



Коротко (TL;DR)
Большинство локальных нейросетей работают только с текстом. Но есть отдельный класс — vision-модели (vision-language, VLM), которые «видят» изображения: описывают картинку, читают текст с фотографии (OCR), разбирают скриншоты, диаграммы и документы, отвечают на вопросы по изображению. И всё это можно запустить у себя, без отправки картинок в облако.
- Коротко (TL;DR)
- Что такое vision-модель и зачем она нужна
- Как это работает: архитектура за две минуты
- Линейка локальных vision-моделей на июнь 2026
- Сколько VRAM нужно: ловушка «файл ≠ видеопамять»
- OCR локально: кто лучше читает текст
- Запуск: Ollama, LM Studio, llama.cpp
- Настройка под себя: разрешение, контекст, API
- Крошечные vision-модели для агентов
- Сравнение: когда что выбрать
- Риски и грабли
- FAQ
- Главный довод — приватность. Сканы паспортов и договоров, медицинские снимки, личные фото — всё, что вы показываете локальной модели, остаётся на вашем компьютере. Для чувствительных документов это решает.
- Лидеры на 2026 год. Лучший открытый выбор по распознаванию текста и мультиязычности — Qwen2.5-VL. Для слабого железа есть крошечные MiniCPM-V и Moondream. LLaVA — родоначальник жанра, с которого всё началось.
- Главная ловушка — не модель, а память. Vision-модель «съедает» куда больше видеопамяти, чем кажется по размеру файла: картинка превращается в сотни и тысячи токенов. Файл на 7,8 ГБ может потребовать 24 ГБ VRAM при работе с изображениями.
Минимальное железо зависит от модели: лёгкая Moondream запускается на 4 ГБ, Qwen2.5-VL-7B — на 16 ГБ. Данные актуальны на 16 июня 2026 года.
Что такое vision-модель и зачем она нужна
Обычная языковая модель умеет работать только со словами. Vision-модель добавляет к этому «глаза»: она принимает изображение и понимает, что на нём. Под капотом это связка из двух частей — визуального энкодера (он «смотрит» на картинку и переводит её в набор чисел-признаков) и обычной языковой модели (она по этим признакам рассуждает и отвечает текстом). Между ними — небольшой слой-«переходник», который и научили соединять зрение с языком. Именно такую архитектуру в 2023 году популяризировала LLaVA, открыв дорогу всему сегменту. С тех пор подход стал стандартом, а качество выросло на порядок: ранние модели едва описывали простые сцены, а современные читают убористый текст, понимают графики и отвечают на сложные вопросы по изображению. LLaVA дала имя целому классу моделей, и хотя сегодня лидируют другие, термин «LLaVA-подобные» прижился как обозначение всей семьи открытых vision-моделей.
Зачем это локально? Главное — приватность и оффлайн. Облачные сервисы вроде ChatGPT с картинками удобны, но вы отдаёте им свои изображения. Для документов с персональными данными, коммерческих чертежей или медицинских снимков это часто неприемлемо. Локальная vision-модель решает задачу на вашем железе: ни один пиксель не уходит наружу. Сценарии — распознать текст со скана, занести данные с фото чека в таблицу, описать изображение для незрячего, разобрать скриншот ошибки, извлечь цифры из диаграммы.

Список реальных применений шире, чем кажется: оцифровать бумажный архив, превратить фото доски после совещания в текст, описать товар по фотографии для каталога, помочь человеку с нарушением зрения «прочитать» окружение, разобрать схему или чертёж, проверить, что именно изображено на присланном пользователем скриншоте. Везде, где задача — «понять, что на картинке», и где саму картинку нежелательно отправлять на чужой сервер, локальная vision-модель оказывается на месте.

Как это работает: архитектура за две минуты
Чтобы понимать ограничения vision-моделей, полезно знать, как они устроены — без формул.
Внутри три блока. Первый — визуальный энкодер (обычно на базе CLIP): он «нарезает» картинку на фрагменты и переводит каждый в набор чисел, описывающих, что там изображено. Второй — слой-проектор (небольшая нейросеть-«переходник»): он переводит визуальные признаки на «язык», понятный текстовой модели. Третий — сама языковая модель (Llama, Qwen, Vicuna), которая получает «описание» картинки вперемешку с вашим вопросом и отвечает текстом.
Ключевой момент, из которого растут все требования к памяти: картинка превращается не в один токен, а в множество визуальных токенов — по сути, в длинный «текст», который модель должна прочитать. Изображение среднего разрешения легко даёт несколько сотен токенов, а крупное — несколько тысяч. Языковая модель обрабатывает их так же, как слова, поэтому одна картинка нагружает её сильнее, чем длинный абзац текста. Отсюда и прожорливость по видеопамяти, и замедление на больших изображениях. Разные модели «нарезают» картинку по-разному: одни используют фиксированное разрешение, другие — динамическое (адаптируются под размер и детализацию), и от этого зависит и качество на мелком тексте, и расход памяти.
Линейка локальных vision-моделей на июнь 2026
Выбор большой, и модели сильно различаются по требованиям и сильным сторонам. Вот ориентир по актуальным открытым VLM.Модель Параметры VRAM (ориентир) Скорость* Сильна в Moondream2 1,9 млрд ~4 ГБ (Q4) очень высокая Лёгкость, агенты, базовое описание MiniCPM-V (2.6 / 4.6) 1,3–8 млрд ~4–8 ГБ высокая OCR и качество на малом железе Qwen2.5-VL 7B 7 млрд ~16 ГБ (full) ~18 tok/s OCR, документы, 29 языков Pixtral 12B 12 млрд ~24 ГБ (ориентир) средняя Документы, диаграммы Llama 3.2 Vision 11B 11 млрд ~24 ГБ ~12 tok/s Описание (англоцентрична) LLaVA / LLaVA-NeXT 7–34 млрд от ~8 ГБ зависит от backbone Классика, эксперименты
*Скорость — ориентир: ~18 и ~12 токенов/с для Qwen2.5-VL и Llama Vision соответственно по замеру на серверной A100 (источник: Labellerr, 2026); на домашних видеокартах будет ниже. Лицензии большинства моделей в таблице — Apache 2.0 или иные открытые; у Llama 3.2 Vision — Llama Community License.
Краткий разбор: Qwen2.5-VL сейчас — лучший универсал, особенно по распознаванию текста и языкам (об этом ниже). MiniCPM-V и Moondream удивляют тем, как много дают при крошечном размере — их часто хвалят за соотношение «качество на гигабайт». Llama 3.2 Vision сильна в описании, но заточена под английский. Pixtral 12B от Mistral хорош для документов и диаграмм. LLaVA-NeXT — последняя версия родоначальника жанра, хороша для обучения и экспериментов. А универсальные Gemma и Qwen3 тоже умеют видеть изображения — если вам нужна одна модель «на всё», загляните в их обзоры.
Стоит знать и про тенденции 2026 года: vision-сегмент развивается быстро. Появляются всё более лёгкие модели (MiniCPM-V в версии 4.6 ужалась до 1,3 млрд параметров и запускается на смартфоне), а крупные открытые VLM вроде InternVL подбираются по качеству к закрытым. Отдельный тренд — зрение уходит с десктопа: в июне 2026 года, по сообщению TechCrunch, vision-модель Gemma развернули прямо на орбитальном спутнике для автономного анализа снимков. Практический вывод для нас: выбор открытых vision-моделей сейчас широк как никогда, и почти под любое железо есть свой вариант.
Сколько VRAM нужно: ловушка «файл ≠ видеопамять»
Это самая частая ошибка новичка, и наш главный information gain. Когда вы качаете текстовую модель, размер файла примерно соответствует нужной видеопамяти. С vision-моделями это правило ломается.
Причина — в том, как модель «видит». Картинка для неё не один объект, а сотни или тысячи «визуальных токенов»: чем выше разрешение изображения, тем больше токенов, и все они занимают видеопамять во время работы. Поэтому модель Llama 3.2 Vision 11B весит на диске около 7,8 ГБ (по данным Roboflow, июнь 2026), но при реальной работе с изображениями требует порядка 24 ГБ VRAM — втрое больше, чем «по файлу».
Практический вывод: при выборе vision-модели смотрите не на размер скачиваемого файла, а на требования к видеопамяти при инференсе с картинками. И помните: чем крупнее изображения вы подаёте, тем больше памяти уйдёт. Если упёрлись в нехватку VRAM — уменьшайте разрешение входных картинок, это первый и самый действенный рычаг.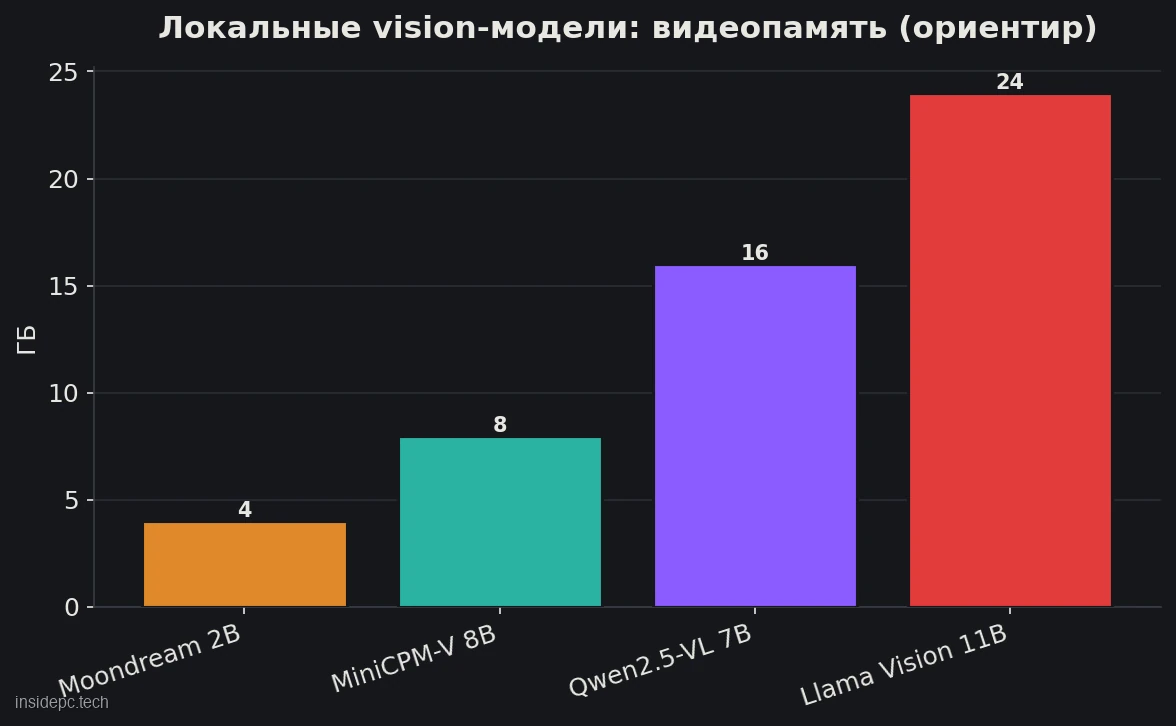
Отсюда же — практичный приём для слабого железа: брать не одну большую мультимодальную модель, а крошечную vision-модель как «инструмент зрения» (например, Moondream на 4 ГБ) в связке с обычной текстовой LLM-оркестратором. Зрительная модель только описывает картинку текстом, а дальше рассуждает текстовая — суммарно это часто требует меньше видеопамяти, чем одна крупная VLM.
OCR локально: кто лучше читает текст
Распознавание текста (OCR) — самый востребованный сценарий vision-моделей, и здесь есть явный лидер. Qwen2.5-VL заметно превосходит конкурентов: по тесту OCRBench он берёт около 864 баллов, а на распознавании документов DocVQA — около 95,7% (по официальной карточке модели). Важно для нас: Qwen2.5-VL поддерживает 29 языков, включая русский, украинский и сложные восточноазиатские, тогда как Llama 3.2 Vision заточена в основном под английский. Для распознавания русско- и украиноязычных документов это решающий аргумент в пользу Qwen.
У локального OCR есть реальные ограничения:
- Рукописный текст и плохие сканы — слабое место VLM. На размытых, мятых или затемнённых документах они нередко «додумывают» текст, который не видят, опираясь на языковые догадки вместо того, чтобы признать, что текст не читается. Это задокументировано свежим исследованием (arXiv, июнь 2026). Для качественного печатного текста модели справляются хорошо, для деградированных сканов классический движок вроде Tesseract порой надёжнее.
- Разрешение решает. Qwen2.5-VL работает с динамическим разрешением (адаптируется под картинку), а Llama 3.2 Vision — с фиксированным; на мелком тексте это заметно влияет на результат.
Для полноты картины — как выглядят конкуренты по работе с документами. Pixtral 12B от Mistral берёт около 90,7% на DocVQA и силён в диаграммах (около 81,8% на ChartQA). MiniCPM-V при своём малом размере держится на удивление близко к лидерам и часто рекомендуется как «бюджетный OCR». InternVL в старших версиях показывает один из лучших результатов среди открытых моделей на комплексном тесте MMMU. Но для повседневного распознавания документов на русском и украинском Qwen2.5-VL остаётся самым сбалансированным выбором: качество, языки и разумные требования к железу.
Запуск: Ollama, LM Studio, llama.cpp
Запустить vision-модель сегодня просто. Самый лёгкий путь — Ollama, который умеет принимать картинки прямо в команде (проверено по каталогу Ollama, июнь 2026):
ollama run qwen2.5-vl "опиши это фото: ./image.jpg"
ollama run llava "describe this image: ./screenshot.png"
ollama run minicpm-v "извлеки текст: ./scan.jpg"
ollama run moondream "./photo.jpg"
Ollama сразу поднимает локальный API на localhost:11434, и изображения можно передавать через него (в base64) — это удобно для скриптов и ботов, которые обрабатывают картинки пачками.
Простой практический сценарий — превратить фото чека или счёта в структурированные данные. Вы подаёте фотографию и просите: «извлеки из этого чека дату, сумму и список позиций в виде таблицы». Qwen2.5-VL распознаёт текст, понимает структуру документа и возвращает готовую таблицу, которую можно вставить в учётную программу. То же работает с визитками, бланками, скриншотами переписки — везде, где нужно перевести «картинку с текстом» в данные. И весь процесс идёт на вашем компьютере: ни чек, ни паспорт, ни договор не попадают на чужие серверы.
LM Studio — графическая альтернатива: перетаскиваете картинку в чат, и модель её разбирает. Удобно для разовых задач без терминала; здесь же легко настроить выгрузку слоёв на GPU, чтобы запустить vision-модель даже на видеокарте 8 ГБ.
llama.cpp напрямую — для максимального контроля. Здесь у vision-моделей есть особенность: помимо самой модели нужен отдельный файл mmproj (это и есть тот самый «переходник» между зрением и языком) — без него картинки работать не будут. Если используете llama.cpp вручную, скачайте оба файла и укажите проектор флагом --mmproj:
llama-mtmd-cli -m model.gguf --mmproj mmproj.gguf --image ./photo.jpg -p "опиши изображение"
Типовые ошибки и решения:
- Модель «не видит» картинку — в llama.cpp забыт файл mmproj; скачайте его рядом с моделью. В Ollama и LM Studio он подтягивается сам.
- Нехватка видеопамяти при подаче фото — изображение раздуло контекст; уменьшите разрешение картинки или возьмите модель полегче.
- Модель выдумывает текст вместо распознавания — типично для плохого скана; повысьте качество изображения или используйте классический OCR для деградированных документов.
Настройка под себя: разрешение, контекст, API
У vision-моделей свои тонкости настройки.
- Разрешение входных изображений — главный рычаг. Чем больше картинка, тем больше визуальных токенов и видеопамяти. Если упёрлись в нехватку VRAM или модель работает медленно, первым делом уменьшайте разрешение подаваемых изображений. Для OCR мелкого текста, наоборот, разрешение лучше не занижать.
- Длина контекста. Картинка уже «съела» часть контекстного окна сотнями токенов. Если задаёте длинный текстовый вопрос вдобавок к изображению, окно может переполниться — следите за
num_ctx. - Температура. Для OCR и фактического описания ставьте низкую (0.1–0.3): зрению не нужна «фантазия», а высокая температура усиливает галлюцинации на картинках.
- Чёткий промпт. Vision-модели лучше отвечают на конкретный запрос («извлеки весь текст с этого чека в виде списка») и хуже — на расплывчатый («что тут?»). Чем точнее задача, тем меньше выдумок.
Режим API. Через Ollama модель поднимает сервер на localhost:11434 в формате OpenAI, и картинки передаются в запросе закодированными в base64. Это удобно для автоматизации: можно собрать локальный сервис, который пачкой обрабатывает сканы или скриншоты, и при этом ни одно изображение не уходит в облако — для документооборота с персональными данными это и есть главная ценность локального запуска.
Крошечные vision-модели для агентов
Отдельно стоит сказать про «малышей», потому что в 2026 году они удивляют. Moondream2 (около 1,9 млрд параметров) запускается на 4 ГБ и годится как лёгкий «глаз» для автоматизаций. MiniCPM-V в версии 4.6 ужалась до 1,3 млрд параметров и работает даже на телефонах (Android, iOS), а более крупная 2.6 при размере около 8 млрд по OCR конкурирует с моделями вдвое тяжелее — по оценкам сообщества (r/LocalLLaMA), её нередко ставят выше, чем Llama 3.2 Vision 11B по соотношению качества и видеопамяти.
Зачем такие крошечные модели? Для агентных сценариев, где зрение — лишь один из навыков. Лёгкая VLM подключается как отдельный инструмент: «посмотри на скриншот и опиши, что видишь», а основную логику ведёт текстовая модель. Это экономит видеопамять и работает быстро. Если строите локального агента, который должен иногда «смотреть» на экран или документы, начинать стоит именно с MiniCPM-V или Moondream, а не с тяжёлой 11B.
На практике связка выглядит так: пользователь присылает скриншот, лёгкая VLM за доли секунды описывает его текстом («окно браузера с ошибкой 404 на странице оплаты»), а основная текстовая модель уже принимает решение, что делать дальше. Зрение здесь — дешёвый «датчик», а не главный движок, и именно поэтому крошечной модели достаточно. Такой подход экономит и видеопамять, и время отклика, поэтому его всё чаще применяют в локальных ассистентах.
Сравнение: когда что выбрать
«Лучшей vision-модели вообще» не существует — выбор зависит от задачи, языка и железа. Вот ориентир (по состоянию на июнь 2026).Задача / условие Рекомендация OCR документов, в т.ч. на русском/украинском Qwen2.5-VL 7B Слабое железо (4–8 ГБ VRAM) MiniCPM-V или Moondream Описание изображений на английском Llama 3.2 Vision, LLaVA-NeXT Диаграммы и таблицы Pixtral 12B, Qwen2.5-VL Одна модель «на всё» (текст + картинки) Gemma или Qwen3 (см. их обзоры) Агент с эпизодическим зрением Moondream + текстовая LLM
Если коротко: для большинства практичных задач (особенно OCR на наших языках) берите Qwen2.5-VL 7B, если хватает 16 ГБ видеопамяти. На скромном железе — MiniCPM-V. Для агентов — связку с крошечной моделью.
И ещё один ориентир по нагрузке. Если задача разовая (раз в день описать пару картинок), подойдёт почти любая модель из таблицы — берите ту, что влезает в вашу видеопамять. Если же зрение нужно постоянно и пачками (поток сканов, мониторинг скриншотов), на первый план выходят скорость и расход памяти — и тогда выбор между лёгкой быстрой моделью и тяжёлой точной превращается в осознанный компромисс под вашу нагрузку.
Риски и грабли
- Галлюцинации на изображениях. Vision-модель может уверенно «увидеть» то, чего нет, особенно на нечётких картинках. Для важных задач (медицина, документы) перепроверяйте вывод — модель ошибается так же убедительно, как и отвечает верно.
- Плохой OCR деградированных сканов. На размытом, рукописном или мятом тексте VLM склонны додумывать. Для таких случаев классический OCR (Tesseract) бывает надёжнее; комбинируйте инструменты.
- Ловушка VRAM. Размер файла обманчив — картинки требуют гораздо больше видеопамяти. Ориентируйтесь на требования при инференсе, а не на вес модели.
- Разрешение и VRAM. Чем крупнее подаёте изображение, тем больше памяти и времени уходит. Не нужно — уменьшайте разрешение входа.
- Языковые ограничения. Не все модели одинаково хороши в русском и украинском: Llama Vision слаба в кириллице, Qwen2.5-VL — сильна. Проверяйте под свой язык.
- Не всегда нужна именно VLM. Для чистого извлечения текста из качественного PDF классический OCR (Tesseract, PaddleOCR) быстрее и точнее. Vision-модель оправдана там, где нужно ещё и понять изображение — описать, ответить на вопрос, разобрать структуру. Не стреляйте из VLM по простым задачам OCR.
- Перегрев при долгих сессиях. Обработка изображений нагружает видеокарту — следите за температурами на компактных сборках.
FAQ
Какая локальная vision-модель лучше всего распознаёт текст на русском? Qwen2.5-VL — она лидирует по OCR (около 95,7% на тесте DocVQA) и поддерживает 29 языков, включая русский и украинский. Для распознавания документов на наших языках это лучший открытый выбор. Llama 3.2 Vision в кириллице заметно слабее.
Почему vision-модель требует больше видеопамяти, чем весит файл? Потому что изображение модель превращает в сотни или тысячи «визуальных токенов», и все они занимают память во время работы. Например, Llama 3.2 Vision 11B весит около 7,8 ГБ на диске, но при работе с картинками требует порядка 24 ГБ VRAM. Чем выше разрешение картинки, тем больше памяти нужно.
Можно ли запустить vision-модель на видеокарте 8 ГБ? Да — для этого есть лёгкие модели: Moondream (около 4 ГБ) и MiniCPM-V. Они уступают крупным в сложных задачах, но отлично справляются с базовым описанием и OCR. Тяжёлые модели вроде Llama 3.2 Vision 11B на 8 ГБ целиком не поместятся.
Чем локальная vision-модель лучше облачной для работы с документами? Приватностью. Сканы паспортов, договоров, медицинских справок при локальной обработке не покидают ваш компьютер — их не видит ни один сторонний сервис. Для чувствительных документов это решающий аргумент, ради которого стоит потерпеть более скромное по сравнению с облаком качество.
Стоит ли использовать vision-модель для распознавания рукописного текста? С осторожностью. Рукописный и плохо отсканированный текст — слабое место таких моделей: они склонны «додумывать» неразборчивые места. Для качественного печатного текста они работают хорошо, а для рукописного или деградированных сканов классический OCR-движок (например, Tesseract) часто оказывается надёжнее.
Сколько места на диске и видеопамяти займёт vision-модель? По-разному: Moondream — около 4 ГБ, MiniCPM-V — 4–8 ГБ, Qwen2.5-VL-7B — порядка 16 ГБ при работе с картинками, Llama 3.2 Vision 11B — около 24 ГБ. Важно: ориентируйтесь именно на видеопамять при инференсе, а не на размер файла — для vision-моделей они сильно расходятся.
Можно ли подключить локальную vision-модель к своему скрипту или боту? Да. Ollama поднимает локальный API в формате OpenAI, и изображения передаются в запросе (в base64). Это позволяет собрать, например, сервис, который автоматически распознаёт текст с загруженных сканов или описывает фотографии, — целиком на вашем железе, без облака и оплаты за запросы.
Какие форматы изображений понимают vision-модели? Стандартные растровые — JPEG, PNG, WebP и подобные. Их можно подавать напрямую файлом (в Ollama) или закодированными в base64 через API. Векторные форматы (SVG) и многостраничные PDF обычно нужно сначала превратить в картинки — например, отрендерить страницы PDF в PNG, а уже их подавать модели.
Локальная vision-модель хуже облачной (GPT-4o, Gemini)? В сложных задачах — да, флагманские облачные модели пока точнее, особенно на запутанных изображениях и редких языках. Но разрыв сократился: для OCR документов, описания фото и разбора скриншотов локальные Qwen2.5-VL и MiniCPM-V дают вполне рабочее качество. Локальную берут ради приватности и бесплатности, облачную — когда нужна максимальная точность и не жаль отправить картинку наружу.











