
Коротко (TL;DR)
Сборка на NVIDIA RTX 5090 — это путь чистой скорости в локальном ИИ. 32 ГБ GDDR7 и 1 792 ГБ/с (на 78% больше, чем у RTX 4090) делают её самой быстрой потребительской картой для инференса: на моделях, которые влезают в 32 ГБ, ей нет равных — Llama 8B бежит ~238 токенов/с, плотная 30B — около 60. Плюс полный CUDA-стек: vLLM, FP8, дообучение — то, чего нет у Apple и AMD.
Но у этой скорости жёсткая граница — 32 ГБ. Плотная Llama 70B (~40 ГБ в 4-бит) на одну карту не влезает; всё, что крупнее, либо не грузится, либо уходит в системную память и теряет ту самую скорость. Как точно подмечено в обзоре XDA, «32 ГБ — не такой высокий потолок, как кажется». И NVLink здесь нет — две карты не дают «64 ГБ одним пулом».
Ещё одна правда — цена. Сама карта почти не продаётся по MSRP $1 999: реально новые идут по $2 500–3 200, у скальперов до $3 000–4 200 (июнь 2026). С остальными компонентами полная сборка выходит в ~$4 300–5 000. Ниже — пошаговый BOM с ценами, таблица «что влезает в 32 ГБ», реальная скорость и честное сравнение с unified-memory.
(Данные актуальны на 15 июня 2026; цены и бенчмарки — с датами в тексте.)
Задача и бюджет
Эта сборка — под быстрый локальный инференс и дообучение моделей до ~30B на одной видеокарте, с полным доступом к экосистеме CUDA (vLLM/SGLang для продакшн-сервинга, QLoRA для тюнинга). Целевые сценарии: кодовый ассистент и чат на максимальной скорости, продакшн-эндпоинт с батчингом, эксперименты и файнтюн 7–30B, плюс генерация изображений/видео (SDXL, Flux). Не цель — запуск моделей крупнее 32 ГБ: для плотных 70B и frontier-MoE нужен другой класс железа.

Бюджет — это полноценный ПК, а не «коробка». Главная статья — сама карта ($2 500–3 200 в рознице), остальное (CPU, плата, память, БП, охлаждение, корпус) добавляет ~$1 800. Итог — около $4 300–5 000 на июнь 2026. Именно розничная цена карты, а не сборка, ломает экономику — об этом в конце.
Конфигурация (BOM)
Сбалансированная конфигурация под локальный ИИ (карта — главное, остальное не должно её бутылочно горлить). Цены — розница на июнь 2026.Компонент Модель Цена Зачем именно это Видеокарта NVIDIA RTX 5090 32 ГБ $2 500–3 200 ядро сборки: 1792 ГБ/с, FP8, CUDA Процессор AMD Ryzen 9 9950X (16 ядер) ~$550 хватает для prefill и пайплайна; X3D под игры не нужен Мат. плата X870/X670E (PCIe 5.0) ~$300 PCIe 5.0 ×16 под карту, питание Память 96 ГБ DDR5-6000 (2×48) ~$280 запас под offload MoE-экспертов в RAM Блок питания 1000–1200 Вт, ATX 3.1 ~$200 575 Вт карты + запас; нативный 12V-2×6 Охлаждение CPU 360-мм AIO ~$110 тихо держит 16 ядер под нагрузкой Корпус + NVMe с продувкой + 2 ТБ NVMe ~$350 airflow критичен (память карты 88–90 °C) Итого ~$4 300–5 000
Замечание по экономии: если игры не нужны, берите обычный 9950X (не X3D) — для ИИ разницы нет, а денег меньше. И не экономьте на БП и продувке — карта на 575 Вт требовательна к питанию и теплу.
Что реально потянет (32 ГБ)
Главный вопрос сборки на 5090 — не скорость, а «влезет ли». 32 ГБ — это много для потребительской карты, но потолок реальный. Ниже — что влезает в 32 ГБ и с какой скоростью (память — Runpod, май 2026; скорость — независимые замеры BIZON/robert-mcdermott).Модель Размер (квант) Влезает в 32 ГБ? Скорость, ток/с Llama 8B / Mistral 7B ~6–7 ГБ (4-бит/FP8) да, с запасом ~238 gpt-oss-20B ~12 ГБ (MXFP4) да ~325 Qwen 32B ~18 ГБ (4-бит) / ~32 (FP8) да ~60 Llama 70B ~35–40 ГБ (4-бит) нет — offload в RAM — Flux.1 Dev (картинки) ~24 ГБ да —
В FP16 веса вдвое тяжелее (8B ~14 ГБ, 13B ~26 ГБ, 32B ~64 ГБ), поэтому крупные модели гоняют в FP8 или 4-бит.
Вывод: комфортный диапазон одной 5090 — модели до ~32B (32B в FP8/4-бит, 13B в FP16, 8B как угодно). А вот плотная 70B на одну карту практически не влезает: даже в 4-бит это ~35–40 ГБ. Втиснуть её можно разве что в агрессивном Q3 с крошечным контекстом, «с большим трудом» — это не рабочий сценарий.
И главное про потолок. Как только модель не помещается в 32 ГБ, она начинает выгружаться в системную DDR5, и вся гигантская пропускная способность карты упирается в скорость обычной оперативки — скорость падает обвально. Поэтому frontier-модели (плотные 70B+, большие MoE вроде Qwen3-Coder-Next на ~85 ГБ) — это уже не про 5090.
Зато 5090 отлично закрывает генеративную графику и видео — область, где ёмкость unified-memory не нужна, а решает скорость. 32 ГБ с запасом тянут полноразмерный SDXL с несколькими ControlNet, Flux.1 Dev (~24 ГБ) и видеогенераторы вроде Wan и CogVideoX без выгрузки в системную память, причём быстрее любой предыдущей потребительской карты. Если сборка задумана не только под текстовые LLM, но и под изображения/видео — это заметный плюс к универсальности и ещё один довод в пользу дискретного GPU против «коробок».
Реальная скорость
На том, что влезает, RTX 5090 — король. Скорость генерации (decode) растёт почти линейно с пропускной способностью, а у 5090 её больше всех среди потребительских карт.
- Llama 8B (Q4): ~238 токенов/с — быстрее, чем вы читаете.
- gpt-oss-20B: ~325 токенов/с.
- Плотная 30B: ~60 токенов/с — «под 30B ничто не сравнится» (Julien Simon, апрель 2026).
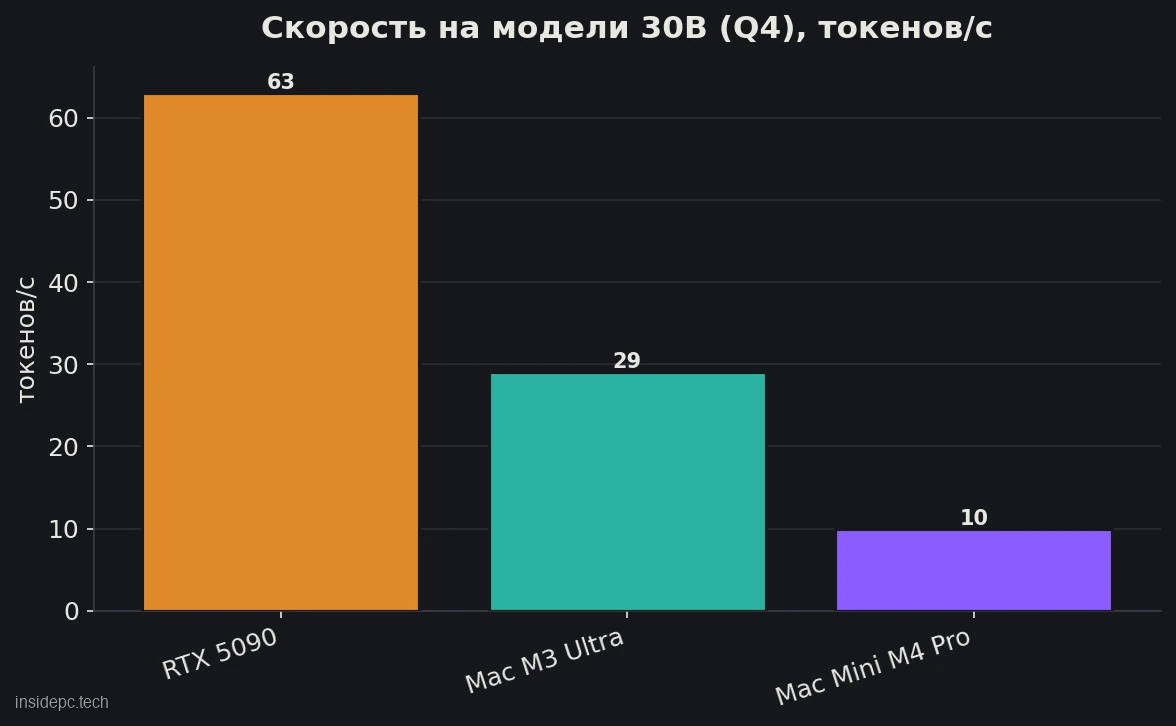
Наглядно это видно на сопоставимой 30B-модели (Qwen3 30B-A3B, замеры BIZON): RTX 5090 выдаёт ~63 ток/с против ~29 у Mac Studio M3 Ultra и ~10 у Mac Mini M4 Pro — на влезающей модели 5090 в 2–6 раз быстрее unified-memory машин. Дополнительный козырь — FP8 на тензор-ядрах Blackwell 5-го поколения: он вдвое экономит память против FP16 (больше моделей и запросов помещается в 32 ГБ) и ускоряет инференс; vLLM и SGLang это используют, llama.cpp — нет.
RTX 5090 против альтернатив
Где 5090 выигрывает, а где нет (данные на июнь 2026).Решение Память / ПС Цена Сильная сторона Сборка на RTX 5090 32 ГБ / 1 792 ГБ/с ~$4 500 (вся сборка) максимум скорости ≤32 ГБ + CUDA RTX 4090 (б/у) 24 ГБ / ~1 008 ГБ/с ~$1 100–1 800 дешевле, если хватает 24 ГБ RTX 3090 (б/у) 24 ГБ / 936 ГБ/с ~$600 бюджетный король VRAM-за-доллар Mac Studio M3 Ultra до 512 ГБ / 819 ГБ/с от $3 999 держит 671B (то, что 5090 не может) Strix Halo (мини-ПК) 128 ГБ / 256 ГБ/с ~$2 350 128 ГБ дёшево и тихо
Главная развилка — скорость против ёмкости. RTX 5090 быстрее любой unified-memory машины на моделях, которые влезают в 32 ГБ, но они её и ограничивают. Mac Studio M3 Ultra медленнее на токенах, зато держит 671B-модель целиком — то, что 5090 не запустит в принципе. Это зеркальный выбор: 5090 — когда модель влезла и нужна максимальная скорость; unified-memory — когда нужна ёмкость под большие модели. Подробный разбор «помощнее по памяти» — в нашем обзоре Mac Studio M3 Ultra, а мини-ПК на Strix Halo — в обзоре Ryzen AI Max+ 395.
Если 24 ГБ хватает, честнее присмотреться к RTX 3090 б/у (~$600) — это консенсусный бюджетный выбор сообщества по VRAM-за-доллар; 5090 берут за скорость, FP8 и +8 ГБ.
Когда брать 4090 вместо 5090: если модели стабильно укладываются в 24 ГБ и максимальная скорость не критична, RTX 4090 (~$1 100–1 800) выгоднее — те же модели, но дешевле. 5090 оправдана, когда модели попадают в зону 24–32 ГБ, где 4090 уже требует агрессивного кванта, либо когда упор именно в пропускную способность и FP8-инференс.
Сборка и настройка
Несколько практических нюансов, без которых сборка не раскроется.
- Питание. 575 Вт TDP плюс процессор — берите БП на 1000 Вт+ (для двух карт 1500 Вт+), желательно ATX 3.1 с нативным разъёмом 12V-2×6, чтобы не городить переходники.
- Охлаждение. Под нагрузкой память карты греется до 88–90 °C — корпус с хорошей продувкой обязателен, иначе термотроттлинг.
- Софт. Для продакшн-сервинга — vLLM (с
--dtype fp8использует тензор-ядра Blackwell), для структурной генерации — SGLang; для локальных экспериментов — llama.cpp/Ollama (GGUF), для дообучения — Transformers + bitsandbytes (QLoRA). Пошаговый разбор инференса (Ollama, кванты, бэкенды) — в разделе локальные нейросети. - Дообучение. 32 ГБ хватает на QLoRA/LoRA-тюнинг моделей 7–30B (30B в 4-бит занимает ~18–20 ГБ) — редкая для потребительского железа возможность дообучать модель под свои данные, недоступная на Apple Silicon. Тюнинг 70B уже вне диапазона одной карты.
- Нюанс экосистемы. Потребительский Blackwell (так называемый SM120: RTX 5090 и RTX PRO 6000) иногда не получает day-0 поддержки в свежих релизах vLLM/SGLang — приоритет у датацентровых H100/B200 (жалоба сообщества, июнь 2026). На стабильных версиях всё работает, но «бегущий край» может подождать пару недель.
Апгрейд-путь
Память карты не наращивается, поэтому путь роста — другой:
- Вторая RTX 5090. Даёт суммарно 64 ГБ и около 55 ток/с на 70B, но с оговорками: NVLink не поддерживается, обмен между картами идёт по PCIe, а у пары 5090 известны проблемы P2P (баг в vLLM, обсуждения на форумах NVIDIA). Это не «64 ГБ одним пулом», а ручной шардинг с граблями — для серьёзного распределённого инференса путь не рекомендуется. Нужно много памяти «как один пул» — логичнее смотреть на unified-memory или датацентровый GPU.
- Аренда вместо второй карты. Прежде чем докупать второй ускоритель, посчитайте загрузку. Карта за $2 500–3 200 плюс электричество и охлаждение окупаются только при постоянной нагрузке — несколько часов инференса или тренировки каждый день. Для редких экспериментов, разовых файнтюнов и всплесковых задач аренда в облаке выходит дешевле: RTX 5090 стоит от ~$0,86/ч (Spheron), без закупки дефицитной карты, апгрейда БП и возни с драйверами. Грубый ориентир: ускоритель простаивает большую часть суток — экономика за аренду; загружен почти постоянно — за покупку.
Риски и слабые места
Честный список (с датами):
- Жёсткий потолок 32 ГБ. Плотная 70B и frontier-MoE не влезают; offload в DDR5 убивает скорость (XDA/Runpod, 2026). Покупать 5090 «ради 70B» — ошибка.
- Нет NVLink. 2× 5090 — это шардинг по PCIe и проблемы P2P, а не единый пул на 64 ГБ (Runpod/GitHub, 2026).
- Цена и доступность. $2 500–3 200 в рознице, до $3 000–4 200 у скальперов против MSRP $1 999 (r/buildapc, июнь 2026) — карта раздувает сборку до ~$4 300–5 000.
- Питание и жар. 575 Вт, БП 1000 Вт+, память 88–90 °C — это шум, тепло в комнате и счёт за электричество.
- Экосистема SM120 отстаёт. Потребительский Blackwell иногда без day-0 поддержки vLLM/SGLang против датацентровых карт (сообщество, июнь 2026).
Справедливости ради — плюсы весомы: это самая быстрая потребительская карта для моделей до 32 ГБ, полный CUDA-стек (vLLM, FP8, QLoRA-тюнинг) недоступный Apple/AMD, отличная генерация картинок и видео, и заодно топовая игровая/рендер-карта — то есть многоцелевая, а не только под ИИ.
Кому подходит, а кому нет
- Соберите ПК на RTX 5090, если ваши модели влезают в 32 ГБ (до ~30–32B), важны максимальная скорость, продакшн-сервинг на vLLM или дообучение, и вы готовы к цене ~$4 500, шуму и теплу.
- Возьмите RTX 3090/4090 (б/у), если хватает 24 ГБ и хочется сэкономить — особенно 3090 за ~$600.
- Идите в unified-memory (Mac Studio / Strix Halo), если нужны модели крупнее 32 ГБ (70B и больше) — там выигрывает ёмкость, а не скорость.
- Арендуйте GPU в облаке, если нагрузка редкая или всплесковая — $4 500 железа окупаются только при постоянной загрузке.
FAQ
Запустит ли RTX 5090 модель Llama 70B? На одной карте — практически нет. Плотная 70B даже в 4-бит весит ~35–40 ГБ и не влезает в 32 ГБ; втиснуть можно разве что в агрессивном Q3 с крошечным контекстом, «с трудом». Рабочие варианты для 70B — две 5090 (с оговорками по PCIe), unified-memory машина или датацентровый GPU. Комфортный потолок одной 5090 — модели до ~32B.
Сколько стоит собрать ПК на RTX 5090 для ИИ? Около $4 300–5 000 на июнь 2026. Основная статья — сама карта ($2 500–3 200 в рознице, дороже у скальперов), остальное (Ryzen 9 9950X, 96 ГБ DDR5, плата X870, БП 1000 Вт+, охлаждение, корпус) — ещё ~$1 800.
RTX 5090 или Mac Studio для локального LLM? Зеркальный выбор. RTX 5090 быстрее на моделях, которые влезают в 32 ГБ (8B ~238, 30B ~60 ток/с), и даёт CUDA-стек. Mac Studio M3 Ultra медленнее на токенах, но держит модели до 671B, которые 5090 не запустит. Влезает в 32 ГБ и нужна скорость — 5090; нужна ёмкость под большие модели — Mac.
Дают ли две RTX 5090 «64 ГБ» для 70B? Не в привычном смысле. NVLink у 5090 нет, поэтому две карты не образуют единый пул — модель шардится по PCIe, а у пары 5090 встречаются проблемы P2P. Технически 70B в 4-бит так запустить можно (~55 ток/с), но для серьёзного распределённого инференса этот путь не рекомендуется.
Какой блок питания нужен для RTX 5090? Минимум 1000 Вт для одной карты (575 Вт TDP плюс процессор и запас), лучше ATX 3.1 с нативным разъёмом 12V-2×6. Для сборки на две карты — 1500 Вт и выше. И обязательно хорошая продувка корпуса: память карты под нагрузкой греется до 88–90 °C.












