Коротко (TL;DR)
AMD Radeon RX 7900 XTX — это VRAM-за-доллар без APU: те же 24 ГБ, что у RTX 4090, но за половину цены. На инференсе она выдаёт ~75–85% скорости 4090, а на ходовой Llama 3.1 8B (~96 токенов/с) — практически наравне с подержанной RTX 3090. Для бюджетного локального ИИ на Linux это сильный аргумент.
Честная рамка сразу. Во-первых, паритет именно с б/у RTX 3090, которая рядом стоит дешевле и вдобавок имеет NVLink. Во-вторых, цена платится не токенами, а временем: ROCm-стек на Linux ставится за 2–4 часа против <30 минут на CUDA, а на Windows он всё ещё экспериментальный. В-третьих, у RDNA 3 нет аппаратного FP8 — на новых FP8-моделях карта примерно вдвое медленнее. И потолок 24 ГБ жёсткий: 70B целиком не влезает.
Цена (июнь 2026): MSRP при запуске был $999, на улице новая идёт за $750–900 (но при дефиците на Amazon доходит до ~$1 339), б/у — около $750. Ниже — что именно карта тянет с цифрами, полный BOM AMD-сборки, честное сравнение с 24-ГБ конкурентами и разбор «доплаты временем» на ROCm.
(Данные актуальны на 15 июня 2026; цены и бенчмарки — с датами в тексте.)

Задача и бюджет
Эта сборка — для бюджетного локального ИИ на дискретной AMD-карте: чат-ассистенты и кодинг на моделях 7–14B, эксперименты с 32B в квантовании, плюс генерация изображений (Stable Diffusion/Flux) как побочный сценарий. Профиль покупателя специфичен: Linux-энтузиаст, которому не жалко вечера на настройку, уже сидящий на платформе AMD (Ryzen/EPYC) или принципиально выбирающий открытый стек (ROCm — open source под MIT/Apache против проприетарного CUDA).

Бюджет — главный довод. Сама карта стоит $750–900 против $1 400–1 800 за RTX 4090 при тех же 24 ГБ. Остальные компоненты AMD-сборки (Ryzen, плата AM5, память, БП, корпус) добавляют ~$960–1 300. Полная станция выходит от ~$1 700, что заметно дешевле сопоставимой по памяти сборки на 4090 и делает её самой доступной дискретной сборкой серии. Те самые сэкономленные на карте ~$700 — это быстрый NVMe, лишняя планка памяти или даже вторая такая же карта в перспективе.
Трезвая оговорка: если ваша ОС — Windows, а в работе нужны FP8-модели, тяжёлый файнтюн или экосистема CUDA (vLLM на максималках, TensorRT-LLM, ExLlamaV2), эта карта не для вас — переплата за NVIDIA окупится сэкономленным временем.
Конфигурация (BOM)
Сбалансированная сборка под одну RX 7900 XTX. Карта на 2× 8-pin и 355 Вт — требования к питанию умеренные, а связка с Ryzen даёт Smart Access Memory.Компонент Модель Цена Зачем именно это Видеокарта RX 7900 XTX 24 ГБ (Navi 31) $750–900 24 ГБ GDDR6, 960 ГБ/с — ядро сборки Процессор Ryzen 7 9700X / Ryzen 9 9900X ~$300–420 вся работа на GPU; AM5 + SAM Мат. плата B650E / X670E (PCIe 4.0 ×16) ~$180–280 линии под карту и NVMe Память 32–64 ГБ DDR5 ~$110–220 под систему и offload-слои 70B Блок питания 850–1000 Вт ~$120 355 Вт карты + запас Корпус + NVMe с продувкой + 2 ТБ NVMe ~$250 карта горячая, нужен поток воздуха Итого от ~$1 700 (ориентир, июнь 2026)
Замечание: процессор намеренно средний — инференс идёт на GPU, и топовый CPU только добавит тепла. Память берите с запасом (64 ГБ), если планируете гонять 70B с частичной выгрузкой слоёв в системную RAM. Корпус с хорошей продувкой обязателен: референсные «вертушки» карты под нагрузкой громкие.
Что реально потянет
Сильная сторона 24 ГБ — модели до 32B в квантовании на одной карте с приличной скоростью. Все цифры — нативный слот PCIe ×16, контекст 4K, батч 1 (по бенчмаркам localaimaster, май 2026).Модель Квант Влезает в 24 ГБ Скорость, ток/с Llama 3.2 3B Q5_K_M да, с запасом ~145 Llama 3.1 8B Q5_K_M да ~96 Qwen 2.5 14B Q5_K_M да ~52 Qwen 2.5 32B AWQ-INT4 да, впритык ~28 Llama 3.1 70B Q4_K_M нет (только offload) ~7
Ключевой замер — Llama 3.1 8B Q5 (~96 ток/с): это быстрее, чем читает человек, и практически вровень с подержанной RTX 3090 (~95). Модели 7–14B — комфортная зона карты, 32B в INT4 (~28 ток/с) — рабочий потолок «целиком в VRAM».

Почему 4090 не отрывается сильнее, хотя по сырым вычислениям она мощнее. Латентный инференс упирается в память, а не в вычисления: пропускная способность у карт близкая (960 против 1 008 ГБ/с), поэтому разрыв держится на уровне ~25%, а не «в разы». Отсюда и весь смысл XTX: за половину цены вы получаете ~три четверти скорости топовой потребкарты.
Потолок честный: Llama 3.1 70B одна карта целиком не вмещает. В Q4_K_M модель весит ~35–40 ГБ — это больше 24 ГБ, поэтому работает только частичная выгрузка слоёв на CPU, и скорость падает до ~7 ток/с. Для полноценной 70B нужны две карты, проф-карта на 48 ГБ или Mac с unified-памятью.
Важный нюанс длинного контекста: без FlashAttention-2 (порт под gfx1100 из ROCm-форка) скорость на больших окнах рушится — на 16K это 22 ток/с без FA против 67 с FA-2, а на 32K без него просто нехватка памяти. Для AMD это не опция, а обязательный шаг настройки.
RX 7900 XTX против альтернатив
Где AMD выигрывает деньгами, а где стоит доплатить за NVIDIA (данные на середину 2026).Решение VRAM / ПС FP8 / NVLink Цена 8B Q5, ток/с RX 7900 XTX 24 ГБ / 960 ГБ/с нет / нет $750–900 ~96 RTX 3090 (б/у) 24 ГБ / 936 ГБ/с нет / есть $650–800 ~95 RTX 4090 24 ГБ / 1 008 ГБ/с есть / нет $1 400–1 800 ~127 RTX 5090 32 ГБ / 1 792 ГБ/с есть / нет $2 000–2 400 ~210 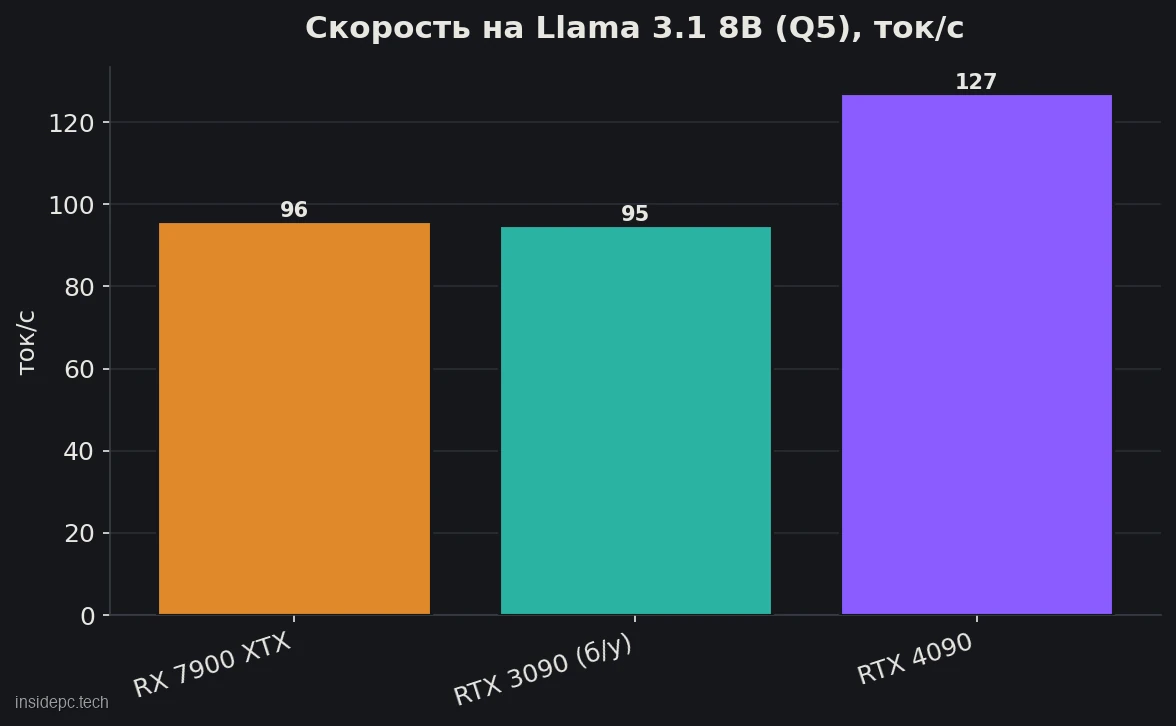
Главная развилка — не против 4090, а против подержанной RTX 3090. По скорости на 8B они идентичны (96 против 95), по цене 3090 даже чуть дешевле, и у неё есть NVLink для будущей мультикарты. XTX отвечает тем, что это новая карта с гарантией, ниже энергопотребление и зрелый открытый стек на Linux. Если рынок б/у 3090 у вас живой и дешёвый — берите сборку на 2× RTX 3090 ради NVLink; если важнее новое железо и AMD-платформа — XTX.
Против 4090 расклад чисто экономический: ~75% скорости за ~50% цены. А если в работе критичен FP8 или максимальная скорость — это уже сборка на RTX 5090, другой ценовой класс. Отдельно стоит её собрат по бренду — APU Ryzen AI Max+ 395 (Strix Halo): там ставка обратная — не скорость (256 ГБ/с unified), а ёмкость (до 128 ГБ под крупные модели). Дискретная XTX и APU решают разные задачи: XTX быстрее на том, что влезает в 24 ГБ, Strix Halo берёт размером модели.
ROCm: за что платишь временем
Самое честное, что нужно знать про AMD для ИИ: разрыв с NVIDIA сместился из железа в софт и время настройки. Хорошая новость — ROCm повзрослел: официальная поддержка RDNA 3 пришла в ROCm 5.7 и стала продакшн-грейд в ветке 6.x. Сегодня на 7900 XTX работают Ollama, llama.cpp (бэкенд HIP), vLLM-ROCm, PyTorch ROCm и ComfyUI; у AMD есть даже официальный гайд «Running LLMs Locally on AMD GPUs with Ollama». В vLLM скорость держится на уровне ~85–90% от CUDA-эквивалента.
Плохая новость — «доплата временем» реальна. Чистая установка стека на Linux (драйвер AMDGPU → репозиторий ROCm → rocm-hip-sdk → сборка llama.cpp с GGML_HIP) занимает 2–4 часа против <30 минут на CUDA, где достаточно поставить драйвер и сделать ollama pull. Системное обновление может сломать линковку ROCm-драйвера, так что держите заметки. А на Windows ROCm/HIP остаётся экспериментальным для большинства LLM-инструментов — для AMD-сборки под ИИ Linux де-факто обязателен.
Сообщество подтверждает это без прикрас: владелец карты после года эксплуатации (ROCm 6.4) пишет, что новые модели наконец запускаются надёжно (gpt-oss-20B — ~94 ток/с в llama.cpp), но опыт «всё ещё фрустрирующий по сравнению с тем, чтобы просто воткнуть NVIDIA». Это и есть настоящая цена AMD: вы экономите сотни долларов, но платите часами.
Сборка и настройка
Практический минимум, чтобы карта заработала на инференсе:
- ОС и драйвер. Ubuntu 22.04/24.04, установка ROCm 6.x через
amdgpu-install --usecase=rocm,hiplibsdk. Добавьте пользователя в группыrenderиvideo, перезагрузитесь, проверьтеrocminfo— должно показатьgfx1100, Radeon RX 7900 XTX. - Запуск моделей. Простой путь — Ollama (
curl … | sh, затемollama run llama3.1:8b): он сам определяет ROCm. Для контроля — llama.cpp, собранный с-DGGML_HIP=ON -DAMDGPU_TARGETS=gfx1100. Для продакшн-сервинга — vLLM-ROCm (готовый образrocm/vllm); FP8-веса не пойдут, используйте AWQ-INT4. Пошаговый разбор инференса (Ollama, кванты, бэкенды) — в разделе локальные нейросети. - FlashAttention-2. Соберите порт под
gfx1100из ROCm-форка — без него длинный контекст рушится. После установки-faв llama.cpp и SDPA в PyTorch подхватывают его автоматически. - Питание и андервольт. БП 850–1000 Вт с учётом CPU. Под круглосуточный инференс ограничьте мощность до ~290 Вт (
rocm-smi --setpoweroverdrive 290): это ~95% производительности, на ~10 °C холоднее и заметно тише. - Охлаждение. Карта горячая; референсные модели шумные — берите AIB-версии с тройным вентилятором и обеспечьте сквозную продувку корпуса.
Апгрейд-путь
Куда расти, если 24 ГБ перестанет хватать:
- Вторая RX 7900 XTX. Две карты дают 48 ГБ суммарно под 70B в AWQ (tensor-parallel через vLLM, ускорение ~1,5–1,7× на 70B по замерам localaimaster). Важная оговорка: NVLink/Infinity Fabric link у потребительских Radeon нет — карты общаются по PCIe 4.0 (~32 ГБ/с против ~112 у NVLink-моста 3090), и это узкое место для all-reduce.
- Смена платформы под FP8. Если упёрлись в отсутствие FP8 и зрелость CUDA — логичнее не докупать вторую XTX, а перейти на RTX 5090 (32 ГБ, FP8/FP4) или проф-карту.
- Облако под пики. Разовые тяжёлые задачи (полный 70B, файнтюн) дешевле арендовать, чем городить мультикарту ради эпизодов.
Риски и слабые места
Честный список (с датами):
- ROCm-трение. 2–4 часа на чистый Linux-setup против <30 минут на CUDA; обновление системы может сломать драйвер; на Windows стек экспериментальный (kunalganglani, 2026).
- Потолок 24 ГБ. 70B целиком не влезает — только частичный offload (~7 ток/с); для full-in-VRAM 70B нужны две карты, проф-карта или Mac (kunalganglani/localaimaster, 2026).
- Нет FP8 и NVLink. На FP8-моделях карта ~2× медленнее, в vLLM FP8 не работает (только AWQ); мультикарта по PCIe вместо NVLink (localaimaster, 2026).
- Цена скачет. Заявленные $750–900, но при дефиците новая на Amazon доходит до ~$1 339, а б/у RTX 3090 рядом дешевле ($650–800) и с NVLink (bestvaluegpu, июнь 2026).
- Слабее в файнтюне и image-gen.
bitsandbytes-rocmотстаёт от upstream, часть CUDA-зависимых нод ComfyUI не работает (localaimaster, 2026).
Справедливости ради — плюсы весомы: те же 24 ГБ, что у 4090, за половину цены; ~75–85% скорости на инференсе; новая карта с гарантией против б/у 3090; ниже энергопотребление; полностью открытый стек на Linux.
Кому подходит, а кому нет
- Берите RX 7900 XTX, если вы на Linux, хотите лучшие 24 ГБ-за-доллар среди новых карт, гоняете ходовые модели (Llama, Qwen, Mistral) в Q4–Q5, спокойно относитесь к настройке ROCm и вам не нужны FP8/TensorRT-LLM/ExLlamaV2.
- Возьмите б/у RTX 3090, если рынок подержанных у вас живой: та же скорость, чуть дешевле, плюс NVLink под будущую мультикарту на 70B.
- Доплатите за RTX 4090/5090, если нужен FP8, максимальная скорость или Windows как основная ОС — переплата окупится временем.
- Смотрите на Strix Halo, если важнее ёмкость (до 128 ГБ unified под крупные модели), а не скорость на «малышах».
FAQ
Годится ли RX 7900 XTX для локальных нейросетей? Да, особенно на Linux с ROCm 6.x. 24 ГБ хватает для моделей до 32B в квантовании; Llama 3.1 8B идёт ~96 ток/с — практически как у RTX 3090 и около 75% от RTX 4090, при вдвое меньшей цене. Главное ограничение — экосистема: настройка ROCm дольше, на Windows стек ещё экспериментальный.
Какие модели потянет 24 ГБ на RX 7900 XTX? Комфортно — 7–8B в высокой точности и 14B в квантовании, потолок «целиком в VRAM» — 32B в INT4 (~28 ток/с). Llama 3.1 70B в 24 ГБ не помещается: работает только частичная выгрузка слоёв на CPU со скоростью ~7 ток/с. Для полноценной 70B нужны две карты или 48 ГБ на одной.
RX 7900 XTX или подержанная RTX 3090? По скорости на ходовых моделях они равны (~96 против ~95 ток/с на 8B). XTX — новая, с гарантией, ниже энергопотребление и открытый стек; 3090 — дешевле на б/у рынке и с NVLink для мультикарты на 70B. Если рынок подержанных живой и нужен NVLink — 3090; если важнее новое железо и Linux/AMD — XTX.
Сколько стоит RX 7900 XTX в 2026 году? MSRP при запуске был $999. В середине 2026 новая идёт за $750–900, но при дефиците на Amazon доходит до ~$1 339; б/у на eBay — около $750. Полная AMD-сборка выходит от ~$1 700 — заметно дешевле сопоставимой по памяти системы на RTX 4090.
Можно ли запускать LLM на RX 7900 XTX под Windows? Технически да (через HIP SDK для Windows), но на практике ROCm там остаётся экспериментальным для большинства LLM-инструментов: многие фреймворки не дают Windows-сборок или требуют ручной компиляции. Для AMD-сборки под ИИ рекомендуется Linux (Ubuntu 22.04/24.04) — там стек зрелый и стабильный.