



Коротко (TL;DR)
NVIDIA DGX Spark — это компактная «коробка» с чипом GB10 Grace Blackwell и 128 ГБ единой памяти, в которую целиком грузятся модели, не помещающиеся в обычную видеокарту. По ёмкости это прямой конкурент мини-ПК на Ryzen AI Max+ 395 (Strix Halo): те же 128 ГБ, почти та же пропускная способность памяти (273 ГБ/с против 256 у Strix Halo).
Но покупать DGX Spark ради скорости — ошибка. Его главный лимит — та самая пропускная способность: на плотной модели Llama 70B он выдаёт около 4 токенов/с, а быстро бегут только компактные и MoE-модели (gpt-oss-120B — примерно 38–50 ток/с, по независимым замерам). За эти же деньги и Mac Studio, и сборка на видеокартах генерируют в разы быстрее.
Реальная ценность DGX Spark в другом — это девкит с полным программным стеком NVIDIA (DGX OS, CUDA, NIM, NemoClaw), точная копия архитектуры дата-центровых DGX в мини-формате. Вы платите $4 699 (на июнь 2026; на старте было $3 999) не за токены в секунду, а за то, чтобы прототип, обкатанный на столе, без переделок уехал на серверы H100. Ниже — что именно он тянет с цифрами, сколько стоит и с чем честно сравнивать.
(Данные актуальны на 15 июня 2026; цены и бенчмарки — с датами в тексте.)

Задача и бюджет
DGX Spark — это готовое устройство под две связанные задачи: локальный инференс открытых LLM (чат, код, RAG, агенты без облака) и прототипирование/дообучение моделей в нативной среде NVIDIA с прицелом на последующий перенос в дата-центр. Не его цель — выжимать максимум токенов в секунду за деньги: для этого есть дискретные GPU.

Бюджет — это цена одного бокса: $4 699 за Founders Edition (на июнь 2026). Память распаяна, графика интегрирована — вы покупаете готовый прибор с предустановленной ОС, а не собираете его по компонентам. Дальше всё решает софт.
Важная оговорка по ожиданиям: это не «локальный ChatGPT». Топовые облачные модели (Gemini, Claude, класс GPT-5) для такого устройства слишком велики — локально вы запускаете открытые модели (Llama, Qwen, gpt-oss, DeepSeek), а не их облачных конкурентов.
Что такое DGX Spark и чип GB10
NVIDIA позиционирует DGX Spark как «суперкомпьютер на стол». Ключевое железо:
- Чип: GB10 Grace Blackwell — 20-ядерный Arm (10× Cortex-X925 + 10× Cortex-A725) плюс GPU на архитектуре Blackwell с тензорными ядрами 5-го поколения.
- Память: 128 ГБ LPDDR5x, когерентная единая для CPU и GPU, шина 256-бит, пропускная способность 273 ГБ/с.
- Compute: до 1 PFLOP в FP4 — но это разреженный (sparse) FP4 и теоретический максимум; в реальных замерах MAMF чип выдаёт ~99,8 TFLOPs в BF16 и ~207,7 TFLOPs в FP8 (по данным StorageReview, 2025). «Один петафлоп» — маркетинговая цифра, реальный плотный compute примерно вдвое ниже пиковой.
- Накопитель и сеть: 4 ТБ NVMe с самошифрованием, сетевая карта ConnectX-7 на 200 Гбит/с, 10 GbE, Wi-Fi 7.
- Питание и габариты: блок 240 Вт (TDP самого чипа GB10 — 140 Вт), корпус 150×150×50,5 мм (~1,13 л), масса 1,2 кг, шум 35 дБ под нагрузкой.
Зачем нужна единая память. У обычной видеокарты фиксированная VRAM (16–32 ГБ), и модель, которая в неё не влезла, уходит в медленный режим с выгрузкой в системную память. DGX Spark, как и Strix Halo, стирает эту границу: CPU и GPU обращаются к одному пулу на 128 ГБ. Это позволяет держать в памяти модели до 200 млрд параметров — то, что не запустить ни на одной потребительской карте.
Что реально потянет
Главный вопрос — не «влезет ли», а «с какой скоростью». DGX Spark отлично читает промпт (prefill — стадия, где чип упирается в compute и он силён), но медленно генерирует ответ (decode — стадия, где всё решает пропускная способность памяти). Ниже — независимые замеры (llama.cpp от Георги Герганова и официальные тесты Ollama; данные октября 2025 — января 2026).Модель Параметры / квант Prefill, ток/с Decode, ток/с Llama 3.1 8B 8B Q4 ~7 600 ~38 gpt-oss-20B 20B MXFP4 (MoE) ~3 200–3 700 ~50–85 DeepSeek-R1 14B 14B Q4 ~5 900 ~20 gemma 3 27B 27B Q4 ~830 ~11 gpt-oss-120B 120B MXFP4 (MoE) ~1 720–1 820 ~38–50 Llama 3.1 70B 70B Q4 ~1 900 ~4,4
Закономерность видна сразу. Плотная Llama 70B генерирует около 4 токенов/с — это медленнее, чем человек читает: для живого чата неприемлемо, узкое место — 273 ГБ/с. А вот MoE-модели и FP4-форматы ломают правило «больше параметров — медленнее»: gpt-oss-120B (это MoE, где на каждый токен активируется лишь часть весов) идёт в 9–10 раз быстрее плотной 70B, хотя формально «больше». Тот же эффект мы видели и на Strix Halo — для такого класса железа MoE-модели подходят гораздо лучше плотных.

Для batch-нагрузок (много параллельных запросов) числа выглядят солиднее: на Llama 3.1 8B в FP4 DGX Spark выдаёт до ~924 ток/с при 128 одновременных запросах (StorageReview, 2025) — это уже про обслуживание сервиса, а не про одиночный чат.
Сколько стоит и почему цена выросла
С ценой DGX Spark отдельная история, и большинство обзоров (особенно русскоязычных) висят на устаревших цифрах. Полная траектория:
- $2 999 — анонс на CES 2025 (тогда проект назывался DIGITS);
- $3 999 — старт реальных поставок (октябрь 2025);
- $4 699 — с 27 февраля 2026 NVIDIA подняла цену Founders Edition на 18%, сославшись на дефицит памяти LPDDR5X.
Итого +56,7% от анонса до сегодня — и откатывать цену назад NVIDIA не обещала. Это важно для планирования: при покупке нескольких боксов в лабораторию цифра может ещё двигаться, пока на рынке памяти дефицит.
Помимо Founders Edition, тот же чип GB10 продают OEM-партнёры (ASUS Ascent GX10, Dell Pro Max, HP ZGX Nano, Lenovo, MSI, Gigabyte AI-TOP ATOM, Acer Veriton GN100) — спецификации те же, иногда лучше охлаждение или ниже цена. Если 200-гигабитная сеть ConnectX-7 вам не нужна (а локальному пользователю она чаще всего не нужна), стоит присмотреться к OEM-версиям — за неё в Founders Edition вы переплачиваете.
DGX Spark против альтернатив
Здесь — главный вопрос статьи: стоит ли DGX Spark переплаты над конкурентами. Сравним по одной и той же модели (gpt-oss-120B, decode) и по цене за гигабайт быстрой памяти (данные на апрель 2026).Решение Память / ПС Цена $ за ГБ 120B decode, ток/с NVIDIA DGX Spark 128 ГБ / 273 ГБ/с $4 699 $36,7 38,6 Strix Halo (Framework Desktop) 128 ГБ / 256 ГБ/с $2 348 $18,3 34,1 Mac Studio M3 Ultra 256 ГБ / 819 ГБ/с $4 999+ $19,5 70,8 Сборка 3× RTX 3090 (б/у) 72 ГБ / 936 ГБ/с ~$2 400 $33,3 124,0 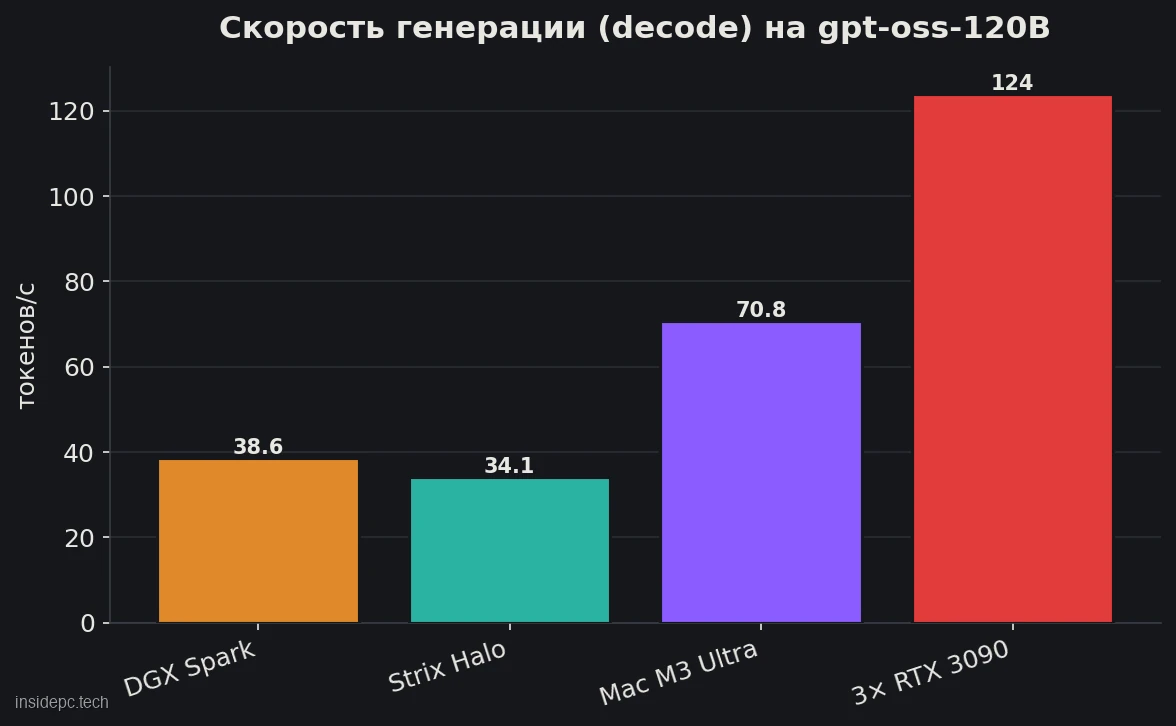
Выводы честные и неудобные для NVIDIA:
- Против Strix Halo. Та же ёмкость (128 ГБ), почти та же пропускная способность, почти та же скорость генерации (38,6 против 34,1 ток/с) — но DGX Spark стоит вдвое дороже. Единственное реальное преимущество в инференсе — мощный prefill: длинный промпт DGX Spark «проглатывает» примерно в 5 раз быстрее (1 720 против ~340 ток/с у Strix Halo). За остальное вы доплачиваете ~$2 350 не за токены, а за экосистему CUDA. Подробный разбор самого Strix Halo — в нашем обзоре Ryzen AI Max+ 395 для локального LLM.
- Против Mac Studio. При сопоставимой цене Mac Studio M3 Ultra даёт втрое большую пропускную способность (819 ГБ/с) и почти вдвое быстрее генерирует (70,8 ток/с), да ещё и вдвое больше памяти. Если вам важна скорость на моделях, которые уже влезли, — Mac выгоднее.
- Против сборки на видеокартах. Три б/у RTX 3090 (72 ГБ суммарно) за те же ~$2 400 выдают 124 ток/с — втрое быстрее DGX Spark. Цена: 1 050 Вт против 240, шум, размер и день возни с драйверами. Зато потолок скорости недостижим для «коробок». О дискретных сборках — в разделе железо для ИИ: видеокарты.
Вердикт сообщества прямой: по соотношению «инференс за деньги» DGX Spark проигрывает всем трём. Его покупают не за это.
За что тогда платят: софт-стек и настройка
Ценность DGX Spark — в программном паритете с дата-центром. Из коробки идёт DGX OS (по сути Ubuntu 24.04 с предустановленными драйверами и стеком NVIDIA), полноценный CUDA, контейнеры NIM, агентный фреймворк NemoClaw, опционально NVIDIA AI Enterprise. Для разработчика это значит: то, что заработало на DGX Spark, без переделок уедет на серверы с H100 — те же драйверы, тот же CUDA-тулкит, те же инструменты.
Запускать модели можно привычными движками: Ollama и LM Studio — для простоты, llama.cpp — для гибкости, vLLM и TensorRT-LLM — для высокой пропускной способности и параллельных запросов. Полезный нюанс — формат NVFP4 (нативный для Blackwell): модели, обученные или дообученные именно под него, ускоряются кратно, тогда как обычный инференс остаётся «скромным» (по официальным замерам NVIDIA). То есть потолок DGX Spark раскрывается не на любых весах, а на подготовленных под его формат.
Отдельно стоит знать про софт-апдейт CES 2026 (январь): TensorRT-LLM, NVFP4 и спекулятивное декодирование Eagle3 дали до 2,5× прироста на части нагрузок (пропускная способность Qwen-235B выросла более чем вдвое, gpt-oss-20B добрался до 49,7 ток/с, видео-генерация ускорилась в 8 раз). Поэтому обзоры с октябрьского запуска занижают реальную сегодняшнюю скорость — смотрите свежие цифры.
После настройки софта пошаговый разбор локального инференса (Ollama, кванты, бэкенды) — в нашем разделе локальные нейросети.
Масштабирование и апгрейд
Память распаяна, поэтому «доставить планку» нельзя — путь роста другой:
- Два DGX Spark в связке. Та самая 200-гигабитная сеть ConnectX-7 позволяет соединить два бокса и работать с моделями до 405 млрд параметров — основной сценарий, ради которого в Founders Edition вообще встроена дорогая сеть.
- Гибрид с Mac Studio. Поскольку DGX Spark силён в prefill, а Mac — в decode, их можно объединить через EXO: DGX Spark обрабатывает промпт, Mac генерирует ответ. Такая «разнесённая» схема даёт до 2,8× ускорения против одного Mac Studio (по замерам EXO Labs).
Риски и слабые места
Честный список того, о чём маркетинг молчит (с датами):
- Медленный decode на плотных моделях. Llama 70B — ~4 ток/с; всё, что упирается в пропускную способность 273 ГБ/с, будет тормозить (Ollama/LMSYS, окт 2025). Для длинного контекста и плотных моделей это ощутимо.
- Цена выросла и может расти дальше. $3 999 → $4 699 (+18%, 27 фев 2026) из-за дефицита LPDDR5X; +56,7% от анонса. Покупка «на пике хайпа» окупается плохо.
- Единая память — это и сила, и риск. Раздельной VRAM нет: ошибка нехватки памяти (OOM) при инференсе или тюнинге может уронить всю систему. Владельцы сообщают о крашах при тренировке, зависаниях сети и частых жёстких перезагрузках (r/LocalLLM, июнь 2026).
- Софт ещё «на острие». DGX OS гарантирует только 2 года поддержки; архитектура ARM64 ломает часть прекомпилированных бинарей (например, отдельные сборки PyTorch); замечен термотроттлинг с рестартами на долгих прогонах (Jeff Geerling, 2025).
- Маркетинговый «1 PFLOP». Это разреженный FP4; реальный плотный compute заметно ниже пикового: независимый замер дал ~480 TFLOPS в FP4 (Banandre, 2025), а в BF16 чип выдаёт лишь ~99,8 TFLOPs (MAMF-замер StorageReview, 2025). Считайте по реальным цифрам, а не по пиковым.
- Переплата за сеть. В Founders Edition встроена дорогая ConnectX-7 на 200 Гбит/с, которая одиночному локальному пользователю не нужна (robert-mcdermott, 2025) — отсюда часть цены и интерес к OEM-версиям.
Справедливости ради — плюсы реальны: день-в-день рабочая среда без возни с драйверами, уникальная ёмкость (запускает то, что не влезает в потребительские карты на 24–32 ГБ; в вирусной демонстрации в X в мае 2026 бокс держал четыре ИИ-агента и ~126 ГБ разом — карта с 96 ГБ VRAM столько бы не вместила, но это заявление сообщества, а не наш замер), сильный prefill, полнопараметрический тюнинг до 8B локально и до 70B в целом, тихий компактный корпус на 240 Вт, кластеризация до 405B.
Кому подходит, а кому нет
- Берите DGX Spark, если вы AI-разработчик, исследователь или ML-инженер, которому важен паритет с дата-центром NVIDIA: прототип на столе → продакшн на H100 без переделок. Плюс приватность и «бесплатные» локальные токены.
- Берите Strix Halo (мини-ПК на Ryzen AI Max+ 395), если нужна та же ёмкость 128 ГБ под локальные модели вдвое дешевле, а CUDA-экосистема не критична.
- Берите Mac Studio, если приоритет — скорость генерации и большие модели: втрое выше пропускная способность при сравнимой цене.
- Соберите систему на видеокартах, если нужен максимум токенов в секунду и вы готовы к шуму, мощности и настройке.
FAQ
Сколько стоит NVIDIA DGX Spark в 2026 году? Founders Edition — $4 699 (с 27 февраля 2026; на старте в октябре 2025 было $3 999, на анонсе CES 2025 — $2 999). Цену подняли из-за дефицита памяти LPDDR5X. OEM-версии на том же чипе GB10 (ASUS, Dell, HP, Lenovo, MSI) бывают дешевле.
Какие модели реально запустит DGX Spark? В память на 128 ГБ влезают модели до 200 млрд параметров, а связка из двух боксов — до 405 млрд. Но скорость зависит от типа модели: плотная Llama 70B идёт всего ~4 ток/с, а MoE-модели вроде gpt-oss-120B — ~38–50 ток/с. Для комфортного локального ИИ выбирайте MoE и компактные модели.
DGX Spark или Strix Halo (Ryzen AI Max+ 395)? По ёмкости и скорости генерации они почти равны, но Strix Halo вдвое дешевле. DGX Spark оправдан, только если вам нужны экосистема CUDA и перенос наработок в дата-центр NVIDIA. Если важна цена за гигабайт памяти — Strix Halo выгоднее.
Почему DGX Spark медленнее видеокарты в генерации? Скорость генерации (decode) почти полностью упирается в пропускную способность памяти. У DGX Spark это 273 ГБ/с, у RTX 3090 — ~936 ГБ/с, у RTX 5090 — 1 792 ГБ/с. Поэтому видеокарты генерируют в разы быстрее на моделях, которые в их VRAM помещаются; преимущество DGX Spark — в ёмкости, а не в скорости.
Можно ли на DGX Spark дообучать модели? Да. NVIDIA заявляет тюнинг до 70 млрд параметров, а в независимых тестах подтверждён полнопараметрический fine-tuning 8B-моделей локально. Это один из главных сценариев устройства — наряду с прототипированием в среде, идентичной дата-центру.
Как собрать конфигурацию под свою модель и бюджет — в гиде по железу для локального ИИ.









