
Коротко (TL;DR)
Gemma — семейство открытых моделей от Google DeepMind, построенное на той же технологии, что и облачный Gemini. Для локального запуска у Gemma репутация «лучшей модели, которая помещается на одну потребительскую видеокарту», и в 2026 году к этому добавился ещё один весомый аргумент.
- Коротко (TL;DR)
- Две генерации Gemma: 3 и 4
- Сколько нужно железа: VRAM, кванты и скорость
- QAT-кванты Google: почему они лучше обычных
- MoE 26B-A4B: быстрая, но память не экономит
- Мультимодальность: изображения, OCR и аудио
- Лицензия: главная история Gemma
- Запуск: Ollama, LM Studio, llama.cpp
- Настройка под себя: контекст, температура и API
- Русский и украинский: 140+ языков
- Бенчмарки и арена: где стоит Gemma 4
- Gemma против Qwen3, Llama и Mistral
- Риски и грабли
- FAQ
- Две генерации. Актуальны обе: Gemma 3 (размеры 1B, 4B, 12B, 27B) — проверенная база с морем готовых квантов, и Gemma 4 (от компактных E2B/E4B до 31B и MoE-варианта 26B-A4B) — новое поколение апреля 2026 с режимом рассуждений и более высокими бенчмарками.
- Главное изменение — лицензия. Gemma 3 шла под собственными условиями Google с правом ограничить использование, а Gemma 4 выпущена под свободной Apache 2.0. Это снимает юридический риск и делает её безопасной для коммерческих продуктов.
- Сильные стороны: мультимодальность (модели видят изображения и хорошо распознают текст с фото), официальные QAT-кванты с экономией памяти и поддержка 140+ языков, включая уверенный русский и украинский.
Минимальное железо: компактные Gemma 4 E2B/E4B запускаются на 6 ГБ видеопамяти, флагманская 31B в кванте Q4 заходит в 24 ГБ, а с официальным QAT-квантом — ещё экономнее. Данные актуальны на 16 июня 2026 года.
Две генерации Gemma: 3 и 4
На середину 2026 года в ходу обе линейки. Понимать разницу важно, потому что от поколения зависят и возможности, и — что критично — лицензия.Линейка Размеры Контекст Мультимодальность Лицензия Дата Gemma 3 1B, 4B, 12B, 27B 32K (1B) / 128K Изображения (4B+) Gemma Terms of Use март 2025 Gemma 4 E2B, E4B, 12B, 26B-A4B (MoE), 31B 128K / 256K (12B/26B/31B) Изображения, видео; аудио — E2B/E4B/12B Apache 2.0 апрель 2026
Gemma 3 остаётся отличным выбором, если вам нужна стабильная модель с огромным числом готовых сборок — её 27B-версия в своё время вошла в топ открытых моделей под одну карту 24 ГБ. Gemma 4 — это шаг вперёд: добавился режим рассуждений (chain-of-thought), выросли бенчмарки, расширилась мультимодальность (теперь и аудио), а контекст у старших моделей дорос до 256K. Но главный практический сдвиг — лицензия, о которой отдельный разговор ниже.
Сколько нужно железа: VRAM, кванты и скорость
Как и другие локальные модели, Gemma запускают в квантованном виде (формат GGUF, ходовой квант Q4). Вот официальные требования Gemma 4 по видеопамяти (значения Google с учётом ~20% накладных расходов, квант Q4; данные docs на июнь 2026):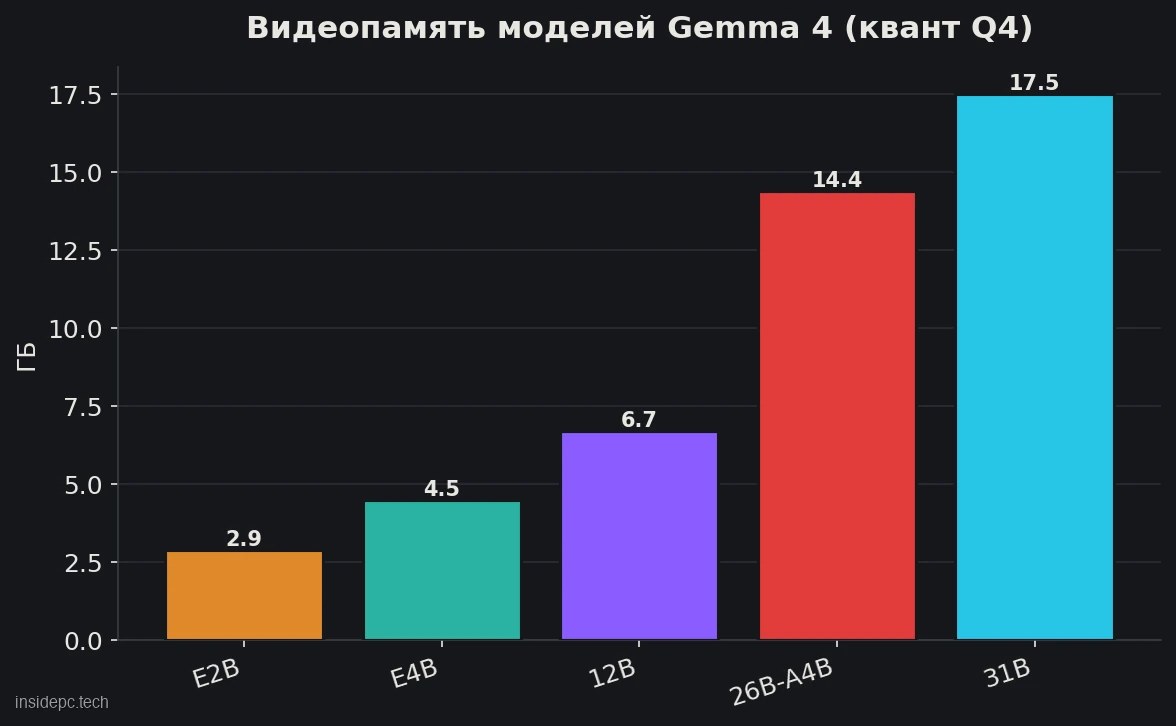
Модель Gemma 4 (Q4) VRAM Комфортное железо Скорость (ориентир) E2B (~2B) ~2,9 ГБ любая карта от 4 ГБ ~15+ tok/s E4B (~4B) ~4,5 ГБ 6–8 ГБ (RTX 3050/3060) ~10+ tok/s и выше 12B ~6,7 ГБ 8–12 ГБ высокая 26B-A4B (MoE) ~14,4 ГБ 16 ГБ и выше ~30+ tok/s 31B ~17,5 ГБ 24 ГБ (RTX 3090/4090) до ~140 tok/s (RTX 5090)

Для Gemma 3 ориентиры близкие по размеру: 4B живёт на 8 ГБ, 12B — на 12–16 ГБ, а 27B комфортно заходит в 24 ГБ. Важная поправка, общая для всех моделей: к размеру весов добавляется память под контекст (KV-кэш), и у Gemma 4 в режиме рассуждений он разрастается особенно быстро — об этом в разделе про риски. Цифры скорости — ориентир и зависят от железа, кванта и контекста; свежие замеры сверяйте на странице модели в каталоге Ollama.
Если выбираете видеокарту под локальный ИИ, отталкивайтесь от объёма VRAM — подробный разбор в гиде по выбору GPU для ИИ.
QAT-кванты Google: почему они лучше обычных
Это наш information gain — деталь, которую почти не объясняют по-русски. Обычно модель сжимают «постфактум» (квантизация после обучения), и часть качества при этом теряется. Google пошла дальше и выпустила официальные QAT-кванты (quantization-aware training) — модели, обученные с учётом будущего сжатия.
Результат: int4-версия Gemma занимает примерно втрое меньше памяти, чем исходная, но сохраняет качество, близкое к полному формату bfloat16. На практике это значит, что QAT-вариант модели работает заметно точнее, чем такой же по размеру обычный GGUF-квант.
Где взять: официальные коллекции на Hugging Face — google/gemma-3-qat и google/gemma-4-qat-q4-0. Для llama.cpp ищите файлы с суффиксом -qat-q4_0-gguf. Если для вас важно выжать максимум качества из ограниченной видеопамяти — берите именно QAT-версию, а не первый попавшийся квант.
MoE 26B-A4B: быстрая, но память не экономит
У Gemma 4 есть модель на архитектуре «смеси экспертов» — 26B-A4B. В названии «A4B» означает, что на каждый токен активны лишь около 4 млрд параметров из 26 млрд. Это делает её быстрой (порядка 30+ токенов/с) и по качеству близкой к флагманской 31B — примерно 97% от неё.
Но здесь кроется типичная ловушка для новичка. «Активных 4B» не значит «нужно 4 ГБ». В память грузятся все 26 млрд весов — это около 14,4 ГБ в кванте Q4. MoE экономит вычисления и тем самым скорость, но не видеопамять: чтобы запустить 26B-A4B, нужна карта от 16 ГБ, а не 8. Если читали «4B active» и рассчитывали на свою 8-гигабайтную карту — увы, не поместится.
Мультимодальность: изображения, OCR и аудио
Одна из сильнейших сторон Gemma — работа не только с текстом. Модели Gemma 3 от 4B и выше, а также Gemma 4, умеют видеть изображения: опишут картинку, разберут диаграмму, извлекут текст с фотографии документа. Gemma 4 добавила работу с видео, а компактные E2B/E4B (и 12B) — ещё и с аудио.
Особенно ценный для практики сценарий — локальный OCR: распознавание текста с фото и сканов. В сообществе r/LocalLLaMA Gemma регулярно называют одной из лучших открытых моделей для этой задачи. Главный плюс перед облачными сервисами — приватность: сканы паспортов, договоров и медицинских документов не покидают ваш компьютер.
Запустить мультимодальную модель просто: в Ollama и LM Studio достаточно прикрепить изображение к запросу — модель сама поймёт, что с ним работать. Учтите только, что обработка картинки требует дополнительной видеопамяти сверх размера самой модели.
Лицензия: главная история Gemma
Здесь — ключевой сюжет, который большинство обзоров упускают, а для нашей аудитории он самый практичный.
Gemma 3 распространялась под собственными условиями Google — Gemma Terms of Use. Это не открытая лицензия в полном смысле: Google оставляла за собой право дистанционно ограничивать использование модели и накладывала ряд запретов на сценарии применения. Для пет-проекта неважно, но для бизнеса это был юридический риск — на него прямо обращали внимание профильные издания при выходе Gemma 3.
Gemma 4 выпущена под Apache 2.0 — одной из самых свободных лицензий. Никаких порогов, права на дистанционное ограничение и запретов на коммерцию: модель можно встраивать в продукты, модифицировать и распространять свободно.Модель Лицензия Коммерция Особенности Gemma 3 Gemma Terms of Use С ограничениями Google вправе ограничить использование Gemma 4 Apache 2.0 Свободно Без порогов и ограничений Llama 4 Llama Community До 700 млн MAU Запрет обучать другие модели
Вывод простой: если строите коммерческий продукт, берите Gemma 4 — с её Apache 2.0 вы юридически чисты. На фоне Gemma 3 и Llama это серьёзное преимущество.
Запуск: Ollama, LM Studio, llama.cpp
Самый простой путь — Ollama. Команды (проверено по каталогу Ollama, июнь 2026):
ollama run gemma3:4b # лёгкая, 8 ГБ, мультимодальная
ollama run gemma3:12b # средний класс
ollama run gemma3:27b # флагман Gemma 3 на 24 ГБ
ollama run gemma4:e4b # компактная Gemma 4, 6 ГБ
ollama run gemma4:12b # Gemma 4 средний класс
ollama run gemma4 # флагман 31B (~17,5 ГБ, карта 24 ГБ); для 8 ГБ берите gemma4:e4b
Ollama сразу поднимает локальный API, совместимый с форматом OpenAI, — удобно для подключения к редакторам кода и ботам.
LM Studio — графический интерфейс с каталогом моделей и удобным просмотром, в том числе для мультимодальных запросов. Хороший выбор, если не любите терминал.
llama.cpp напрямую — для максимальной производительности и тонкой настройки; именно здесь удобнее всего подключать официальные QAT-кванты.
Важная настройка для Gemma 4: режим рассуждений (thinking mode) включён по умолчанию и для простых задач только замедляет ответ и расходует видеопамять. Если вам нужен быстрый чат или суммаризация, отключите его — в Ollama это делается параметром think=false. Для сложных логических задач, наоборот, оставьте включённым.
Настройка под себя: контекст, температура и API
Несколько параметров, которые стоит подстроить под свои задачи.
- Длина контекста (num_ctx). Старшие Gemma 4 держат до 256K токенов, но Ollama по умолчанию выделяет меньше. Для длинных документов поднимайте
num_ctxвручную — помня, что контекст расходует видеопамять (KV-кэш), особенно при включённых рассуждениях. - Температура. Общепринятые ориентиры сообщества: для кода и фактических задач — 0.1–0.3, для свободного текста — около 0.7.
- Системный промпт. Помогает закрепить язык и стиль ответа, что особенно полезно для русского и украинского. С оговоркой: Gemma 4 иногда слабо реагирует на системные инструкции (см. раздел рисков).
- Режим рассуждений — главный переключатель скорости у Gemma 4; как им управлять, описано в разделе про запуск выше.
Режим API. Ollama поднимает сервер на localhost:11434, совместимый с форматом OpenAI: подключайте редакторы кода, ботов и собственные скрипты, а для мультимодальных задач передавайте изображение прямо в запросе. Все данные остаются на вашем компьютере — в этом и смысл локального запуска: приватность плюс отсутствие платы за токены.
Русский и украинский: 140+ языков
Gemma изначально многоязычна: и третье, и четвёртое поколение официально поддерживают более 140 языков, а под капотом используют тот же токенизатор на 262 тысячи токенов, что и облачный Gemini. Это выводит Gemma в число сильных открытых моделей для русского и украинского — она грамотно пишет, переводит и понимает контекст на этих языках.
В прямом сравнении лучшим открытым выбором для русского чаще называют Qwen3, но Gemma идёт следом и нередко выигрывает там, где нужна мультимодальность (например, разобрать русскоязычный документ по фото). Практический совет тот же, что и для других моделей: задавайте системный промпт с явным указанием языка — это стабилизирует ответы.
Бенчмарки и арена: где стоит Gemma 4
По независимым замерам Gemma 4 заметно прибавила. На открытой арене LMArena, где модели сравнивают вслепую живые пользователи, флагманская Gemma 4 31B держалась в районе 40–45-го места с рейтингом около 1451 (по данным LMArena на середину июня 2026 года) — высокий результат для модели, которую можно запустить на домашней карте 24 ГБ.
По профильным бенчмаркам (по данным вторичных обзоров, апрель 2026): около 89% на математическом AIME 2026, рейтинг Codeforces ELO порядка 2150 по программированию и 84% на научном GPQA. Цифры стоит воспринимать как ориентир — официальные результаты сверяйте в карточке модели, а арена быстро меняется, так что перед важным выбором проверьте текущую позицию.
Практический вывод из бенчмарков: Gemma 4 особенно сильна в коде и математике, что делает её хорошим локальным помощником разработчика.
Gemma против Qwen3, Llama и Mistral
«Лучшей модели вообще» не бывает. Вот честное сравнение Gemma с тремя главными соперниками в локальном сегменте (по состоянию на июнь 2026).Критерий Gemma 4 Qwen3 Llama Mistral Small Русский/украинский Хорошо Лучший Средне Средне Мультимодальность Сильная (фото, видео, аудио) Есть варианты Vision Ограниченная Лицензия Apache 2.0 Apache 2.0 Community Apache 2.0 Под одну карту 24 ГБ Отлично (31B/27B) Хорошо (32B) 70B только с offload Хорошо Код и математика Очень хорошо Очень хорошо Хорошо Хорошо QAT-кванты Официальные Нет Нет Нет
Где Gemma объективно впереди: мультимодальность, официальные QAT-кванты и качество на одной потребительской карте. Где стоит выбрать иначе: для чисто текстовых задач на русском Qwen3 чуть сильнее, а для агентных сценариев (вызов инструментов) пользователи нередко предпочитают Qwen.
Риски и грабли
- MoE не экономит видеопамять. 26B-A4B быстрая, но грузит все 26 млрд весов (~14,4 ГБ) — на 8 ГБ не запустится, несмотря на «4B active».
- Режим рассуждений ест память и время. У Gemma 4 thinking mode по умолчанию включён; на длинном контексте KV-кэш способен занять всю видеопамять — на это жалуются пользователи r/LocalLLaMA. Для простых задач отключайте его параметром
think=false. - Слабая реакция на системный промпт. По сообщениям сообщества (r/LocalLLaMA, июнь 2026), Gemma 4 26B-A4B иногда игнорирует системные промпты и неохотно вызывает инструменты — учитывайте при построении агентов.
- Лицензия Gemma 3. Если берёте именно третье поколение для коммерции, помните про Gemma Terms of Use с правом Google ограничить использование. Для бизнеса безопаснее Gemma 4 на Apache 2.0.
- Vision требует запаса памяти. Обработка изображений добавляет нагрузку сверх размера модели — закладывайте видеопамять с запасом.
- Перегрев при долгих сессиях. Тяжёлые модели надолго нагружают видеокарту — следите за температурами на компактных сборках.
FAQ
Какую Gemma выбрать для видеокарты на 8 ГБ? Gemma 4 E4B (~4,5 ГБ) или 12B (~6,7 ГБ в Q4), либо Gemma 3 4B — все умещаются в 8 ГБ и поддерживают изображения. Если важно максимальное качество в этой памяти, берите официальный QAT-квант. Модели 26B-A4B и 31B на 8 ГБ не поместятся.
Чем Gemma 4 лучше Gemma 3? Главное — лицензия Apache 2.0 вместо ограничительных условий Gemma 3, что снимает риски для коммерции. Плюс режим рассуждений, более высокие бенчмарки в коде и математике, расширенная мультимодальность (добавилось аудио) и контекст до 256K у старших моделей.
Что такое QAT-кванты и зачем они нужны? Это официальные сжатые версии Gemma, обученные с учётом квантизации. Они занимают примерно втрое меньше памяти, чем исходная модель, но сохраняют качество, близкое к полному формату. Проще говоря — лучший результат при той же видеопамяти, чем у обычного GGUF-кванта.
Может ли Gemma распознавать текст на фото локально? Да. Мультимодальные версии Gemma 3 (от 4B) и Gemma 4 хорошо справляются с OCR — распознают текст со сканов и фотографий документов прямо на вашем компьютере, без отправки данных в облако. Это один из самых популярных локальных сценариев Gemma.
Как отключить «размышления» Gemma 4, чтобы она отвечала быстрее?
В Ollama добавьте параметр think=false — модель перестанет тратить время и память на пошаговые рассуждения и будет отвечать сразу. Для простого чата и суммаризации это заметно ускоряет работу; для сложных логических задач режим лучше вернуть.
Gemma или Qwen3 — что брать для русского языка? Для чисто текстовых задач на русском Qwen3 обычно чуть сильнее, но Gemma идёт следом и выигрывает, когда нужна мультимодальность — например, разобрать русскоязычный документ по фотографии. Обе поддерживают русский и украинский официально. Для агентных сценариев (вызов инструментов) пользователи нередко предпочитают Qwen3 — Gemma 4 иногда капризна с системными промптами.













