себе: контекст, шари GPU і режим API
- Українська і російська: чесно про слабке місце Llama
- Llama проти Qwen3, Gemma і Mistral
- Для яких задач Llama локально хороша — а де ні
- Ризики й часті граблі
- FAQ
- Версій багато, і вони не рівнозначні. «Llama» сьогодні — це і крихітна 3.2 1B для телефона, і важка 3.3 70B, і Llama 4 Scout з унікальним контекстом 10 млн токенів. Вибір залежить не від номера версії, а від обсягу вашої відеопам’яті.
- Мінімальне залізо. Llama 3.1/3.2 8B у кванті Q4_K_M запускається на відеокарті з 8 ГБ VRAM і видає близько 95 токенів/с на RTX 4090 (за замірами SitePoint, червень 2026). Модель 3.3 70B уже вимагає ~40 ГБ під ваги, а Llama 4 Scout — щонайменше 24 ГБ VRAM навіть у стиснутому вигляді.
- Ліцензія не open-source. Llama Community License дозволяє комерційне використання, але містить поріг у 700 млн користувачів, заборону вчити на виходах Llama інші моделі та обмеження для конкурентів. Це важливо, якщо ви будуєте продукт.
Головний чесний висновок для українсько- та російськомовного читача: за якістю української та російської Llama поступається Qwen3 і Gemma. Якщо ваша основна мова — українська або російська, Llama варто брати усвідомлено, під конкретні задачі (довгий контекст, англомовний код, офлайн-бекенд), а не як «модель за замовчуванням».
Далі — таблиці VRAM і швидкості за всіма версіями, дерево вибору під ваше залізо, команди запуску й розбір підводних каменів.
Лінійка Llama у червні 2026: які версії існують і навіщо
За «Llama» ховається кілька поколінь з різною архітектурою. Ось що реально актуальне на середину 2026 року.
| Модель | Параметри | Контекст | Дата релізу | Для чого |
|---|---|---|---|---|
| Llama 3.2 1B / 3B | 1–3 млрд | 128K | кінець 2024 | Телефони, edge, швидкі чорнові задачі |
| Llama 3.1 8B | 8 млрд | 128K | 2024 | Базовий локальний чат і код, найкращий вхід |
| Llama 3.2 11B / 90B Vision | 11 / 90 млрд | 128K | кінець 2024 | Розпізнавання зображень (мультимодальність) |
| Llama 3.3 70B | 70 млрд | 128K | 6 грудня 2024 | Флагман «щільної» лінійки, якість близька до топу |
| Llama 4 Scout (17B-16E) | 17 млрд активних / 109 млрд усього | 10M | 5 квітня 2025 | Наддовгий контекст, MoE-архітектура |
| Llama 4 Maverick (17B-128E) | 17 млрд активних / 400 млрд усього | 1M | 5 квітня 2025 | Серверний клас, не для домашнього ПК |
Ключова різниця — між «щільними» (dense) моделями на кшталт 3.1 8B і 3.3 70B, де працюють усі параметри одразу, і MoE (сумішшю експертів) у Llama 4, де на кожен токен активується лише частина мережі. Про цю різницю — окремий розділ нижче, бо саме вона породжує головну оману щодо вимог до пам’яті.

Llama 3.2 1B і 3B — це «кишенькові» моделі для слабкого заліза й телефонів. Llama 3.1 8B лишається робочою конячкою локального ШІ: вміщується майже будь-куди, розуміє базову українську, годиться для чату й нескладного коду. Llama 3.3 70B — серйозний крок за якістю, але й за вимогами. А Llama 4 Maverick (400 млрд параметрів) для домашньої збірки нереалістична: їй потрібен мультисерверний стенд з кількома GPU, тому далі ми її не розглядаємо як локальний варіант.
Скільки потрібно заліза: VRAM, кванти і швидкість
Це ядро статті. Щоб запустити модель локально, її зазвичай квантують — стискають ваги з 16 біт до 4–8 біт, втрачаючи мінімум якості, але в рази заощаджуючи пам’ять. Найходовіший формат — GGUF (його розуміють Ollama, LM Studio і llama.cpp), а найпопулярніший рівень стиснення — Q4_K_M: оптимальний баланс «якість/розмір».
Наскільки кванти ужимають модель, видно на прикладі 70B (дані SitePoint, актуальні на 2026 рік):Квант Розмір файлу 70B Якість FP16 (без стиснення) ~140 ГБ Еталон Q8_0 ~70 ГБ Втрати непомітні Q6_K ~54 ГБ Дуже висока Q5_K_M ~46 ГБ Висока Q4_K_M ~40 ГБ Найкращий баланс Q3_K_M ~33 ГБ Помітна деградація Q2_K ~25 ГБ Тільки в крайньому разі
Буква в назві теж означає справу. Формати на кшталт Q4_K_M і Q4_K_S — це «K-кванти», розумне стиснення, де різні частини моделі ужимаються з різною точністю; суфікс _M (medium) дає трохи вищу якість, ніж _S (small), за близького розміру. Окрема гілка — i-кванти (IQ2, IQ3): вони жмуть ще агресивніше ціною більшого навантаження на процесор і виручають, коли модель зовсім не вміщується. Практичне правило: якщо файл влазить у відеопам’ять — беріть Q4_K_M; не вистачає пари гігабайтів — пробуйте Q3_K_M або IQ-кванти й тільки потім жертвуйте розміром самої моделі.
А ось головна таблиця — що реально потрібно і якої швидкості чекати. Цифри VRAM і tok/s — за замірами SitePoint і спільноти на квантизації Q4, станом на червень 2026; на вашій конфігурації вони відрізнятимуться.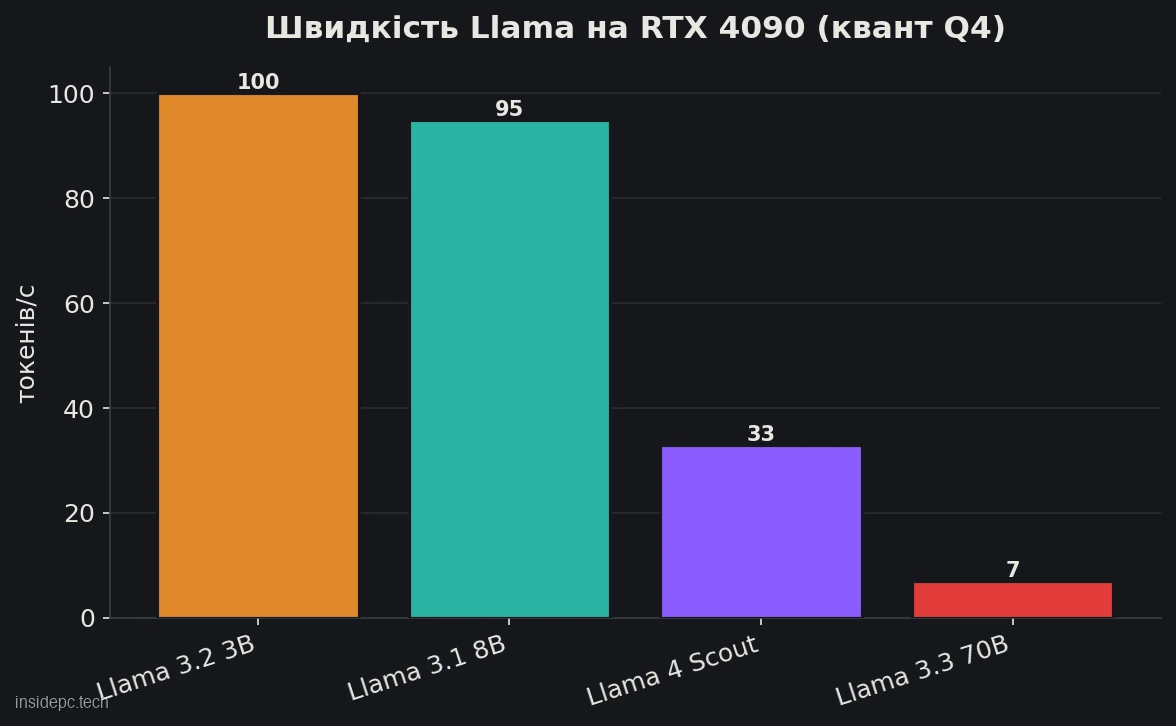
Модель (Q4) Мінімум VRAM Комфортне залізо Швидкість Llama 3.2 3B ~3 ГБ Будь-яка карта від 6 ГБ 100+ tok/s Llama 3.1 8B ~4–5 ГБ RTX 3060 8 ГБ і вище ~95 tok/s (RTX 4090), ~42 tok/s (M4 Pro) Llama 3.3 70B ~40 ГБ (файл) 2× 24 ГБ або 48+ ГБ; на 24 ГБ — з вивантаженням у RAM ~5–10 tok/s (RTX 4090 + RAM), швидше на 48 ГБ Llama 4 Scout ~55 ГБ (Q4_K_M); від ~24 ГБ (1.78-bit) RTX 3090/4090 24 ГБ і вище ~33 tok/s (RTX 4090, Q4)
Ці цифри — орієнтир, а не гарантія: швидкість залежить від версії Ollama і llama.cpp, довжини контексту й фонового навантаження. Свіжі заміри під конкретну модель звіряйте на її сторінці в каталозі Ollama і в обговореннях r/LocalLLaMA — це перше, що змінюється від місяця до місяця.
Що звідси випливає на практиці:
- 8 ГБ VRAM (RTX 3060/3070) — ваша стеля Llama 3.1 8B у Q4_K_M з контекстом близько 8K і запасом під робочий цикл. Цього вистачає для чату, перекладу й простого коду.
- 24 ГБ VRAM (RTX 3090/4090) — можна замахнутися на 70B, але без повного розміщення у відеопам’яті: частина ваг піде в системну ОЗП, і швидкість впаде до 5–10 токенів/с. Прийнятно для нечастих важких задач, некомфортно для живого діалогу.
- 48 ГБ і більше (дві карти по 24 ГБ або професійний прискорювач) — 70B розміщується цілком і працює швидко. Це вже територія окремих збірок: як зібрати таку систему, ми розбираємо в матеріалі про збірку AI-станції на Ryzen AI Max+ 395.
Якщо ви лише обираєте відеокарту під нейромережі, відштовхуйтеся від обсягу VRAM, а не від ігрового рейтингу — докладний розбір у гіді з вибору GPU для ШІ.
Важлива поправка: відеопам’ять витрачається не лише на ваги моделі, а й на KV-кеш — пам’ять під контекст діалогу. Що довше вікно, то більше йде понад розмір моделі. На практиці до розміру файлу варто додавати запас: для 8B з контекстом 8K — близько гігабайта, для вікон на десятки тисяч токенів — кілька гігабайтів. Тому модель, яка «за розміром файлу» влазить впритул, на довгому контексті може впасти з нестачею пам’яті. Зіткнулися з цим — спершу скорочуйте контекст, а не квант: від урізаного вікна якість страждає менше, ніж від грубшого стиснення ваг.
MoE-пастка Scout: чому 17B «активних» займають пам’ять як 109B
Найчастіша омана щодо Llama 4 звучить так: «Scout — це 17 млрд параметрів, отже, він легкий». Це неправильно, і ось чому.
Scout побудований на архітектурі MoE (Mixture of Experts, суміш експертів): усередині 16 «експертів», але на кожен токен вмикається лише один блок — ті самі 17 млрд активних параметрів. Заощадження тут — у обчисленнях: модель «думає» швидко, як невелика. Але всі 109 млрд ваг мають бути завантажені в пам’ять цілком, бо заздалегідь невідомо, який експерт знадобиться на наступному кроці.
Аналогія: уявіть бібліотеку, де читач за раз відкриває 17 книжок зі 109. Швидкість читання — як у 17 книжок, але всі 109 зобов’язані стояти на полицях і займати місце. MoE заощаджує ваш час, а не площу складу.
Практичний підсумок: попри «17B» у назві, Scout вимагає близько 24 ГБ VRAM навіть у сильно стиснутому вигляді (1.78-bit; за стандартного Q4_K_M файл займає помітно більше — близько 55 ГБ) і не запуститься там, де живе Llama 3.1 8B. Зате за ці вимоги ви отримуєте те, чого немає в жодної іншої локальної моделі, — вікно контексту на 10 млн токенів.
Як обрати версію під своє залізо
Звести все до простого правила можна через обсяг відеопам’яті. Рухайтеся згори вниз до першого рядка, який вам підходить.
- 4–6 ГБ VRAM або слабкий ноутбук. Беріть Llama 3.2 3B (Q4_K_M). Для важких задач не годиться, але як швидкий помічник і для чернеток — цілком.
- 8–12 ГБ VRAM. Llama 3.1 8B у Q4_K_M — оптимум. Базова українська, англійський код, переклад, сумаризація. Це та модель, з якої варто почати знайомство з локальним ШІ.
- 16 ГБ VRAM. Та сама 8B, але в Q6_K або Q8_0 (вища якість), або запас під більший контекст. На 70B усе ще мало — зате на цей обсяг метять і конкуренти на кшталт Qwen3 14B або Gemma 3 12B (див. порівняння нижче).
- 24 ГБ VRAM. Розвилка. Або Llama 3.3 70B у Q4 з вивантаженням частини ваг у ОЗП (повільно, але якісно), або Llama 4 Scout, якщо вам потрібен наддовгий контекст. Для повсякденного швидкого чату комфортніше лишитися на 8B у високому кванті.
- 48 ГБ і більше. Llama 3.3 70B цілком у Q4/Q5 на прийнятній швидкості — найкращий локальний досвід «щільної» Llama.
Окремо — про мультимодальність. Якщо задача не текст, а зображення (описати скриншот, витягти текст із фотографії документа, розібрати діаграму), потрібна не звичайна модель, а Llama 3.2 Vision — вона буває у версіях 11B і 90B. Запускається так само просто: ollama run llama3.2-vision, після чого моделі можна передати картинку разом із запитанням. За вимогами 11B-версія близька до моделей середнього розміру й працює на одній відеокарті від 12 ГБ; 90B — уже серверний клас. Це зручний локальний інструмент для приватної роботи з документами: ні скриншоти, ні скани договорів не йдуть на чужий сервер.
Ліцензія Llama Community: що дозволено і де підступ
Тут Llama програє конкурентам, і про це рідко пишуть українською. Ваги Llama поширюються під Llama Community License — це не open-source ліцензія в розумінні OSI (Open Source Initiative). Юридичний розбір WCR.Legal прямо називає три обмеження, яких немає в по-справжньому вільних ліцензіях:
- Поріг 700 млн користувачів. Якщо у вашого продукту на базі Llama більше ніж 700 млн активних користувачів на місяць, потрібно окремо запитувати ліцензію в Meta — і компанія видає її «на свій розсуд». Для більшості це теоретична межа, але для великого бізнесу — реальний бар’єр.
- Заборона вчити інші моделі на виходах Llama. Не можна використовувати відповіді Llama, щоб покращувати чи дистилювати сторонню модель. Це б’є по розробниках, які будують власні ШІ-продукти.
- Обмеження для конкурентів. Ліцензія закриває низку сценаріїв використання для прямих конкурентів Meta.
Порівняйте з головними суперниками — Gemma від Google і Qwen від Alibaba йдуть під Apache 2.0, максимально пермісивною ліцензією без подібних застережень.Модель Ліцензія Комерційне використання Особливі обмеження Llama 4 / 3.x Llama Community License Так, до 700 млн MAU Заборона вчити інші моделі, обмеження конкурентів Gemma (Google) Apache 2.0 Так Немає порогів і заборон на дистиляцію Qwen (Alibaba) Apache 2.0 Так Немає порогів і заборон на дистиляцію
Для домашнього використання й навчання це не має значення — запускайте вільно. Але якщо ви робите комерційний продукт, особливо з прицілом на масштаб або на навчання своєї моделі, ліцензія Llama додає юридичних ризиків, яких у Gemma і Qwen немає.
Запуск: Ollama, LM Studio, llama.cpp
Під капотом у більшості локальних рішень лежить рушій llama.cpp. Поверх нього виросли зручні обгортки. Вибір залежить від того, що вам ближче — командний рядок, графічний інтерфейс чи максимальний контроль.
Спершу модель потрібно завантажити. Найпростіший шлях — Ollama: він сам тягне потрібний квант зі свого каталогу за командою запуску, реєструвати нічого не треба. Якщо берете ваги напряму з Hugging Face, врахуйте — репозиторії Meta «закриті» (gated): потрібно завести акаунт і прийняти умови Llama Community License прямо на сторінці моделі, після чого доступ відкривається зазвичай за кілька хвилин. Розміри завантажень відчутні: 8B у Q4 — близько 4–5 ГБ, 70B у Q4 — близько 40 ГБ, тож заздалегідь звільніть місце на диску.
Ollama — найпростіший шлях. Це CLI-інструмент, що став стандартом де-факто: його репозиторій перевалив за 100 тис. зірок на GitHub. Встановлення моделі й запуск — однією командою (перевірено на актуальних сторінках каталогу Ollama, червень 2026):
ollama run llama3.1:8b # базовий вхід, 8B
ollama run llama3.2:3b # легка модель для слабкого заліза
ollama run llama3.3:70b # флагман, потрібно 40+ ГБ під ваги
ollama run llama4:scout # Llama 4 Scout (Maverick — llama4:maverick)
Ollama одразу піднімає локальний API, сумісний із форматом OpenAI, — це зручно для підключення до редакторів коду, ботів і власних скриптів.
LM Studio — якщо вам ближчий графічний інтерфейс. Візуальний каталог моделей, повзунки налаштувань (контекст, кількість шарів на GPU, температура), вбудований чат. Хороший вибір для тих, хто не хоче працювати в терміналі.
llama.cpp напряму — для максимальної продуктивності й тонкого налаштування. На легкій 8B різниця з Ollama невелика, але на Scout і 70B ручне керування вивантаженням шарів і параметрами здатне помітно підняти швидкість. Це шлях для просунутих користувачів.
Порада щодо типової помилки: якщо модель «не вміщується» і система починає гальмувати або вилітає з нестачею пам’яті, знижуйте або квант (з Q5 на Q4_K_M), або довжину контексту — саме контекст непомітно з’їдає відеопам’ять, особливо на моделях із великим вікном.
Налаштування під себе: контекст, шари GPU і режим API
Після встановлення модель майже завжди хочеться підлаштувати. Ось параметри, що впливають на результат найсильніше.
- Довжина контексту (num_ctx). За замовчуванням Ollama нерідко ставить скромні 2048–4096 токенів, хоча модель уміє більше. Працюєте з довгими текстами — піднімайте, але пам’ятайте: контекст лінійно їсть відеопам’ять. На 8 ГБ VRAM реалістична стеля для 8B — близько 8K токенів.
- Шари на GPU (num_gpu). Скільки шарів моделі йде у відеопам’ять, а скільки рахується на процесорі. Більше на GPU — швидше, але й VRAM потрібно більше. Уперлися в нестачу пам’яті — зменшіть це число: модель стане повільнішою, але запуститься.
- Температура. Відповідає за «творчість» відповіді. Для фактичних задач (переклад, код, видобування даних) ставте 0.1–0.3, для вільної генерації тексту — 0.7–0.8.
- Системний промпт. Для української це особливо важливо: явна інструкція «Відповідай лише українською мовою, грамотно й без англіцизмів» помітно покращує вивід Llama, яка за замовчуванням тяжіє до англійської.
В Ollama параметри задаються на льоту в чаті (/set parameter num_ctx 8192) або через файл Modelfile, де базова модель, системний промпт і налаштування фіксуються в одному місці, а потім збираються у свій варіант командою ollama create.
Режим API — головна перевага локального запуску. Ollama одразу піднімає сервер на localhost:11434 з інтерфейсом, сумісним з OpenAI. Майже будь-який інструмент, що вміє працювати з ChatGPT через API, можна переключити на локальну Llama, змінивши адресу сервера. Так підключають:
- редактори коду (розширення для VS Code, плагіни автодоповнення);
- Telegram- і Discord-ботів;
- власні скрипти на Python через стандартну бібліотеку OpenAI;
- інструменти для RAG і роботи з документами.
Саме режим API перетворює локальну модель з іграшки на робочий інструмент: дані не йдуть у хмару, платити за токени не потрібно, а інтеграція займає хвилини.
Українська і російська: чесно про слабке місце Llama
Це наш головний information gain — те, чого немає в англомовних оглядах. Українська і російська офіційно не входять до переліку підтримуваних мов Llama 4. У картці моделі Scout на Hugging Face перелічено рівно 12 мов: арабська, англійська, французька, німецька, гінді, індонезійська, італійська, португальська, іспанська, тагальська, тайська і в’єтнамська. Української та російської в списку немає, хоча передтренування, за даними Meta, велося на 200 мовах — тобто модель українську «бачила», але не оптимізована під неї.
На практиці це означає: Llama 4 українською працює помітно гірше, ніж англійською, і гірше, ніж конкуренти, заточені під мультимовність. За незалежними оцінками (SiliconFlow, рейтинг open-source моделей, 2026), у трійці найкращих для слов’яномовних задач — дві версії Qwen3 і лише потім Llama 3.1 8B. Тобто Llama потрапляє в топ, але як третій вибір, а не перший.
Висновок для нашої аудиторії прямий: якщо основна мова — українська або російська, для чату й текстів беріть Qwen3 або Gemma. Llama 3.1 8B прийнятна для базової мови, але не показує найкращий результат. А ось для англомовного коду, довгих документів і офлайн-сценаріїв Llama, як і раніше, сильна незалежно від мови інтерфейсу.
Llama проти Qwen3, Gemma і Mistral
«Найкращої моделі взагалі» не буває — є найкраща під задачу. Ось чесне порівняння Llama з трьома головними суперниками в локальному сегменті (станом на червень 2026).Критерій Llama Qwen3 Gemma Mistral Small Українська/російська Середньо (3-тє місце) Найкраща Добре Середньо Англійський код Добре Дуже добре Дуже добре Добре Ліцензія Community (з порогами) Apache 2.0 Apache 2.0 Apache 2.0 Максимальний контекст 10M (Scout) до 128K+ великий великий Екосистема / гайди Найбільша Велика Велика Середня Мультимодальність Vision (3.2, Scout) є варіанти є обмеж. (3.1)
Де Llama об’єктивно попереду: розмір екосистеми (найбільше готових збірок, квантів та інструкцій) і унікальний контекст Scout на 10 млн токенів — жодна інша локальна модель стільки не тримає. Де відстає: слов’янські мови і кодинг — за незалежними (community) бенчмарками Codeforces ELO у Gemma 4 31B близько 2150 проти менш ніж 2000 у Scout. Це оцінки спільноти, а не офіційний лідерборд, тому ставтеся до них як до орієнтира, а не вироку.
Список претендентів на цьому не закінчується: влітку 2026 для локального запуску з’явилася ще відкрита німецька модель Soofi S 30B — розбираємо її архітектуру, ліцензію і на якому залізі вона реально працює вдома.
Для яких задач Llama локально хороша — а де ні
Беріть Llama, якщо вам потрібно:
- Наддовгий контекст. 10 млн токенів Scout — це аналіз цілої кодової бази за один прохід, довгі юридичні чи медичні документи, RAG без нарізання на шматки. Унікальний сценарій, заради якого Scout і варто ставити.
- Офлайн-бекенд «про всяк випадок». У спільноті r/LocalLLaMA навесні–влітку 2026 року помітний тренд — тримати Llama локально як резерв на випадок відключення хмарних сервісів (збої, геополітика, ліміти API). Llama з її екосистемою — природний кандидат на роль такого fallback-бекенда.
- Англомовний код і текст за середньої за розміром моделі й готовності екосистеми.
- Старт у локальному ШІ. Llama 3.1 8B — модель, на якій найпростіше навчитися: найбільше гайдів, найменше сюрпризів.
- Приватність і робота без інтернету. Усе, що ви надсилаєте локальній моделі, лишається на вашому комп’ютері: ні промпти, ні документи не йдуть у хмару. Для чутливих даних — медичних, юридичних, комерційних — це вирішальний аргумент. Локальна Llama працює повністю офлайн, без підписок і без лімітів на запити.
Не найкращий вибір, якщо:
- ваша основна мова — українська або російська (беріть Qwen3/Gemma);
- пріоритет — кодинг і математика (Gemma 4 і Qwen3 за незалежними тестами сильніші);
- ви будуєте комерційний продукт з прицілом на масштаб або навчання своєї моделі (ліцензія Apache 2.0 у конкурентів безпечніша).
Ризики й часті граблі
- Нестача VRAM (OOM). Найчастіша проблема. Модель не вміщується — система зависає або видає помилку пам’яті. Лікування: знизити квант (Q4_K_M замість Q5/Q8), зменшити довжину контексту, вивантажити частину шарів в ОЗП (ціною швидкості). Не намагайтеся запускати 70B на 8 ГБ — це не запрацює з прийнятною швидкістю.
- Плутанина версій. «Llama» без номера нічого не означає. Llama 3.2 1B і Llama 3.3 70B відрізняються в десятки разів за вимогами та якістю. Завжди звіряйте точне ім’я тегу перед завантаженням.
- Ілюзія «легкого» Scout. Через MoE здається, що 17B запуститься будь-де. Насправді потрібно 24 ГБ VRAM — див. розділ про MoE-пастку вище.
- Ліцензійні обмеження в комерційних продуктах — поріг MAU, заборона на навчання інших моделей. Для пет-проєкту неважливо, для бізнесу перевірте заздалегідь.
- Слабка українська. Не чекайте від Llama рівня Qwen3 у слов’яномовних задачах — це її відоме обмеження, а не дефект вашого налаштування.
- Перегрів за довгих сесій. Важкі моделі надовго навантажують відеокарту. Стежте за температурами в тривалих задачах — це вже питання охолодження й стабільності заліза, особливо на компактних збірках і ноутбуках.
FAQ
Чи потягне локальну Llama моя RTX 3060 на 8 ГБ? Так — Llama 3.1 8B у кванті Q4_K_M вміщується у 8 ГБ з контекстом близько 8K і запасом під робочий цикл. Це комфортний варіант для чату, перекладу й нескладного коду. Моделі 70B і Llama 4 Scout на 8 ГБ запустити не вийде.
Яку версію Llama обрати для української мови? Серед сімейства Llama — 3.1 8B, вона краще за інших дає раду з українською. Але чесно: для українсько- та російськомовних задач Qwen3 і Gemma загалом сильніші, бо ці мови офіційно не входять до підтримуваних мов Llama 4. Якщо мова критична, розгляньте їх насамперед.
Чи можна використовувати Llama в комерційному продукті? Так, ліцензія Llama Community це дозволяє — але із застереженнями. Безкоштовне використання діє до 700 млн активних користувачів на місяць; заборонено вчити на виходах Llama інші моделі та є обмеження для конкурентів Meta. Для більшості проєктів це не завада, але перед запуском бізнесу ліцензію варто прочитати.
Ollama чи LM Studio — що краще для старту? Ollama, якщо ви не боїтеся командного рядка: встановлення й запуск — однією командою, плюс одразу готовий API. LM Studio — якщо хочете графічний інтерфейс із каталогом моделей і повзунками налаштувань. Обидва працюють на одному рушії (llama.cpp), тож за якістю виводу різниці немає.
Навіщо потрібен контекст на 10 млн токенів у Llama 4 Scout? Щоб за один запит обробити величезний обсяг тексту без нарізання: цілу кодову базу, довгий документ, великий масив листування. Це єдина локальна модель із таким вікном. Але врахуйте: що довший контекст, то більше відеопам’яті йде під нього, і то нижча швидкість генерації.
Чим квант Q4_K_M відрізняється від Q8? Це ступінь стиснення ваг. Q8 майже не втрачає якості, але файл удвічі більший; Q4_K_M ужимає модель сильніше за мінімальної втрати якості й вважається оптимальним балансом для локального запуску. Починайте з Q4_K_M і переходьте на Q5/Q6, тільки якщо вистачає відеопам’яті й хочеться вичавити максимум.
Чи безпечно завантажувати моделі з Hugging Face та з Ollama?
Загалом так, якщо брати ваги з офіційних репозиторіїв Meta і перевірених каталогів (Ollama, авторитетні квантизатори на кшталт Unsloth або bartowski). Самі файли GGUF — це дані, а не виконуваний код. Ризик виникає зі старим форматом pickle (.bin/.pt) від невідомих авторів: він здатен нести шкідливе навантаження. Правило просте: завантажуйте моделі з офіційних джерел і віддавайте перевагу формату GGUF або safetensors.
Як обрати модель під свою задачу та залізо серед інших варіантів — у загальному гіді з локальних LLM.