Коротко (TL;DR)
AMD Radeon RX 7900 XTX — це VRAM-за-долар без APU: ті самі 24 ГБ, що в RTX 4090, але за половину ціни. На інференсі вона видає ~75–85% швидкості 4090, а на ходовій Llama 3.1 8B (~96 токенів/с) — практично нарівні з вживаною RTX 3090. Для бюджетного локального ШІ на Linux це сильний аргумент.
Чесна рамка одразу. По-перше, паритет саме з б/в RTX 3090, яка поруч коштує дешевше і на додачу має NVLink. По-друге, ціна платиться не токенами, а часом: ROCm-стек на Linux ставиться за 2–4 години проти <30 хвилин на CUDA, а на Windows він усе ще експериментальний. По-третє, у RDNA 3 немає апаратного FP8 — на нових FP8-моделях карта приблизно вдвічі повільніша. І стеля 24 ГБ жорстка: 70B цілком не влазить.
Ціна (червень 2026): MSRP при запуску був $999, на вулиці нова йде за $750–900 (але за дефіциту на Amazon сягає ~$1 339), б/в — близько $750. Нижче — що саме карта тягне з цифрами, повний BOM AMD-збірки, чесне порівняння з 24-ГБ конкурентами та розбір «доплати часом» на ROCm.
(Дані актуальні на 15 червня 2026; ціни й бенчмарки — з датами в тексті.)

Завдання та бюджет
Ця збірка — для бюджетного локального ШІ на дискретній AMD-карті: чат-асистенти й кодинг на моделях 7–14B, експерименти з 32B у квантуванні, плюс генерація зображень (Stable Diffusion/Flux) як побічний сценарій. Профіль покупця специфічний: Linux-ентузіаст, якому не шкода вечора на налаштування, що вже сидить на платформі AMD (Ryzen/EPYC) або принципово обирає відкритий стек (ROCm — open source під MIT/Apache проти пропрієтарного CUDA).

Бюджет — головний довід. Сама карта коштує $750–900 проти $1 400–1 800 за RTX 4090 за тих самих 24 ГБ. Решта компонентів AMD-збірки (Ryzen, плата AM5, пам’ять, БЖ, корпус) додає ~$960–1 300. Повна станція виходить від ~$1 700, що помітно дешевше за зіставну за пам’яттю збірку на 4090 і робить її найдоступнішою дискретною збіркою серії. Ті самі зекономлені на карті ~$700 — це швидкий NVMe, зайва планка пам’яті або навіть друга така сама карта в перспективі.
Тверезе застереження: якщо ваша ОС — Windows, а в роботі потрібні FP8-моделі, важкий файнтюн чи екосистема CUDA (vLLM на максималках, TensorRT-LLM, ExLlamaV2), ця карта не для вас — переплата за NVIDIA окупиться зекономленим часом.
Конфігурація (BOM)
Збалансована збірка під одну RX 7900 XTX. Карта на 2× 8-pin і 355 Вт — вимоги до живлення помірні, а зв’язка з Ryzen дає Smart Access Memory.Компонент Модель Ціна Навіщо саме це Відеокарта RX 7900 XTX 24 ГБ (Navi 31) $750–900 24 ГБ GDDR6, 960 ГБ/с — ядро збірки Процесор Ryzen 7 9700X / Ryzen 9 9900X ~$300–420 вся робота на GPU; AM5 + SAM Мат. плата B650E / X670E (PCIe 4.0 ×16) ~$180–280 лінії під карту й NVMe Пам’ять 32–64 ГБ DDR5 ~$110–220 під систему й offload-шари 70B Блок живлення 850–1000 Вт ~$120 355 Вт карти + запас Корпус + NVMe з продуванням + 2 ТБ NVMe ~$250 карта гаряча, потрібен потік повітря Разом від ~$1 700 (орієнтир, червень 2026)
Зауваження: процесор навмисно середній — інференс іде на GPU, і топовий CPU тільки додасть тепла. Пам’ять беріть із запасом (64 ГБ), якщо плануєте ганяти 70B з частковим вивантаженням шарів у системну RAM. Корпус із гарним продуванням обов’язковий: референсні «вертушки» карти під навантаженням гучні.
Що реально потягне
Сильний бік 24 ГБ — моделі до 32B у квантуванні на одній карті з пристойною швидкістю. Усі цифри — нативний слот PCIe ×16, контекст 4K, батч 1 (за бенчмарками localaimaster, травень 2026).Модель Квант Влазить у 24 ГБ Швидкість, ток/с Llama 3.2 3B Q5_K_M так, із запасом ~145 Llama 3.1 8B Q5_K_M так ~96 Qwen 2.5 14B Q5_K_M так ~52 Qwen 2.5 32B AWQ-INT4 так, впритул ~28 Llama 3.1 70B Q4_K_M ні (тільки offload) ~7
Ключовий замір — Llama 3.1 8B Q5 (~96 ток/с): це швидше, ніж читає людина, і практично врівень із вживаною RTX 3090 (~95). Моделі 7–14B — комфортна зона карти, 32B в INT4 (~28 ток/с) — робоча стеля «цілком у VRAM».
Чому 4090 не відривається сильніше, хоча за сирими обчисленнями вона потужніша. Латентний інференс упирається в пам’ять, а не в обчислення: пропускна здатність у карт близька (960 проти 1 008 ГБ/с), тому розрив тримається на рівні ~25%, а не «в рази». Звідси й весь сенс XTX: за половину ціни ви отримуєте ~три чверті швидкості топової споживчої карти.
Стеля чесна: Llama 3.1 70B одна карта цілком не вміщує. У Q4_K_M модель важить ~35–40 ГБ — це більше за 24 ГБ, тому працює лише часткове вивантаження шарів на CPU, і швидкість падає до ~7 ток/с. Для повноцінної 70B потрібні дві карти, проф-карта на 48 ГБ або Mac з unified-пам’яттю.
Важливий нюанс довгого контексту: без FlashAttention-2 (порт під gfx1100 з ROCm-форку) швидкість на великих вікнах рушиться — на 16K це 22 ток/с без FA проти 67 з FA-2, а на 32K без нього просто нестача пам’яті. Для AMD це не опція, а обов’язковий крок налаштування.
RX 7900 XTX проти альтернатив
Де AMD виграє грошима, а де варто доплатити за NVIDIA (дані на середину 2026).Рішення VRAM / ПЗ FP8 / NVLink Ціна 8B Q5, ток/с RX 7900 XTX 24 ГБ / 960 ГБ/с ні / ні $750–900 ~96 RTX 3090 (б/в) 24 ГБ / 936 ГБ/с ні / є $650–800 ~95 RTX 4090 24 ГБ / 1 008 ГБ/с є / ні $1 400–1 800 ~127 RTX 5090 32 ГБ / 1 792 ГБ/с є / ні $2 000–2 400 ~210 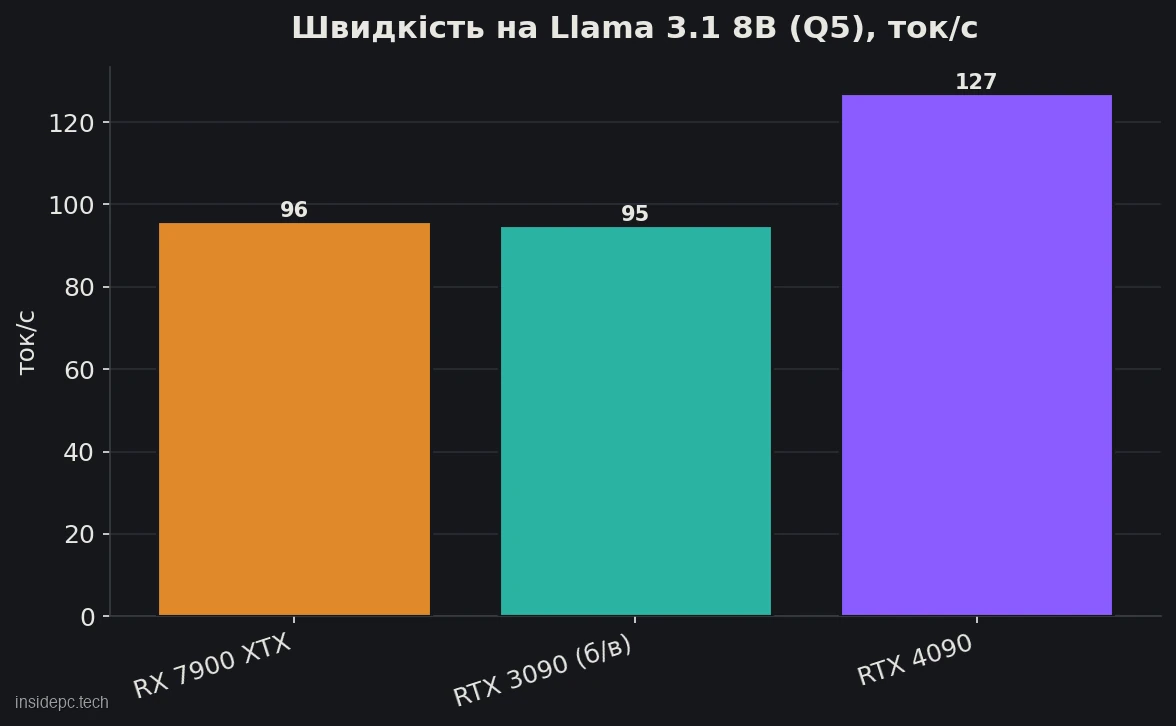
Головна розвилка — не проти 4090, а проти вживаної RTX 3090. За швидкістю на 8B вони ідентичні (96 проти 95), за ціною 3090 навіть трохи дешевша, і в неї є NVLink для майбутньої мультикарти. XTX відповідає тим, що це нова карта з гарантією, нижче енергоспоживання й зрілий відкритий стек на Linux. Якщо ринок б/в 3090 у вас живий і дешевий — беріть збірку на 2× RTX 3090 заради NVLink; якщо важливіше нове залізо й AMD-платформа — XTX.
Проти 4090 розклад суто економічний: ~75% швидкості за ~50% ціни. А якщо в роботі критичний FP8 чи максимальна швидкість — це вже збірка на RTX 5090, інший ціновий клас. Окремо стоїть її собрат за брендом — APU Ryzen AI Max+ 395 (Strix Halo): там ставка зворотна — не швидкість (256 ГБ/с unified), а ємність (до 128 ГБ під великі моделі). Дискретна XTX та APU розв’язують різні задачі: XTX швидша на тому, що влазить у 24 ГБ, Strix Halo бере розміром моделі.
ROCm: за що платиш часом
Найчесніше, що треба знати про AMD для ШІ: розрив із NVIDIA змістився із заліза в софт і час налаштування. Хороша новина — ROCm подорослішав: офіційна підтримка RDNA 3 прийшла в ROCm 5.7 і стала продакшн-грейд у гілці 6.x. Сьогодні на 7900 XTX працюють Ollama, llama.cpp (бекенд HIP), vLLM-ROCm, PyTorch ROCm і ComfyUI; у AMD є навіть офіційний гайд «Running LLMs Locally on AMD GPUs with Ollama». У vLLM швидкість тримається на рівні ~85–90% від CUDA-еквівалента.
Погана новина — «доплата часом» реальна. Чиста установка стека на Linux (драйвер AMDGPU → репозиторій ROCm → rocm-hip-sdk → збірка llama.cpp з GGML_HIP) займає 2–4 години проти <30 хвилин на CUDA, де достатньо поставити драйвер і зробити ollama pull. Системне оновлення може зламати лінкування ROCm-драйвера, тож тримайте нотатки. А на Windows ROCm/HIP лишається експериментальним для більшості LLM-інструментів — для AMD-збірки під ШІ Linux де-факто обов’язковий.
Спільнота підтверджує це без прикрас: власник карти після року експлуатації (ROCm 6.4) пише, що нові моделі нарешті запускаються надійно (gpt-oss-20B — ~94 ток/с у llama.cpp), але досвід «усе ще фрустраційний порівняно з тим, щоб просто увіткнути NVIDIA». Це і є справжня ціна AMD: ви економите сотні доларів, але платите годинами.
Збірка та налаштування
Практичний мінімум, щоб карта запрацювала на інференсі:
- ОС і драйвер. Ubuntu 22.04/24.04, установка ROCm 6.x через
amdgpu-install --usecase=rocm,hiplibsdk. Додайте користувача в групиrenderіvideo, перезавантажтеся, перевіртеrocminfo— має показатиgfx1100, Radeon RX 7900 XTX. - Запуск моделей. Простий шлях — Ollama (
curl … | sh, потімollama run llama3.1:8b): він сам визначає ROCm. Для контролю — llama.cpp, зібраний з-DGGML_HIP=ON -DAMDGPU_TARGETS=gfx1100. Для продакшн-сервінгу — vLLM-ROCm (готовий образrocm/vllm); FP8-ваги не підуть, використовуйте AWQ-INT4. Покроковий розбір інференсу (Ollama, кванти, бекенди) — у розділі локальні нейромережі. - FlashAttention-2. Зберіть порт під
gfx1100з ROCm-форку — без нього довгий контекст рушиться. Після установки-faв llama.cpp і SDPA в PyTorch підхоплюють його автоматично. - Живлення та андервольт. БЖ 850–1000 Вт з урахуванням CPU. Під цілодобовий інференс обмежте потужність до ~290 Вт (
rocm-smi --setpoweroverdrive 290): це ~95% продуктивності, на ~10 °C холодніше й помітно тихіше. - Охолодження. Карта гаряча; референсні моделі гучні — беріть AIB-версії з трьома вентиляторами й забезпечте наскрізне продування корпусу.
Апгрейд-шлях
Куди рости, якщо 24 ГБ перестане вистачати:
- Друга RX 7900 XTX. Дві карти дають 48 ГБ сумарно під 70B в AWQ (tensor-parallel через vLLM, прискорення ~1,5–1,7× на 70B за замірами localaimaster). Важливе застереження: NVLink/Infinity Fabric link у споживчих Radeon немає — карти спілкуються по PCIe 4.0 (~32 ГБ/с проти ~112 у NVLink-моста 3090), і це вузьке місце для all-reduce.
- Зміна платформи під FP8. Якщо вперлися у відсутність FP8 і зрілість CUDA — логічніше не докуповувати другу XTX, а перейти на RTX 5090 (32 ГБ, FP8/FP4) або проф-карту.
- Хмара під піки. Разові важкі задачі (повний 70B, файнтюн) дешевше орендувати, ніж городити мультикарту заради епізодів.
Ризики та слабкі місця
Чесний список (з датами):
- ROCm-тертя. 2–4 години на чистий Linux-setup проти <30 хвилин на CUDA; оновлення системи може зламати драйвер; на Windows стек експериментальний (kunalganglani, 2026).
- Стеля 24 ГБ. 70B цілком не влазить — тільки частковий offload (~7 ток/с); для full-in-VRAM 70B потрібні дві карти, проф-карта або Mac (kunalganglani/localaimaster, 2026).
- Немає FP8 і NVLink. На FP8-моделях карта ~2× повільніша, у vLLM FP8 не працює (тільки AWQ); мультикарта по PCIe замість NVLink (localaimaster, 2026).
- Ціна скаче. Заявлені $750–900, але за дефіциту нова на Amazon сягає ~$1 339, а б/в RTX 3090 поруч дешевша ($650–800) і з NVLink (bestvaluegpu, червень 2026).
- Слабше у файнтюні та image-gen.
bitsandbytes-rocmвідстає від upstream, частина CUDA-залежних нод ComfyUI не працює (localaimaster, 2026).
Заради справедливості — плюси вагомі: ті самі 24 ГБ, що в 4090, за половину ціни; ~75–85% швидкості на інференсі; нова карта з гарантією проти б/в 3090; нижче енергоспоживання; повністю відкритий стек на Linux.
Кому підходить, а кому ні
- Беріть RX 7900 XTX, якщо ви на Linux, хочете найкращі 24 ГБ-за-долар серед нових карт, ганяєте ходові моделі (Llama, Qwen, Mistral) у Q4–Q5, спокійно ставитеся до налаштування ROCm і вам не потрібні FP8/TensorRT-LLM/ExLlamaV2.
- Візьміть б/в RTX 3090, якщо ринок вживаних у вас живий: та сама швидкість, трохи дешевше, плюс NVLink під майбутню мультикарту на 70B.
- Доплатіть за RTX 4090/5090, якщо потрібен FP8, максимальна швидкість або Windows як основна ОС — переплата окупиться часом.
- Дивіться на Strix Halo, якщо важливіша ємність (до 128 ГБ unified під великі моделі), а не швидкість на «малюках».
FAQ
Чи годиться RX 7900 XTX для локальних нейромереж? Так, особливо на Linux із ROCm 6.x. 24 ГБ вистачає для моделей до 32B у квантуванні; Llama 3.1 8B іде ~96 ток/с — практично як у RTX 3090 і близько 75% від RTX 4090, за вдвічі меншої ціни. Головне обмеження — екосистема: налаштування ROCm довше, на Windows стек ще експериментальний.
Які моделі потягне 24 ГБ на RX 7900 XTX? Комфортно — 7–8B у високій точності й 14B у квантуванні, стеля «цілком у VRAM» — 32B в INT4 (~28 ток/с). Llama 3.1 70B у 24 ГБ не вміщується: працює лише часткове вивантаження шарів на CPU зі швидкістю ~7 ток/с. Для повноцінної 70B потрібні дві карти або 48 ГБ на одній.
RX 7900 XTX чи вживана RTX 3090? За швидкістю на ходових моделях вони рівні (~96 проти ~95 ток/с на 8B). XTX — нова, з гарантією, нижче енергоспоживання й відкритий стек; 3090 — дешевша на б/в ринку і з NVLink для мультикарти на 70B. Якщо ринок вживаних живий і потрібен NVLink — 3090; якщо важливіше нове залізо й Linux/AMD — XTX.
Скільки коштує RX 7900 XTX у 2026 році? MSRP при запуску був $999. У середині 2026 нова йде за $750–900, але за дефіциту на Amazon сягає ~$1 339; б/в на eBay — близько $750. Повна AMD-збірка виходить від ~$1 700 — помітно дешевше за зіставну за пам’яттю систему на RTX 4090.
Чи можна запускати LLM на RX 7900 XTX під Windows? Технічно так (через HIP SDK для Windows), але на практиці ROCm там лишається експериментальним для більшості LLM-інструментів: багато фреймворків не дають Windows-збірок або вимагають ручної компіляції. Для AMD-збірки під ШІ рекомендується Linux (Ubuntu 22.04/24.04) — там стек зрілий і стабільний.