



Коротко (TL;DR)
Llama от Meta — самое популярное семейство open-weight моделей в мире и одно из самых скачиваемых в каталоге Ollama. Для локального запуска это значит огромную экосистему, готовые сборки под любой бэкенд и тонну гайдов. Но прежде чем писать ollama run, стоит разобраться в трёх вещах, о которых молчит большинство обзоров.
- Коротко (TL;DR)
- Линейка Llama в июне 2026: какие версии существуют и зачем
- Сколько нужно железа: VRAM, кванты и скорость
- MoE-ловушка Scout: почему 17B «активных» занимают память как 109B
- Как выбрать версию под своё железо
- Лицензия Llama Community: что разрешено и где подвох
- Запуск: Ollama, LM Studio, llama.cpp
- Настройка под себя: контекст, слои GPU и режим API
- Русский и украинский: честно о слабом месте Llama
- Llama против Qwen3, Gemma и Mistral
- Для каких задач Llama локально хороша — а где нет
- Риски и частые грабли
- FAQ
- Версий много, и они не равнозначны. «Llama» сегодня — это и крошечная 3.2 1B для телефона, и тяжёлая 3.3 70B, и Llama 4 Scout с уникальным контекстом 10 млн токенов. Выбор зависит не от номера версии, а от вашей видеопамяти.
- Минимальное железо. Llama 3.1/3.2 8B в кванте Q4_K_M запускается на видеокарте с 8 ГБ VRAM и выдаёт около 95 токенов/с на RTX 4090 (по замерам SitePoint, июнь 2026). Это самый разумный вход. Модель 3.3 70B уже требует ~40 ГБ под веса, а Llama 4 Scout — минимум 24 ГБ VRAM даже в сжатом виде.
- Лицензия не open-source. Llama Community License разрешает коммерческое использование, но содержит порог в 700 млн пользователей, запрет учить на выходах Llama другие модели и ограничение для конкурентов. Это важно, если вы строите продукт.
Главный честный вывод для русско- и украиноязычного читателя: по качеству русского Llama уступает Qwen3 и Gemma. Если ваш основной язык — русский или украинский, Llama стоит брать осознанно, под конкретные задачи (длинный контекст, англоязычный код, оффлайн-бэкенд), а не как «модель по умолчанию».
Дальше — таблицы VRAM и скорости по всем версиям, дерево выбора под ваше железо, команды запуска и разбор подводных камней.
Линейка Llama в июне 2026: какие версии существуют и зачем
За «Llama» скрывается несколько поколений с разной архитектурой. Вот что реально актуально на середину 2026 года.

| Модель | Параметры | Контекст | Дата релиза | Для чего |
|---|---|---|---|---|
| Llama 3.2 1B / 3B | 1–3 млрд | 128K | конец 2024 | Телефоны, edge, быстрые черновые задачи |
| Llama 3.1 8B | 8 млрд | 128K | 2024 | Базовый локальный чат и код, лучший вход |
| Llama 3.2 11B / 90B Vision | 11 / 90 млрд | 128K | конец 2024 | Распознавание изображений (мультимодальность) |
| Llama 3.3 70B | 70 млрд | 128K | 6 декабря 2024 | Флагман «плотной» линейки, качество близко к топу |
| Llama 4 Scout (17B-16E) | 17 млрд активных / 109 млрд всего | 10M | 5 апреля 2025 | Сверхдлинный контекст, MoE-архитектура |
| Llama 4 Maverick (17B-128E) | 17 млрд активных / 400 млрд всего | 1M | 5 апреля 2025 | Серверный класс, не для домашнего ПК |
Ключевое различие — между «плотными» (dense) моделями вроде 3.1 8B и 3.3 70B, где работают все параметры сразу, и MoE (смесью экспертов) в Llama 4, где на каждый токен активируется лишь часть сети. Об этой разнице — отдельный раздел ниже, потому что именно она порождает главное заблуждение о требованиях к памяти.

Llama 3.2 1B и 3B — это «карманные» модели для слабого железа и телефонов. Llama 3.1 8B остаётся рабочей лошадкой локального ИИ: умещается почти куда угодно, понимает базовый русский, годится для чата и несложного кода. Llama 3.3 70B — серьёзный шаг по качеству, но и по требованиям. А Llama 4 Maverick (400 млрд параметров) для домашней сборки нереалистична: ей нужен мультисерверный стенд с несколькими GPU, поэтому дальше мы её не рассматриваем как локальный вариант.
Сколько нужно железа: VRAM, кванты и скорость
Это ядро статьи. Чтобы запустить модель локально, её обычно квантуют — сжимают веса с 16 бит до 4–8 бит, теряя минимум качества, но в разы экономя память. Самый ходовой формат — GGUF (его понимают Ollama, LM Studio и llama.cpp), а самый популярный уровень сжатия — Q4_K_M: оптимальный баланс «качество/размер».
Насколько кванты ужимают модель, видно на примере 70B (данные SitePoint, актуальны на 2026 год):Квант Размер файла 70B Качество FP16 (без сжатия) ~140 ГБ Эталон Q8_0 ~70 ГБ Потери незаметны Q6_K ~54 ГБ Очень высокое Q5_K_M ~46 ГБ Высокое Q4_K_M ~40 ГБ Лучший баланс Q3_K_M ~33 ГБ Заметная деградация Q2_K ~25 ГБ Только в крайнем случае
Буква в названии тоже значит дело. Форматы вида Q4_K_M и Q4_K_S — это «K-кванты», умное сжатие, где разные части модели ужимаются с разной точностью; суффикс _M (medium) даёт чуть выше качество, чем _S (small), при близком размере. Отдельная ветка — i-кванты (IQ2, IQ3): они жмут ещё агрессивнее ценой большей нагрузки на процессор и выручают, когда модель совсем не помещается. Практическое правило: если файл влезает в видеопамять — берите Q4_K_M; не хватает пары гигабайт — пробуйте Q3_K_M или IQ-кванты и только потом жертвуйте размером самой модели.
А вот главная таблица — что реально нужно и какой скорости ждать. Цифры VRAM и tok/s — по замерам SitePoint и сообщества на квантизации Q4, по состоянию на июнь 2026; на вашей конфигурации они будут отличаться.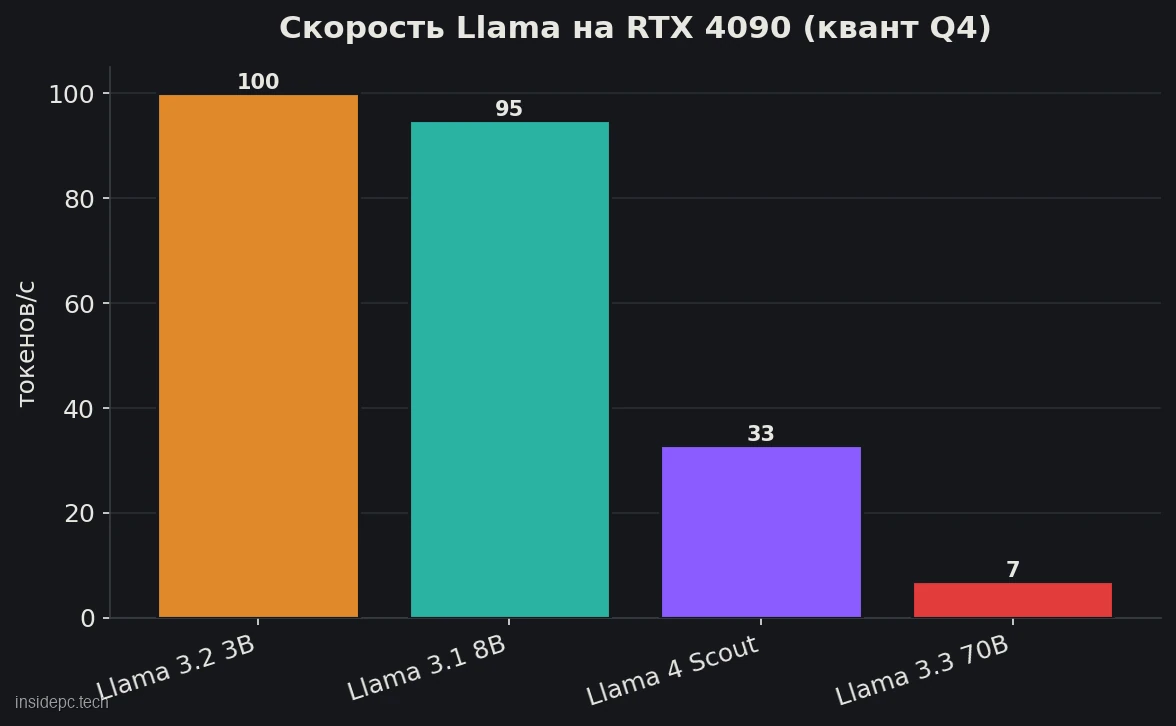
Модель (Q4) Минимум VRAM Комфортное железо Скорость Llama 3.2 3B ~3 ГБ Любая карта от 6 ГБ 100+ tok/s Llama 3.1 8B ~4–5 ГБ RTX 3060 8 ГБ и выше ~95 tok/s (RTX 4090), ~42 tok/s (M4 Pro) Llama 3.3 70B ~40 ГБ (файл) 2× 24 ГБ или 48+ ГБ; на 24 ГБ — с выгрузкой в RAM ~5–10 tok/s (RTX 4090 + RAM), быстрее на 48 ГБ Llama 4 Scout ~55 ГБ (Q4_K_M); от ~24 ГБ (1.78-bit) RTX 3090/4090 24 ГБ и выше ~33 tok/s (RTX 4090, Q4)
Эти цифры — ориентир, а не гарантия: скорость зависит от версии Ollama и llama.cpp, длины контекста и фоновой нагрузки. Свежие замеры под конкретную модель сверяйте на её странице в каталоге Ollama и в обсуждениях r/LocalLLaMA — это первое, что меняется от месяца к месяцу.

Что отсюда следует на практике:
- 8 ГБ VRAM (RTX 3060/3070) — ваш потолок Llama 3.1 8B в Q4_K_M с контекстом около 8K и запасом под рабочий цикл. Этого хватает для чата, перевода и простого кода.
- 24 ГБ VRAM (RTX 3090/4090) — можно замахнуться на 70B, но без полного размещения в видеопамяти: часть весов уйдёт в системную ОЗУ, и скорость упадёт до 5–10 токенов/с. Терпимо для нечастых тяжёлых задач, некомфортно для живого диалога.
- 48 ГБ и больше (две карты по 24 ГБ или профессиональный ускоритель) — 70B размещается целиком и работает быстро. Это уже территория отдельных сборок: как собрать такую систему, мы разбираем в материале про сборку AI-станции на Ryzen AI Max+ 395.
Если вы только выбираете видеокарту под нейросети, отталкивайтесь от объёма VRAM, а не от игрового рейтинга — подробный разбор в гиде по выбору GPU для ИИ.
Важная поправка: видеопамять расходуется не только на веса модели, но и на KV-кэш — память под контекст диалога. Чем длиннее окно, тем больше уходит сверх размера модели. На практике к размеру файла стоит добавлять запас: для 8B с контекстом 8K — около гигабайта, для окон на десятки тысяч токенов — несколько гигабайт. Поэтому модель, которая «по размеру файла» влезает впритык, на длинном контексте может упасть с нехваткой памяти. Столкнулись с этим — сначала сокращайте контекст, а не квант: от урезанного окна качество страдает меньше, чем от более грубого сжатия весов.
MoE-ловушка Scout: почему 17B «активных» занимают память как 109B
Самое частое заблуждение о Llama 4 звучит так: «Scout — это 17 млрд параметров, значит, он лёгкий». Это неверно, и вот почему.
Scout построен на архитектуре MoE (Mixture of Experts, смесь экспертов): внутри 16 «экспертов», но на каждый токен включается лишь один блок — те самые 17 млрд активных параметров. Экономия здесь — в вычислениях: модель «думает» быстро, как небольшая. Но все 109 млрд весов должны быть загружены в память целиком, потому что заранее неизвестно, какой эксперт понадобится на следующем шаге.
Аналогия: представьте библиотеку, где читатель за раз открывает 17 книг из 109. Скорость чтения — как у 17 книг, но все 109 обязаны стоять на полках и занимать место. MoE экономит ваше время, а не площадь склада.
Практический итог: несмотря на «17B» в названии, Scout требует около 24 ГБ VRAM даже в сильно сжатом виде (1.78-bit; при стандартном Q4_K_M файл занимает заметно больше — порядка 55 ГБ) и не запустится там, где живёт Llama 3.1 8B. Зато за эти требования вы получаете то, чего нет больше ни у одной локальной модели, — окно контекста на 10 млн токенов.
Как выбрать версию под своё железо
Свести всё к простому правилу можно через объём видеопамяти. Двигайтесь сверху вниз до первой строки, которая вам подходит.
- 4–6 ГБ VRAM или слабый ноутбук. Берите Llama 3.2 3B (Q4_K_M). Для тяжёлых задач не годится, но как быстрый помощник и для черновиков — вполне.
- 8–12 ГБ VRAM. Llama 3.1 8B в Q4_K_M — оптимум. Базовый русский, английский код, перевод, суммаризация. Это та модель, с которой стоит начать знакомство с локальным ИИ.
- 16 ГБ VRAM. Та же 8B, но в Q6_K или Q8_0 (выше качество), либо запас под больший контекст. На 70B всё ещё мало — зато на этот объём метят и конкуренты вроде Qwen3 14B или Gemma 3 12B (см. сравнение ниже).
- 24 ГБ VRAM. Развилка. Либо Llama 3.3 70B в Q4 с выгрузкой части весов в ОЗУ (медленно, но качественно), либо Llama 4 Scout, если вам нужен сверхдлинный контекст. Для повседневного быстрого чата комфортнее остаться на 8B в высоком кванте.
- 48 ГБ и больше. Llama 3.3 70B целиком в Q4/Q5 на приемлемой скорости — лучший локальный опыт «плотной» Llama.
Отдельно — про мультимодальность. Если задача не текст, а изображения (описать скриншот, извлечь текст с фотографии документа, разобрать диаграмму), нужна не обычная модель, а Llama 3.2 Vision — она бывает в версиях 11B и 90B. Запускается так же просто: ollama run llama3.2-vision, после чего модели можно передать картинку вместе с вопросом. По требованиям 11B-версия близка к моделям среднего размера и работает на одной видеокарте от 12 ГБ; 90B — уже серверный класс. Это удобный локальный инструмент для приватной работы с документами: ни скриншоты, ни сканы договоров не уходят на чужой сервер.
Лицензия Llama Community: что разрешено и где подвох
Здесь Llama проигрывает конкурентам, и об этом редко пишут по-русски. Веса Llama распространяются под Llama Community License — это не open-source лицензия в понимании OSI (Open Source Initiative). Юридический разбор WCR.Legal прямо называет три ограничения, которых нет в по-настоящему свободных лицензиях:
- Порог 700 млн пользователей. Если у вашего продукта на базе Llama больше 700 млн активных пользователей в месяц, нужно отдельно запрашивать лицензию у Meta — и компания выдаёт её «на своё усмотрение». Для большинства это теоретический предел, но для крупного бизнеса — реальный барьер.
- Запрет учить другие модели на выходах Llama. Нельзя использовать ответы Llama, чтобы улучшать или дистиллировать стороннюю модель. Это бьёт по разработчикам, которые строят собственные ИИ-продукты.
- Ограничение для конкурентов. Лицензия закрывает ряд сценариев использования для прямых конкурентов Meta.
Сравните с главными соперниками — Gemma от Google и Qwen от Alibaba идут под Apache 2.0, максимально пермиссивной лицензией без подобных оговорок.Модель Лицензия Коммерческое использование Особые ограничения Llama 4 / 3.x Llama Community License Да, до 700 млн MAU Запрет обучать другие модели, ограничение конкурентов Gemma (Google) Apache 2.0 Да Нет порогов и запретов на дистилляцию Qwen (Alibaba) Apache 2.0 Да Нет порогов и запретов на дистилляцию
Для домашнего использования и обучения это не имеет значения — запускайте свободно. Но если вы делаете коммерческий продукт, особенно с прицелом на масштаб или на обучение своей модели, лицензия Llama добавляет юридических рисков, которых у Gemma и Qwen нет.
Запуск: Ollama, LM Studio, llama.cpp
Под капотом у большинства локальных решений лежит движок llama.cpp. Поверх него выросли удобные обёртки. Выбор зависит от того, что вам ближе — командная строка, графический интерфейс или максимальный контроль.
Сначала модель нужно скачать. Самый простой путь — Ollama: он сам тянет нужный квант из своего каталога по команде запуска, регистрировать ничего не надо. Если берёте веса напрямую с Hugging Face, учтите — репозитории Meta «закрытые» (gated): нужно завести аккаунт и принять условия Llama Community License прямо на странице модели, после чего доступ открывается обычно за несколько минут. Размеры загрузок ощутимые: 8B в Q4 — около 4–5 ГБ, 70B в Q4 — порядка 40 ГБ, так что заранее освободите место на диске.
Ollama — самый простой путь. Это CLI-инструмент, ставший стандартом де-факто: его репозиторий перевалил за 100 тыс. звёзд на GitHub. Установка модели и запуск — одной командой (проверено на актуальных страницах каталога Ollama, июнь 2026):
ollama run llama3.1:8b # базовый вход, 8B
ollama run llama3.2:3b # лёгкая модель для слабого железа
ollama run llama3.3:70b # флагман, нужно 40+ ГБ под веса
ollama run llama4:scout # Llama 4 Scout (Maverick — llama4:maverick)
Ollama сразу поднимает локальный API, совместимый с форматом OpenAI, — это удобно для подключения к редакторам кода, ботам и собственным скриптам.
LM Studio — если вам ближе графический интерфейс. Визуальный каталог моделей, ползунки настроек (контекст, число слоёв на GPU, температура), встроенный чат. Хороший выбор для тех, кто не хочет работать в терминале.
llama.cpp напрямую — для максимальной производительности и тонкой настройки. На лёгкой 8B разница с Ollama невелика, но на Scout и 70B ручное управление выгрузкой слоёв и параметрами способно заметно поднять скорость. Это путь для продвинутых пользователей.
Совет по типичной ошибке: если модель «не помещается» и система начинает тормозить или вылетает с нехваткой памяти, снижайте либо квант (с Q5 на Q4_K_M), либо длину контекста — именно контекст незаметно съедает видеопамять, особенно на моделях с большим окном.
Настройка под себя: контекст, слои GPU и режим API
После установки модель почти всегда хочется подстроить. Вот параметры, которые влияют на результат сильнее всего.
- Длина контекста (num_ctx). По умолчанию Ollama нередко ставит скромные 2048–4096 токенов, хотя модель умеет больше. Работаете с длинными текстами — поднимайте, но помните: контекст линейно ест видеопамять. На 8 ГБ VRAM реалистичный потолок для 8B — около 8K токенов.
- Слои на GPU (num_gpu). Сколько слоёв модели уходит в видеопамять, а сколько считается на процессоре. Больше на GPU — быстрее, но и VRAM нужно больше. Упёрлись в нехватку памяти — уменьшите это число: модель станет медленнее, но запустится.
- Температура. Отвечает за «творческость» ответа. Для фактических задач (перевод, код, извлечение данных) ставьте 0.1–0.3, для свободной генерации текста — 0.7–0.8.
- Системный промпт. Для русского это особенно важно: явная инструкция «Отвечай только на русском языке, грамотно и без англицизмов» заметно улучшает вывод Llama, которая по умолчанию тяготеет к английскому.
В Ollama параметры задаются на лету в чате (/set parameter num_ctx 8192) либо через файл Modelfile, где базовая модель, системный промпт и настройки фиксируются в одном месте, а затем собираются в свой вариант командой ollama create.
Режим API — главное преимущество локального запуска. Ollama сразу поднимает сервер на localhost:11434 с интерфейсом, совместимым с OpenAI. Почти любой инструмент, умеющий работать с ChatGPT через API, можно переключить на локальную Llama, поменяв адрес сервера. Так подключают:
- редакторы кода (расширения для VS Code, плагины автодополнения);
- Telegram- и Discord-ботов;
- собственные скрипты на Python через стандартную библиотеку OpenAI;
- инструменты для RAG и работы с документами.
Именно режим API превращает локальную модель из игрушки в рабочий инструмент: данные не уходят в облако, платить за токены не нужно, а интеграция занимает минуты.
Русский и украинский: честно о слабом месте Llama
Это наш главный information gain — то, чего нет в англоязычных обзорах. Русский и украинский официально не входят в число поддерживаемых языков Llama 4. В карточке модели Scout на Hugging Face перечислены ровно 12 языков: арабский, английский, французский, немецкий, хинди, индонезийский, итальянский, португальский, испанский, тагальский, тайский и вьетнамский. Русского и украинского в списке нет, хотя предобучение, по данным Meta, велось на 200 языках — то есть модель русский «видела», но не оптимизирована под него.
На практике это значит: Llama 4 на русском работает заметно хуже, чем в английском, и хуже, чем конкуренты, заточенные под мультиязычность. По независимым оценкам (SiliconFlow, рейтинг open-source моделей для русского, 2026), в тройке лучших для русскоязычных задач — две версии Qwen3 и лишь затем Llama 3.1 8B. То есть Llama попадает в топ, но как третий выбор, а не первый.
Вывод для нашей аудитории прямой: если основной язык — русский или украинский, для чата и текстов берите Qwen3 или Gemma. Llama 3.1 8B приемлема для базового русского, но не показывает лучший результат. А вот для англоязычного кода, длинных документов и оффлайн-сценариев Llama по-прежнему сильна независимо от языка интерфейса.
Llama против Qwen3, Gemma и Mistral
«Лучшей модели вообще» не бывает — есть лучшая под задачу. Вот честное сравнение Llama с тремя главными соперниками в локальном сегменте (по состоянию на июнь 2026).Критерий Llama Qwen3 Gemma Mistral Small Русский/украинский Средне (3-е место) Лучший Хорошо Средне Английский код Хорошо Очень хорошо Очень хорошо Хорошо Лицензия Community (с порогами) Apache 2.0 Apache 2.0 Apache 2.0 Максимальный контекст 10M (Scout) до 128K+ большой большой Экосистема / гайды Крупнейшая Большая Большая Средняя Мультимодальность Vision (3.2, Scout) есть варианты есть огранич. (3.1)
Где Llama объективно впереди: размер экосистемы (больше всего готовых сборок, квантов и инструкций) и уникальный контекст Scout на 10 млн токенов — ни одна другая локальная модель столько не держит. Где отстаёт: русский язык и кодинг — по независимым (community) бенчмаркам Codeforces ELO у Gemma 4 31B около 2150 против менее 2000 у Scout. Это оценки сообщества, а не официальный лидерборд, поэтому относитесь к ним как к ориентиру, а не приговору.
Список претендентов на этом не заканчивается: летом 2026 для локального запуска появилась ещё открытая немецкая модель Soofi S 30B — разбираем её архитектуру, лицензию и на каком железе она реально работает дома.
Для каких задач Llama локально хороша — а где нет
Берите Llama, если вам нужно:
- Сверхдлинный контекст. 10 млн токенов Scout — это анализ целой кодовой базы за один проход, длинные юридические или медицинские документы, RAG без нарезки на куски. Уникальный сценарий, ради которого Scout и стоит ставить.
- Оффлайн-бэкенд «на всякий случай». В сообществе r/LocalLLaMA весной–летом 2026 года заметен тренд — держать Llama локально как резерв на случай отключения облачных сервисов (сбои, геополитика, лимиты API). Llama с её экосистемой — естественный кандидат на роль такого fallback-бэкенда.
- Англоязычный код и текст при средней по размеру модели и готовности экосистемы.
- Старт в локальном ИИ. Llama 3.1 8B — модель, на которой проще всего научиться: больше всего гайдов, меньше всего сюрпризов.
- Приватность и работа без интернета. Всё, что вы отправляете локальной модели, остаётся на вашем компьютере: ни промпты, ни документы не уходят в облако. Для чувствительных данных — медицинских, юридических, коммерческих — это решающий аргумент. Локальная Llama работает полностью оффлайн, без подписок и без лимитов на запросы.
Не лучший выбор, если:
- ваш основной язык — русский или украинский (берите Qwen3/Gemma);
- приоритет — кодинг и математика (Gemma 4 и Qwen3 по независимым тестам сильнее);
- вы строите коммерческий продукт с прицелом на масштаб или обучение своей модели (лицензия Apache 2.0 у конкурентов безопаснее).
Риски и частые грабли
- Нехватка VRAM (OOM). Самая частая проблема. Модель не помещается — система виснет или выдаёт ошибку памяти. Лечение: понизить квант (Q4_K_M вместо Q5/Q8), уменьшить длину контекста, выгрузить часть слоёв в ОЗУ (ценой скорости). Не пытайтесь запускать 70B на 8 ГБ — это не заработает с приемлемой скоростью.
- Путаница версий. «Llama» без номера ничего не значит. Llama 3.2 1B и Llama 3.3 70B отличаются в десятки раз по требованиям и качеству. Всегда сверяйте точное имя тега перед скачиванием.
- Иллюзия «лёгкого» Scout. Из-за MoE кажется, что 17B запустится где угодно. На деле нужно 24 ГБ VRAM — см. раздел про MoE-ловушку выше.
- Лицензионные ограничения в коммерческих продуктах — порог MAU, запрет на обучение других моделей. Для пет-проекта неважно, для бизнеса проверьте заранее.
- Слабый русский. Не ждите от Llama уровня Qwen3 в русскоязычных задачах — это её известное ограничение, а не дефект вашей настройки.
- Перегрев при долгих сессиях. Тяжёлые модели надолго нагружают видеокарту. Следите за температурами в продолжительных задачах — это уже вопрос охлаждения и стабильности железа, особенно на компактных сборках и ноутбуках.
FAQ
Потянет ли локальную Llama моя RTX 3060 на 8 ГБ? Да — Llama 3.1 8B в кванте Q4_K_M умещается в 8 ГБ с контекстом около 8K и запасом под рабочий цикл. Это комфортный вариант для чата, перевода и несложного кода. Модели 70B и Llama 4 Scout на 8 ГБ запустить не получится.
Какую версию Llama выбрать для русского языка? Среди семейства Llama — 3.1 8B, она лучше других справляется с русским. Но честно: для русско- и украиноязычных задач Qwen3 и Gemma в целом сильнее, потому что русский официально не входит в поддерживаемые языки Llama 4. Если язык критичен, рассмотрите их в первую очередь.
Можно ли использовать Llama в коммерческом продукте? Да, лицензия Llama Community это разрешает — но с оговорками. Бесплатное использование действует до 700 млн активных пользователей в месяц; запрещено обучать на выходах Llama другие модели и есть ограничения для конкурентов Meta. Для большинства проектов это не помеха, но перед запуском бизнеса лицензию стоит прочитать.
Ollama или LM Studio — что лучше для старта? Ollama, если вы не боитесь командной строки: установка и запуск — одной командой, плюс сразу готовый API. LM Studio — если хотите графический интерфейс с каталогом моделей и ползунками настроек. Обе работают на одном движке (llama.cpp), так что по качеству вывода разницы нет.
Зачем нужен контекст на 10 млн токенов у Llama 4 Scout? Чтобы за один запрос обработать огромный объём текста без нарезки: целую кодовую базу, длинный документ, большой массив переписки. Это единственная локальная модель с таким окном. Но учтите: чем длиннее контекст, тем больше видеопамяти уходит под него, и тем ниже скорость генерации.
Чем квант Q4_K_M отличается от Q8? Это степень сжатия весов. Q8 почти не теряет качества, но файл вдвое больше; Q4_K_M ужимает модель сильнее при минимальной потере качества и считается оптимальным балансом для локального запуска. Начинайте с Q4_K_M и переходите на Q5/Q6, только если хватает видеопамяти и хочется выжать максимум.
Безопасно ли скачивать модели с Hugging Face и из Ollama?
В целом да, если брать веса из официальных репозиториев Meta и проверенных каталогов (Ollama, авторитетные квантизаторы вроде Unsloth или bartowski). Сами файлы GGUF — это данные, а не исполняемый код. Риск возникает со старым форматом pickle (.bin/.pt) от неизвестных авторов: он способен нести вредоносную нагрузку. Правило простое: скачивайте модели из официальных источников и предпочитайте формат GGUF или safetensors.
Как выбрать модель под свою задачу и железо среди других вариантов — в общем гиде по локальным LLM.










