Коротко (TL;DR)
Qwen Coder — спеціалізована під програмування лінійка моделей від Alibaba, і на сьогодні це, мабуть, найкращий відкритий кодер для локального запуску. Ідея проста: отримати помічника рівня GitHub Copilot чи Cursor, але на своєму залізі — з повною приватністю коду й без підписки.
- Коротко (TL;DR)
- Лінійка Qwen Coder: від 2.5 до Next
- Скільки потрібно заліза: VRAM, кванти і швидкість
- Запуск: команди Ollama
- Fill-in-the-Middle: як працює автодоповнення
- Підключення до редактора: Continue, Cline та інші
- Налаштування під себе: контекст, температура, режими
- Контекст для цілого репозиторію
- Агентний кодинг: Qwen Code CLI
- Бенчмарки: де Qwen Coder сильний — і чесне застереження
- Qwen Coder проти DeepSeek-Coder, Codestral і Gemma
- Ризики й граблі
- FAQ
- Лінійка під будь-яке залізо. Qwen2.5-Coder іде в розмірах від 0,5B до 32B: маленькі — для миттєвого автодоповнення на відеокарті 8 ГБ, старша 32B — для серйозних задач на карті 24 ГБ. Є й новіші Qwen3-Coder (аж до MoE-варіантів).
- Рівень близько до топу. Qwen2.5-Coder-32B за практичним тестом Aider набирає близько 72,9% — це рівень GPT-4o в коді. Для моделі, яку можна запустити вдома, результат вражає.
- Реальна заміна хмарі. Через розширення на кшталт Continue.dev модель підключається прямо у VS Code і працює як автодоповнення і чат-асистент — але локально, без надсилання коду назовні. Ліцензія — вільна Apache 2.0.
Але без ілюзій: у незалежних тестах Qwen Coder не завжди виграє в конкурентів (про це чесно нижче), а режим «міркувань» для автодоповнення радше заважає. Дані актуальні на 16 червня 2026 року.
Лінійка Qwen Coder: від 2.5 до Next
За «Qwen Coder» стоїть кілька поколінь. Розібратися в них важливо, щоб обрати під своє залізо й задачу.Лінійка Розміри Контекст Особливість Дата Qwen2.5-Coder 0,5B / 1,5B / 3B / 7B / 14B / 32B 32K (до 128K) Робоча конячка, FIM-автодоповнення листопад 2024 Qwen3-Coder-480B 480B / 35B активних (MoE) 256K (до 1M) Флагман для агентного кодингу, сервер липень 2025 Qwen3-Coder-30B 30B (MoE) 256K Версія для однієї карти 24 ГБ 2025–2026 Qwen3-Coder-Next 80B / 3B активних (MoE) великий Ефективний MoE для потужного ПК лютий 2026
Для більшості домашніх задач актуальні Qwen2.5-Coder (перевірена база з морем готових квантів) і Qwen3-Coder-30B (новіший, заходить на 24 ГБ). Гігантська 480B — для серверів і агентних пайплайнів, а Qwen3-Coder-Next цікава тим, що за 80 млрд параметрів активує лише близько 3 млрд, тобто «думає» швидко. Якщо вам потрібен не кодер, а універсальна модель Qwen, у нас є окремий огляд Qwen3 — тут же йдеться лише про код.

Скільки потрібно заліза: VRAM, кванти і швидкість
Це ядро статті. Під кодинг важливо розрізняти три сценарії: автодоповнення (швидкі підказки прямо при наборі — потрібна легка модель), чат-асистент (питання за кодом — модель серйозніша) і агент (модель сама пише й править файли — потрібна найпотужніша).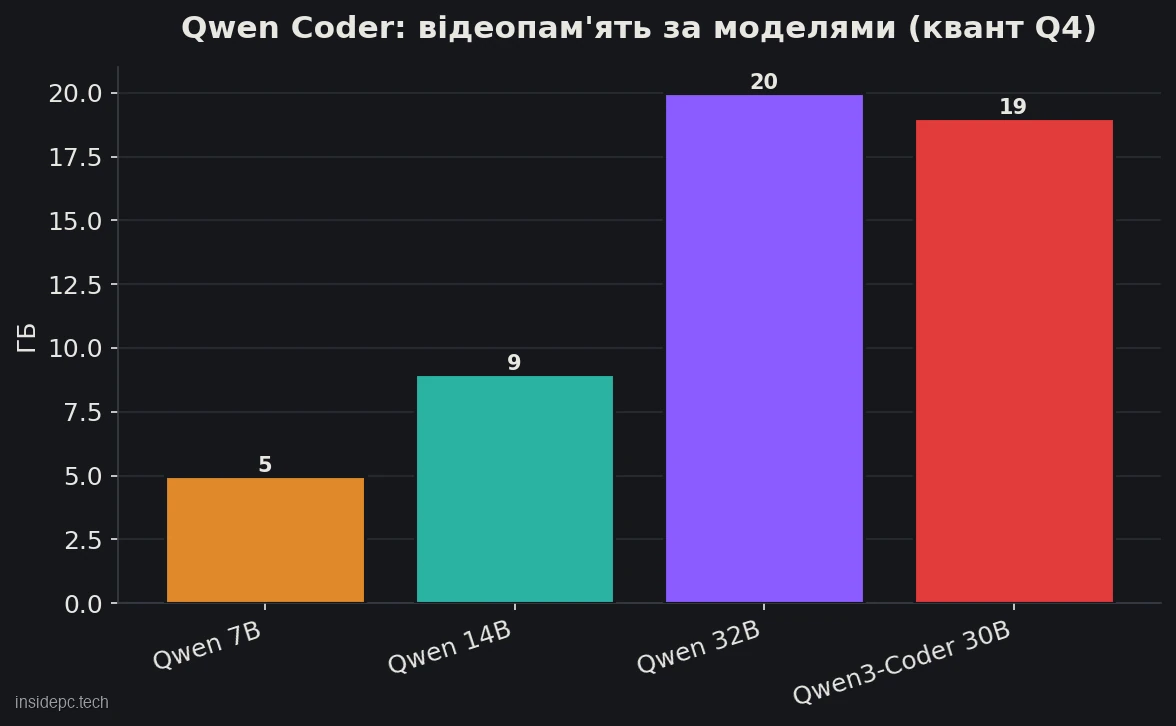
Модель (Q4) VRAM Залізо Для чого Qwen2.5-Coder 7B ~5 ГБ RTX 3060 8 ГБ Автодоповнення, швидкий чат Qwen2.5-Coder 14B ~8,7 ГБ (Q4) / ~14,7 ГБ (Q8) 12–16 ГБ Чат-асистент, складніші задачі Qwen2.5-Coder 32B ~20 ГБ RTX 3090/4090 (24 ГБ) Максимум якості, агент Qwen3-Coder 30B ~19 ГБ RTX 3090/4090 (24 ГБ) Агентний кодинг, 256K контекст

Практичний орієнтир за швидкістю: старша 32B на RTX 4090 видає близько 20–40 токенів/с у чаті, а 14B на карті RTX 4080 у високому кванті — порядку 40–55 (за замірами спільноти, кінець 2025). Для автодоповнення швидкість критична — там беруть легкі 7B, щоб підказка з’являлася миттєво; для вдумливих задач можна потерпіти й повільнішу, але розумну 32B.
Важлива поправка про пам’ять: до розміру ваг додається контекст (KV-кеш), а в кодерів він особливо ненажерливий — моделям часто згодовують великі шматки коду. Якщо хочете працювати з довгим контекстом (цілі файли й репозиторії), закладайте відеопам’ять із запасом.
Якщо обираєте відеокарту під локальний ШІ, відштовхуйтеся від обсягу VRAM — докладний розбір у гіді з вибору GPU для ШІ.
Запуск: команди Ollama
Найпростіший шлях — Ollama (актуальна версія ≥0.5, перевірено за каталогом Ollama, червень 2026):
ollama run qwen2.5-coder:7b # автодоповнення і швидкий чат, 8 ГБ
ollama run qwen2.5-coder:14b # чат-асистент, 12–16 ГБ
ollama run qwen2.5-coder:32b # максимум якості, 24 ГБ
ollama run qwen3-coder:30b # агентний кодинг, 256K контекст
Для автодоповнення в редакторі завантажуйте саме базову версію з підтримкою FIM (теги на кшталт qwen2.5-coder:7b-base), а для чату й агента — instruct-варіант (за замовчуванням). Ollama одразу піднімає локальний API на localhost:11434, сумісний із форматом OpenAI, — саме до нього підключаються розширення редакторів.
LM Studio — графічна альтернатива з каталогом моделей; зручно, якщо не хочете працювати в терміналі. llama.cpp і vLLM — для серверних сценаріїв і роздачі моделі кільком розробникам у команді.
Fill-in-the-Middle: як працює автодоповнення
Головна «фішка» кодерів, якої немає у звичайних чат-моделей, — Fill-in-the-Middle (FIM), доповнення в середині файлу. Коли ви пишете код, курсор стоїть посередині: зверху вже написане, знизу — те, що буде далі. Звичайна модель уміє продовжувати текст, а FIM-модель бачить і те, що до, і те, що після курсора, й акуратно вставляє потрібне в розрив.
Технічно це працює через спеціальні маркери (<|fim_prefix|>, <|fim_suffix|>, <|fim_middle|>), якими редактор обгортає код навколо курсора. Qwen Coder навчений розуміти цей формат — саме тому він дає осмислені підказки, а не просто дописує рядок «наосліп».
Тонкість, про яку варто знати: для автодоповнення беруть базову (base) версію моделі, а не instruct-варіант для чату — base заточена саме під FIM. І окремий нюанс для свіжих Qwen3-Coder: при налаштуванні автодоповнення через деякі розширення FIM-токени доводиться обгортати в чат-формат, інакше підказки не працюють. Якщо зіткнулися — це відома особливість, а не поломка.
Підключення до редактора: Continue, Cline та інші
Локальний кодер марний без інтеграції в редактор. Хороша новина: підключити Qwen Coder до VS Code нескладно, і варіантів багато.
- Continue.dev — найпопулярніше розширення для VS Code і JetBrains. Підключається до локального сервера Ollama, дає й автодоповнення, і чат за кодом. Оптимальна точка входу.
- Cline — розширення для агентного кодингу: модель сама читає й править файли проєкту. Добре розкриває потенціал Qwen3-Coder.
- Cursor і Zed — редактори з вбудованим ШІ, які можна переключити на локальну модель через OpenAI-сумісний API Ollama.
- Qwen Code CLI — офіційний консольний агент від Alibaba (аналог Claude Code і aider), заточений під Qwen3-Coder; працює і з локальною моделлю.
Схема однакова: запускаєте модель в Ollama, вона піднімає локальний сервер на localhost:11434, а розширення вказуєте на цю адресу. Далі код-асистент працює цілком на вашому залізі — ні рядка не йде в хмару.
На практиці в Continue.dev це пара рядків у файлі налаштувань: указуєте провайдера ollama та ім’я моделі — наприклад, qwen2.5-coder:7b-base для автодоповнення і qwen2.5-coder:32b для чату. Після цього підказки з’являються прямо при наборі, а за гарячою клавішею відкривається чат із моделлю за виділеним кодом. Жодних ключів API і оплати — усе локально.
Налаштування під себе: контекст, температура, режими
Кілька параметрів під код.
- Температура. Для коду ставте низьку (0.1–0.2): програмування вимагає точності, а не «творчості». Висока температура частіше веде до вигаданих API та помилок.
- Довжина контексту (num_ctx). Для автодоповнення вистачає невеликого вікна (кілька тисяч токенів навколо курсора) — це швидше й економить пам’ять. Для роботи з великими файлами й репозиторієм піднімайте
num_ctx, пам’ятаючи про витрату відеопам’яті. - Дві моделі під дві задачі. Оптимальна схема — легка base-модель (7B) на автодоповнення заради швидкості й потужна instruct (32B) на чат і складні правки. Continue.dev дозволяє задати їх окремо.
- Без thinking для рутини. Режим міркувань у нових версій корисний для розбору складного алгоритму, але для автодоповнення і слідування інструкціям його краще вимикати.
Локальний запуск дає й неочевидний плюс: код, над яким працює модель, не покидає комп’ютер — це важливо для комерційних і закритих проєктів, де надсилати вихідники в хмарний сервіс не можна за правилами.
Контекст для цілого репозиторію
Один з аргументів на користь свіжих Qwen3-Coder — велике вікно контексту: 256K токенів нативно, а з розширенням (extrapolation) — аж до мільйона. На практиці це означає, що моделі можна «показати» не один файл, а суттєву частину проєкту цілком: вона побачить, як влаштовані сусідні модулі, які є функції та стилі, і дасть підказку з урахуванням усього цього.
Для рутинного автодоповнення стільки не потрібно — там вистачає кількох тисяч токенів навколо курсора. Але для агентних задач (відрефакторити модуль, знайти баг через кілька файлів, додати фічу за аналогією з наявною) великий контекст — серйозна перевага. Платою, як завжди, стає відеопам’ять: довгий контекст її активно витрачає.
Агентний кодинг: Qwen Code CLI
Окремий напрям, під який заточені Qwen3-Coder, — агентний кодинг, коли модель не просто підказує, а сама виконує задачу: читає файли, пише код, запускає команди, виправляє помилки. Для цього Alibaba випустила Qwen Code CLI — консольний інструмент у дусі Claude Code, який уміє працювати в тому числі з локальною моделлю через Ollama.
Сценарій виглядає так: ви формулюєте задачу словами («додай обробку помилок у цей модуль»), а агент сам розбирає проєкт, вносить правки і показує результат. Для домашнього заліза це реалістично з Qwen3-Coder-30B на карті 24 ГБ або з ефективною Qwen3-Coder-Next на потужному ПК. Повноцінна 480B-версія (35 млрд активних при MoE-інференсі) для такого режиму сильніша, але вимагає сервера. Важливо тримати в голові: агент діє автономно, тому працюйте в системі контролю версій (git) і перевіряйте, що він зробив.
Для тих, хто вже знайомий із Claude Code чи aider, перехід на Qwen Code CLI з локальною моделлю буде інтуїтивним: ті самі принципи (агент бачить проєкт, пропонує зміни, застосовує їх за підтвердженням), але без оплати за токени і з кодом, який лишається на вашій машині. Це особливо цінно для пет-проєктів та експериментів, де ганяти платний хмарний агент по дрібницях невигідно.
Бенчмарки: де Qwen Coder сильний — і чесне застереження
За бенчмарками Qwen Coder виглядає відмінно. Найпрактичніший показник — тест Aider, який оцінює реальне редагування коду: Qwen2.5-Coder-32B бере близько 72,9%, що відповідає рівню GPT-4o. Для відкритої моделі на домашній карті це сильний результат. Для порівняння, на строгому SWE-bench Verified (реальні баги з GitHub) середня 14B-версія бере близько 27% — це показує, наскільки такі задачі складніші за навчальні. А суміжна модель тієї самої команди, Qwen3.6 Plus, досягає близько 78,8% на SWE-bench Verified (за даними лідербордів, квітень 2026) — планка росте швидко.
Але тут — обов’язкове чесне застереження, яке більшість оглядів опускає. По-перше, цифри бенчмарків сильно залежать від методики: в однієї й тієї самої 32B результат HumanEval базової версії близько 66%, instruct — за 90%, Aider — 73%. Це не суперечність, а різні тести й різні моделі; орієнтуйтеся на Aider як на найбільш «робочий».
По-друге, реальні тести не завжди підтверджують лідерство. У незалежному розборі на Habr (червень 2026) на відеокарті RTX 5070 Ti з 16 ГБ Gemma 4 обійшла Qwen3-Coder-30B у практичних задачах програмування. Там же з’ясувалося, що увімкнений режим «міркувань» (thinking) погіршував слідування інструкціям. Висновок тверезий: Qwen Coder — один із найкращих, але не безумовний чемпіон на будь-якому залізі; перевіряйте на своїх задачах і не вмикайте thinking для автодоповнення.
І ще важливий для практики висновок: для більшості повсякденних задач — автодоповнення, написання функцій, пояснення чужого коду, налагодження — розрив між топовими відкритими кодерами і хмарними моделями вже невеликий. Платите ви при цьому не підпискою, а один раз за залізо, і код не покидає машину. Саме тому локальний кодер з «іграшки ентузіаста» перетворився на реальний робочий інструмент.
Qwen Coder проти DeepSeek-Coder, Codestral і Gemma
«Найкращого кодера взагалі» не існує — багато що залежить від мови, задачі й заліза. Ось орієнтир за головними відкритими суперниками (станом на червень 2026).Критерій Qwen Coder DeepSeek-Coder Codestral (Mistral) Gemma 4 Якість коду Дуже висока Висока Висока Висока FIM-автодоповнення Так Так Так (заточений) Частково Розміри під дім 0,5B–32B 1,3B–33B 22B 4B–31B Контекст до 256K–1M великий 32K+ до 256K Агентний режим Так (Qwen Code CLI) Обмежено Обмежено Обмежено Ліцензія Apache 2.0 MIT/своя своя (Mistral) Apache 2.0
Де Qwen Coder об’єктивно попереду: широта лінійки, великий контекст і агентний інструментарій. Де варто придивитися до альтернатив: Codestral традиційно сильний саме в автодоповненні, а універсальна Gemma 4, як показав тест вище, в окремих задачах здатна обійти спеціалізований кодер.
Ризики й граблі
- Режим «міркувань» заважає коду. Для автодоповнення і чіткого слідування інструкціям thinking краще вимикати — він сповільнює відповідь і, за тестами, погіршує результат на coding-задачах.
- MXFP4-кванти на відеокартах Blackwell (RTX 50xx). Спільнота (Habr, 2026) повідомляє про аномалії обчислень у деяких MXFP4-збірках Qwen — команда Unsloth навіть прибирала їх зі своїх пакетів. Якщо у вас RTX 50xx, беріть перевірені кванти (Q4_K_M і подібні) й тестуйте стабільність.
- Base або instruct — не переплутайте. Для автодоповнення потрібна базова (FIM) версія, для чату — instruct. Неправильний вибір дає «дивні» підказки.
- Контекст їсть пам’ять. Велике вікно — це зручно, але відеопам’ять витрачається швидко; на довгих контекстах закладайте запас VRAM.
- Походження і ланцюг постачання. Qwen — модель Alibaba; для державних і особливо чутливих середовищ це міркування варто враховувати. І загальна порада: завантажуйте ваги лише з офіційних репозиторіїв (на Hugging Face у минулому знаходили шкідливі «моделі»-підробки).
- Знання обмежені датою навчання. Свіжі бібліотеки й API модель може не знати — для актуального коду перевіряйте підказки й підключайте документацію.
- Перегрів за довгих сесій. Кодинг-агенти надовго навантажують відеокарту — стежте за температурами на компактних збірках.
FAQ
Яку модель Qwen Coder обрати для відеокарти на 8 ГБ? Qwen2.5-Coder 7B у кванті Q4 — вона займає близько 5 ГБ і відмінно підходить для автодоповнення і швидкого чату за кодом. Моделі 14B і 32B на 8 ГБ цілком не помістяться; для них потрібні 12–16 і 24 ГБ відповідно.
Чи може Qwen Coder замінити GitHub Copilot? Для автодоповнення і чату за кодом — багато в чому так: через Continue.dev у VS Code локальний Qwen Coder дає схожий досвід, але безкоштовно і без надсилання коду в хмару. Повністю повторити хмарні агентні функції складніше, але для приватної роботи це реальна альтернатива.
Чим base-версія відрізняється від instruct? Базова (base) версія заточена під Fill-in-the-Middle — автодоповнення в середині файлу, і саме її використовують розширення для підказок. Instruct-версія навчена вести діалог і виконувати інструкції — її беруть для чату та агентних задач. Для автодоповнення ставте base, для спілкування — instruct.
Qwen Coder кращий за DeepSeek-Coder і Gemma? За бенчмарками Qwen Coder — у числі лідерів, але «безумовно найкращий» сказати не можна. У незалежному тесті на 16 ГБ VRAM універсальна Gemma 4 обійшла Qwen3-Coder-30B у реальних задачах. Вибір залежить від мови, задачі й заліза — варто протестувати кандидатів на своїх типових задачах.
Чи потрібно вмикати режим «міркувань» для коду? Для автодоповнення — ні, його краще вимкнути: thinking сповільнює відповідь і, за тестами, погіршує слідування інструкціям у coding-задачах. Для складного розбору алгоритму він може допомогти, але для повсякденної роботи з кодом тримайте його вимкненим.
Скільки місця на диску займе Qwen Coder? Залежить від моделі: 7B у Q4 — близько 5 ГБ, 14B — 9 ГБ, 32B і Qwen3-Coder-30B — порядку 19–20 ГБ. Якщо тримаєте окремо base-версію для автодоповнення та instruct для чату, закладайте 50–80 ГБ вільного місця.
Qwen2.5-Coder чи Qwen3-Coder — що обрати? Qwen2.5-Coder — перевірена база з величезним числом готових квантів і розмірів під будь-яке залізо (від 0,5B до 32B), відмінно підходить для автодоповнення і чату. Qwen3-Coder новіший, заточений під агентний кодинг і великий контекст (256K), але варіанти більші. Для повсякденної роботи в редакторі беріть Qwen2.5-Coder, для агентних задач — Qwen3-Coder-30B.
Чи працює Qwen Coder з кирилицею в коді та коментарях? Так — модель розуміє українські та російські коментарі й описи задач, хоча сам код та ідентифікатори, як заведено, англійською. Для постановки задачі українською («напиши функцію, яка…») Qwen Coder підходить добре: загальна лінійка Qwen сильна в багатомовності.