
Коротко (TL;DR)
Intel Arc B580 — це найдешевший серйозний вхід у локальний ШІ: 12 ГБ відеопам’яті за рекомендовані $250. Цього вистачає, щоб комфортно ганяти моделі на 7–8B і навіть 14B у квантуванні — на швидкості від ~32 до ~44 токенів/с, тобто приблизно на рівні NVIDIA RTX 3060. Для студента, хобіста чи першого ШІ-сервера це найкращий спосіб увійти за мінімальні гроші.
Але чесна рамка важливіша, ніж зазвичай. Головна складність не в карті, а в софті. Стандартний Ollama не прискорює Arc — він мовчки рахує на процесорі, і новачок думає, що «карта повільна». Реально прискорюють або Intel-форк IPEX-LLM, або llama.cpp (Vulkan/SYCL), LM Studio й KoboldCpp. Друге: стеля 12 ГБ жорстка — 32B і тим паче 70B сюди не влізуть. Третє: прямий суперник — RTX 3060 12 ГБ з її зрілою CUDA.
Ціна (червень 2026): MSRP $250, але на вулиці нова зазвичай іде трохи вище — $300–310 (ASRock Challenger ~$303–309); б/в — близько $254, а окремі Limited Edition ловлять за ~$200. Нижче — що карта реально тягне з цифрами, бюджетний BOM, розбір софт-стека Arc (де всі спотикаються) і кому це шлях, а кому пастка.
(Дані актуальні на 15 червня 2026; ціни й бенчмарки — з датами в тексті.)

Завдання та бюджет
Ця збірка — про мінімально життєздатний локальний ШІ: чат-асистент, кодинг-помічник і RAG на моделях 7–14B, плюс легка генерація зображень. Профіль покупця — той, у кого жорсткий ліміт ~$250–300 на відеокарту: студент, хобіст, розробник, який хоче «помацати» локальні моделі без вкладень у RTX-збірку, або той, хто будує перший домашній ШІ-сервер.

Бюджет — головний і єдиний аргумент на користь цієї карти. B580 коштує $250 проти $750+ за 24-ГБ рішення на кшталт Radeon RX 7900 XTX. При цьому за обсягом пам’яті вона обходить суперників свого класу: у RTX 4060 і RX 7600 за близькі гроші всього 8 ГБ, а 12 ГБ — це різниця між «вміщується 8B з нормальним контекстом» і «впритул». Повна бюджетна станція (карта + скромний CPU, плата, пам’ять, БЖ, корпус) виходить від ~$800.
Тверезе застереження: якщо ви готові витратити на карту $600+, серйозніше придивитися до б/в RTX 3090 (24 ГБ, CUDA) — вона знімає стелю 12 ГБ і позбавляє мороки з Intel-стеком. B580 беруть саме тоді, коли важлива нижня межа ціни.
Конфігурація (BOM)
Бюджетна збірка під одну B580. Карта на 190 Вт і 2 слоти — вимоги до корпусу й живлення мінімальні, але обов’язковий Resizable BAR (є на всіх сучасних платах).Компонент Модель Ціна Навіщо саме це Відеокарта Intel Arc B580 12 ГБ (Battlemage) $250–310 12 ГБ GDDR6, 456 ГБ/с — ядро входу Процесор Ryzen 5 7600 / Core i5-12400F ~$130–180 інференс на GPU; CPU — обв’язка Мат. плата B650 / B760 (Resizable BAR) ~$120–160 ReBAR обов’язковий для Arc Пам’ять 32 ГБ DDR5 ~$80–110 під систему й контекст Блок живлення 550–650 Вт ~$70 190 Вт карти + запас Корпус + NVMe з продуванням + 1 ТБ NVMe ~$150 під систему й ваги моделей Разом від ~$800 (орієнтир, червень 2026)
Зауваження: Resizable BAR — не опція, а вимога Arc; без нього продуктивність падає. Платформа підійде майже будь-яка сучасна (AM5 або LGA1700), головне — увімкнути ReBAR у BIOS. Топовий CPU не потрібен: усе навантаження на GPU.
Що реально потягне
Сильний бік 12 ГБ — моделі до 14B у квантуванні на одній дешевій карті. Цифри залежать від моделі, кванта й бекенда (заміри llama.cpp/Vulkan, 2025–2026).Модель Квант Влазить у 12 ГБ Швидкість, ток/с Llama / Qwen 7–8B Q8 / легкий квант так ~36 (Q8) … до ~62 DeepSeek R1 distill 14B 4-біт так ~32 (з розгоном) Qwen2.5-coder 14B квант так ~40–44 DeepSeek R1 / Qwen 32B 4-біт ні (потрібно ≥20 ГБ) — Llama 70B будь-який ні —
Ключовий орієнтир — 7B на рівні RTX 3060: Qwen2 7B Q8 іде ~36 токенів/с під Vulkan, рівно як у 3060 на тому самому бекенді; на 8B у легшому кванті llama.cpp видає до ~62. Моделі 14B — робоча стеля: DeepSeek R1 distill 14B у 4-біт — близько 32 ток/с (з розгоном), Qwen2.5-coder 14B — 40–44. Це вже швидше, ніж читає людина, і годиться для кодинг-асистента.

Стеля чесна й жорстка: 32B і більші в 12 ГБ не вміщуються. DeepSeek R1 32B потребує мінімум 20 ГБ відеопам’яті — тобто карту на 24 ГБ, яка коштує в кілька разів дорожче за B580. 70B — тим паче поза досяжністю. Якщо в планах моделі більші за 14B, ця карта не ваш варіант: упретеся в пам’ять майже одразу.
Апаратний плюс під кванти: XMX-рушії Battlemage вміють INT4 на рівні заліза — саме в 4-бітному квантуванні й запускають LLM на 12-ГБ карті, тож прискорення тут не зайве.
Врахуйте й контекст. Довгий діалог наповнює KV-кеш, який теж живе у відеопам’яті й росте в міру розмови. На 12 ГБ це означає, що під велике контекстне вікно у 8–14B-моделі лишається небагато запасу: гігантські вікна на цій карті недоступні без вивантаження в системну RAM — а це різке падіння швидкості (класичний «обрив», коли модель або контекст не вміщуються у відеопам’ять). Практичний режим карти — модель 7–14B з помірним контекстом (4–16K), якого з лишком вистачає для кодинг-асистента й чату. Брати B580 під «довгий контекст на 100K токенів» не варто — це сценарій для карт із великим обсягом.
Arc B580 проти альтернатив
Де B580 виграє ціною, а де варто доплатити (дані на середину 2026).Рішення VRAM Софт Ціна Коли Intel Arc B580 12 ГБ Vulkan/SYCL, IPEX $250–310 найдешевший вхід, 7–14B RTX 3060 (б/в) 12 ГБ CUDA (зріла) $250–300 той самий обсяг, перевірений софт RTX 4060 8 ГБ CUDA $300+ менше пам’яті, але CUDA RX 7900 XTX 24 ГБ ROCm $750–900 якщо потрібен обсяг під 32B+ 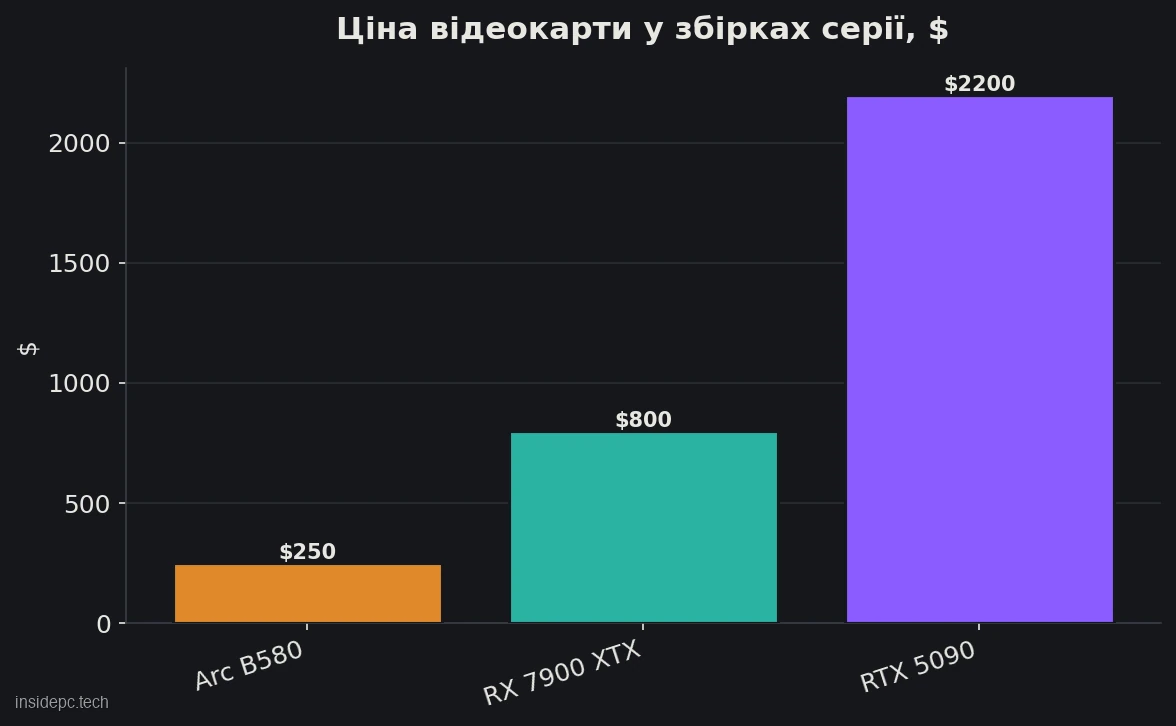
Головна розвилка — B580 проти б/в RTX 3060 12 ГБ. Обсяг пам’яті однаковий, на Vulkan швидкість практично рівна (~36 ток/с на 7B). Але в 3060 є зріла CUDA: на своєму бекенді вона швидша, а головне — софт «просто працює», без танців з бекендами. B580 відповідає тим, що це нова карта з гарантією, трохи швидша в іграх і з активною розробкою Intel. Якщо ринок б/в живий і вам важлива безпроблемність — 3060; якщо хочеться нового заліза і не лякає налаштування — B580.
Проти старших карт серії розклад очевидний: B580 — це підлога за ціною. За збірку на RX 7900 XTX (24 ГБ) просять утричі більше, але вона знімає стелю 12 ГБ. А якщо 12 ГБ перестане вистачати всерйоз — наступний розумний крок — пара б/в RTX 3090 з її 48 ГБ під моделі 32B–70B.
Софт: як узагалі запустити ШІ на Arc
Це розділ, заради якого варто читати огляд: на Arc спотикаються саме на софті, а не на залізі. Головна пастка — стандартний Ollama. Ванільний бінарник Ollama не має нативної підтримки Intel Arc і рахує на процесорі, що б не показував монітор GPU. Людина ставить Ollama «як усі», бачить низьку швидкість і вирішує, що карта слабка. Насправді GPU просто не задіяний.
Робочі шляхи прискорення такі:
- IPEX-LLM (Intel-форк). Intel заархівував репозиторій IPEX-LLM у січні 2026 (нових релізів не буде), але готовий Docker-образ усе ще працює і для щільних (dense) моделей нерідко дає кращу швидкість. Він маршрутизує інференс через SYCL/Level Zero на Xe-ядра.
- llama.cpp. Бекенд Vulkan — найшвидше стартувати (без oneAPI); бекенд SYCL — Intel-нативний, дає помітно вищий throughput генерації (у замірі на Arc — ~+52%), але потребує встановлення oneAPI.
- LM Studio — найпростіший GUI (під капотом Vulkan), і KoboldCpp з Vulkan — частий вибір спільноти за стабільність і квантований KV-кеш.
Висновок тверезий: екосистема Intel «наздоганяє, але не наздогнала». Половина старих гайдів у видачі веде на застарілий IPEX-LLM, частина бекендів швидка на одних моделях і повільна на інших. Це не блокер, але закладіть вечір на підбір зв’язки під свої моделі.
Збірка та налаштування
Практичний мінімум, щоб карта реально рахувала на GPU:
- Resizable BAR. Найперше увімкніть ReBAR у BIOS — для Arc це обов’язкова вимога, без нього швидкість падає.
- ОС і драйвер. Linux — шлях найменшого спротиву (Ubuntu 22.04/24.04, установка драйверів Intel і compute-runtime); на Windows працює через OpenVINO/IPEX, але доведеться боротися з WSL2 і DirectML. Драйвер вирішує: той самий чип на свіжому драйвері прискорюється кратно (у минулого Arc A770 швидкість на 7B зростала з ~11 до ~30 ток/с зі зміною версії).
- Вибір рушія. Почніть із llama.cpp Vulkan або LM Studio — вони запускаються швидко. За максимумом throughput переходьте на SYCL (після oneAPI) або пробуйте IPEX-LLM-образ для dense-моделей. Не використовуйте ванільний Ollama, очікуючи прискорення GPU. Покроковий розбір інференсу (кванти, бекенди) — у розділі локальні нейромережі.
- Живлення та охолодження. TBP 190 Вт — вистачає скромного БЖ на 550–650 Вт. Карта тиха (~30 dBA) і холодна (~73 °C). Нюанси Battlemage: високе споживання в простої (потрібен ASPM), вентилятор може «смикатися» в простої, розгін примхливий.
Апгрейд-шлях
Куди рости, коли 12 ГБ упреться в стелю:
- Карта на 24 ГБ. Найлогічніший крок — перейти на 24 ГБ: б/в RTX 3090 або RX 7900 XTX знімають обмеження й відкривають 32B-моделі, а 3090 у парі — і 70B.
- Друга B580. Технічно дві карти дають 24 ГБ сумарно, але на бюджетному Intel-стеку мультикарта — шлях із граблями (підтримка сира), і простіше доплатити за одну карту з більшим обсягом.
- Хмара під разове важке. Якщо 32B-модель потрібна лише іноді — дешевше орендувати GPU на годину, ніж міняти всю збірку.
Ризики та слабкі місця
Чесний список (з датами):
- Софт-пастка Ollama. Стандартний Ollama не прискорює Arc — рахує на CPU; потрібен IPEX-LLM-образ, llama.cpp (Vulkan/SYCL), LM Studio або KoboldCpp (bibek/localaimaster, 2026).
- Зрілість стека. IPEX-LLM заархівований Intel (01.2026), частина бекендів швидка на одних моделях і повільна на інших — екосистема «наздоганяє, не наздогнала» (bibek/reddit, 2026).
- Стеля 12 ГБ. 32B/70B не запустити — потрібна карта на 24 ГБ у рази дорожче (YouTube Xiao Yang, 2025; decodesfuture, 2026).
- Драйвери вирішують. Продуктивність сильно залежить від версії драйвера (A770: 11→30 ток/с зі зміною) — Battlemage новіший, але та сама залежність (r/LocalLLaMA, 2025).
- Прямий суперник — RTX 3060 12 ГБ. Та сама VRAM, на Vulkan швидкість рівна, але в 3060 зріла CUDA і універсальний софт (reddit/techpowerup, 2026).
- Battlemage-нюанси. PCIe 4.0 ×8, обов’язковий Resizable BAR, високе споживання в простої, примхливий розгін (techpowerup, 2026).
Заради справедливості — плюси вагомі: найнижчий поріг входу (~$250), 12 ГБ проти 8 у суперників за ціною, швидкість на 7–14B на рівні RTX 3060, тиха й холодна карта, активна розробка Intel і апаратний INT4.
Кому підходить, а кому ні
- Беріть Arc B580, якщо у вас жорсткий бюджет ~$250–300, ви хочете увійти в локальний ШІ на моделях 7–14B, готові витратити вечір на підбір бекенда і вам важливіша ціна та 12 ГБ (проти 8 у суперників), ніж безпроблемність.
- Візьміть б/в RTX 3060 12 ГБ, якщо хочете той самий обсяг, але зі зрілою CUDA і софтом, який «просто працює».
- Доплатіть за 24 ГБ (RX 7900 XTX / б/в 3090), якщо потрібні моделі 32B і більші — на 12 ГБ ви упретеся в стелю майже одразу.
- Не беріть B580, якщо ваша ОС — тільки Windows і ви не хочете морочитися: Intel-стек на Linux помітно дружніший.
FAQ
Чи годиться Intel Arc B580 для локальних нейромереж? Так, як бюджетний вхід. 12 ГБ вистачає на моделі 7–8B і 14B у квантуванні зі швидкістю ~32–44 ток/с — приблизно на рівні RTX 3060. Головне обмеження не в карті, а в софті: стандартний Ollama не прискорює Arc, потрібен llama.cpp (Vulkan/SYCL), LM Studio, KoboldCpp або Intel-образ IPEX-LLM.
Які моделі потягне 12 ГБ на Arc B580? Комфортно — 7–8B (до ~62 ток/с у легкому кванті) і 14B у 4-біт (~32–44 ток/с). Моделі 32B і 70B не вміщуються: DeepSeek R1 32B потребує мінімум 20 ГБ, тобто карту на 24 ГБ. Для них потрібен інший бюджет.
Чому Ollama повільно працює на Intel Arc? Тому що стандартний бінарник Ollama не підтримує прискорення Arc і рахує на процесорі, незалежно від того, що показує монітор GPU. Щоб задіяти карту, використовуйте llama.cpp з бекендом Vulkan або SYCL, LM Studio, KoboldCpp або готовий Docker-образ Intel IPEX-LLM.
Arc B580 чи RTX 3060 для ШІ? Обсяг пам’яті однаковий — 12 ГБ, а на бекенді Vulkan швидкість майже рівна (~36 ток/с на 7B). Різниця в екосистемі: у 3060 зріла CUDA, софт працює без налаштування; B580 — новіша, трохи швидша в іграх, але потребує підбору бекенда. Хочете безпроблемність — 3060; хочете нове залізо й не боїтеся мороки — B580.
Скільки коштує Intel Arc B580 у 2026 році? MSRP — $250, але на вулиці нова зазвичай іде трохи вище — $300–310 (ASRock Challenger близько $303–309); б/в на eBay — близько $254, окремі Limited Edition ловлять за ~$200. Повна бюджетна збірка виходить від ~$800 — найдешевший дискретний вхід у локальний ШІ.







