Коротко (TL;DR)
Framework Desktop — це модульний, ремонтопридатний погляд на Strix Halo: компактний 4,5-літровий Mini-ITX десктоп на AMD Ryzen AI Max+ 395 зі 128 ГБ unified-пам’яті. Від компанії, відомої лагідними ноутбуками, і з її фірмовою ідеологією: стандартний мейнборд можна купити окремо від $799 і поставити у свій корпус, а кілька плат — з’єднати в кластер під моделі, більші за 128 ГБ. Топ-конфіг — від $1 999.
Це та сама платформа, що в базовій статті серії про Ryzen AI Max+ 395 — туди за повним розбором «що тягне Strix Halo». Тут — про сам продукт Framework: чим він кращий за готові бокси, де у «модульності» межа і яка реальна швидкість.
І одразу чесна рамка. По-перше, «модульність» тут про корпус, ввід-вивід і мейнборд, а не про пам’ять: вона розпаяна (32–128 ГБ) і не апгрейдиться — це плата за пропускну здатність 256 ГБ/с. По-друге, купувати Framework Desktop варто заради ємності, а не швидкості: щільна модель 70B впирається в пропускну здатність (~2–4 токени/с), а по-справжньому швидко йдуть MoE-моделі — gpt-oss-120B дає ~30 ток/с проти ~4 у щільної 70B на тій самій машині. І CUDA тут немає.
(Дані актуальні на 15 червня 2026; ціни й бенчмарки — з датами в тексті.)

Завдання та бюджет
Цей десктоп — для DIY-ентузіаста локального ШІ, якому важливі не тільки токени, а й підхід: відкритість, ремонтопридатність, право поставити плату у свій корпус і наростити систему кластером. Типовий сценарій — приватний інференс великих MoE-моделей і робота з довгим контекстом удома, плюс тиха робоча станція «все в одному» для розробки.

Бюджет. Топ-конфігурація (Ryzen AI Max+ 395 / 128 ГБ) стартує від $1 999, повністю укомплектована — близько $2 800. База (Ryzen AI Max 385 / 32 ГБ) — від $1 099, але для ШІ потрібен саме 128-ГБ варіант. Окремий мейнборд — від $799: це і є ключ до кластера чи збірки в нестандартному корпусі. Для локального ШІ беруть версію на 128 ГБ — менше сенсу немає, а розпаяну пам’ять потім не наростити.
Тверезе застереження: якщо важливіша швидкість токенів, ніж ємність, за близькі гроші Mac Studio обжене Strix Halo за рахунок кратно більшої пропускної здатності. Framework беруть за «багато пам’яті задешево» і за модульність, а не за рекорди t/s.
Що таке Framework Desktop
На відміну від запаяного «боксика», Framework Desktop зібраний на максимумі PC-стандартів:
- Mini-ITX мейнборд з ATX-хедерами, слотом PCIe x4 і повним заднім I/O (2× USB4, 2× DisplayPort, HDMI, 5 Гбіт Ethernet) — його можна поставити в будь-який ITX-корпус.
- Карти-розширення Framework (дві спереду, дві ззаду): самі обираєте порти — USB-C, USB-A, аудіоджек, SD-рідер або картридж-накопичувач.
- Стандартні компоненти: 400-Вт блок Flex ATX (з FSP), 120-мм вентилятори (спільно з Cooler Master і Noctua, можна поставити свій), два слоти M.2 2280 до 16 ТБ, Wi-Fi 7.
- DIY Edition: свій накопичувач і ОС. Підтримуються Windows 11 і Linux (Ubuntu, Fedora, ігрові Bazzite/Playtron). За словами Framework, «найпростіший ПК, що ви зберете».
Усередині — APU Ryzen AI Max+ 395 (до 16 ядер Zen5, графіка Radeon 8060S) і до 128 ГБ unified LPDDR5x з пропускною здатністю 256 ГБ/с. У десктопному корпусі чип працює на 120 Вт у постійному навантаженні та 140 Вт у бусті — вище, ніж у ноутбучних боксах, і при цьому тихо.
Що реально потягне
Головна цінність 128 ГБ — вмістити велику модель цілком. Але швидкість генерації залежить від пропускної здатності й від типу моделі, і тут починається найважливіше.Модель Тип Швидкість, ток/с Коментар Llama 8B Q4 щільна ~16 невелика, іде бадьоро DeepSeek-R1 70B щільна ~4,1 влазить, але генерація повільна gpt-oss-120B MoE (5B активних) ~30 sweet spot платформи
Цифри — з однієї і тієї ж машини (Framework Desktop, 128 ГБ). Контрінтуїтивний результат: 120-мільярдна MoE-модель іде в рази швидше за «маленьку» щільну 70B. Причина проста: MoE на кожен токен рахує лише активні параметри (у gpt-oss-120B — близько 5B), а щільна 70B проганяє всі 70 мільярдів. Швидкість генерації майже лінійно залежить від пропускної здатності пам’яті, а її у Strix Halo всього 256 ГБ/с — тому щільні «важкі» моделі впираються в стелю.
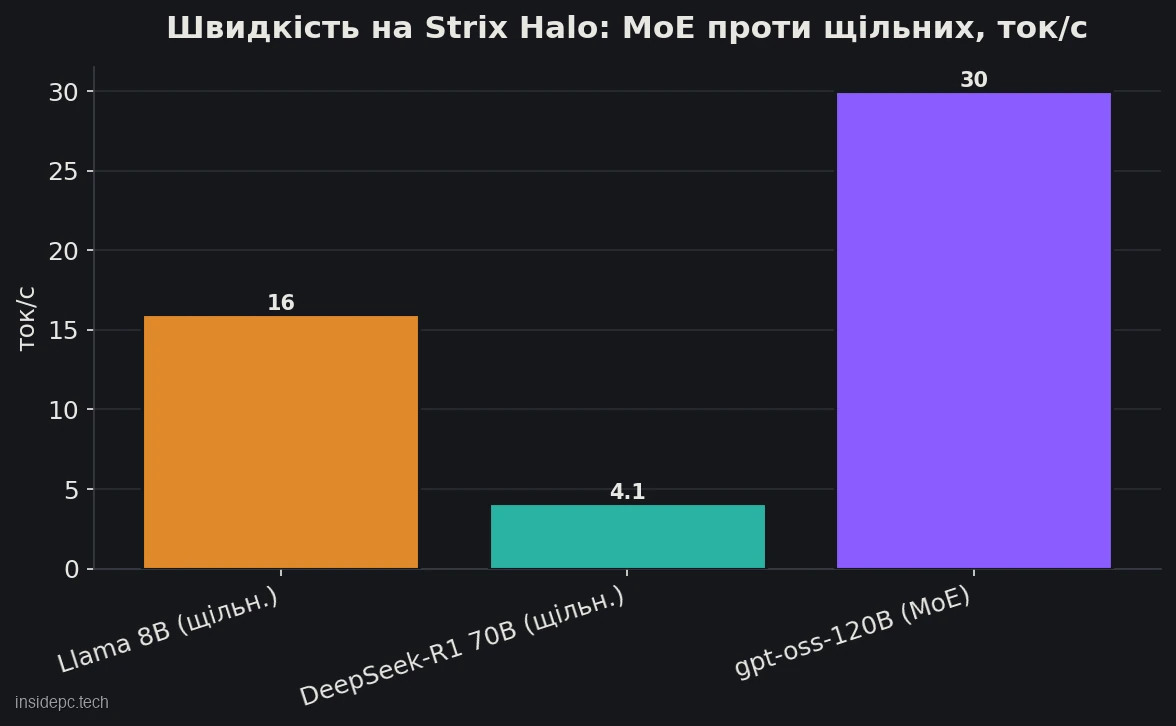
Звідси практичний висновок: Framework Desktop — машина під ємність і MoE, а не під швидкісну щільну генерацію. 128 ГБ дозволяють тримати в пам’яті величезну MoE-модель з великим контекстом — і вона відповідатиме в розмовному темпі. А от маркетингове «Llama 3.3 70B Q6 в реальному часі» варто читати з поправкою: модель справді влазить і працює, але щільна 70B іде ~2–4 ток/с — це годиться для пакетних задач, а не для жвавого чату.
Є й другий нюанс — швидкість обробки промпту (prompt-processing). У Strix Halo небагато «сирого» compute, тому первинна прогонка довгого запиту йде неквапливо. Для звичайного чату це непомітно, але в сценаріях із великими входами — RAG по своїй базі, «глибокий ресерч», пакетна обробка файлів, генерація зображень — затримка до першого токена буде відчутною. Частково це лікує NPU чипа (див. нижче), але саме генерацію токенів він не прискорює. Якщо ваш профіль — довгі входи й батчі, закладайте це в очікування. Повна карта «що тягне Strix Halo» по моделях і квантах — у базовій статті серії.
Головна фішка: материнка окремо і кластер
Ось чого немає в запаяних боксів. Framework продає мейнборд без корпусу від $799, і це відкриває два сценарії.
Перший — свій форм-фактор. Стандартний Mini-ITX ставиться в будь-який корпус: тихий HTPC, ультракомпакт, кастомна стійка. Хочете краще охолодження чи тихіше — берете свій кейс і вентилятори, плата це дозволяє.
Другий, і для ШІ цікавіший, — кластер. Через USB4 і 5 Гбіт Ethernet кілька мейнбордів з’єднуються для запуску моделей, що не влазять у 128 ГБ однієї плати — аж до повної DeepSeek R1 671B. Framework не просто декларує це, а зібрала демонстраційний міні-рек із чотирьох мейнбордів для ШІ-тестів. Для дослідника це шлях нарощувати ємність поступово, а не купувати одразу датацентрову карту.
Економіка кластера теж логічна: замість одного дорогого пристрою з фіксованою пам’яттю ви стартуєте з однієї плати за $799–1 999 і докуповуєте мейнборди в міру зростання задач. Зв’язка по 5-гігабітному Ethernet — не PCIe і не NVLink, тому міжвузловий обмін повільний, і сценарій це радше «вмістити дуже велику модель», ніж «прискорити» її. Але для приватного інференсу 200B–671B вдома без датацентрової карти це робочий і недорогий шлях — спільнота вже ганяє на таких боксах MoE-моделі на сотні мільярдів параметрів.
Саме це відрізняє Framework Desktop від побратимів на тому самому чипі: ви купуєте не «річ у собі», а компонент, який можна розвивати.
Framework проти готових боксів
Чип у всіх боксів Strix Halo один — Ryzen AI Max+ 395, тому стеля продуктивності однакова. Різниця — у виконанні (дані на середину 2026).Рішення 128 ГБ, ціна Сильна сторона Слабка сторона Framework Desktop $1 999 / ~$2 800 терміки, мейнборд окремо, підтримка пам’ять розпаяна GMKtec EVO-X2 ~$1 999–3 299 дешевше в максималці «бурст»-тротлинг, питання до підтримки Mac Studio M4 Max (128 ГБ) ~$3 700 ПЗ 546 ГБ/с (~2× швидше) дорожче, екосистема Apple
Ключова перевага Framework для ШІ — стійкі терміки. У нього десктопне охолодження: за відгуками власників, він «крутить повне навантаження весь день, не виходячи за тепловідведення, не вище ~65 °C». Готовий бокс на кшталт GMKtec EVO-X2 «побудований як ноутбук» — виграє в коротких бенчмарках, але в довгих тротлить і скидає частоти. Для локального інференсу, де модель молотить годинами, це вирішує: важлива не пікова, а сустейн-швидкість.
Другий аргумент — довговічність. Framework (як і HP у цьому класі) дає довгу підтримку BIOS і ремонтопридатність; до дрібних брендів тут питання — оновлення прошивок у них часто припиняються швидко. HP кращий за сервісом, але майже вдвічі дорожчий: «за ціну одного HP беруть майже два Framework».
Збірка та налаштування
Framework Desktop — DIY-машина, але збирається просто; куди важливіше правильно налаштувати софт під Strix Halo.
- Збірка. Якщо взяли систему — додаєте свій M.2-накопичувач і ставите ОС (Windows 11 або Linux; для ШІ зручніший Linux). Якщо взяли мейнборд окремо — ставите його у свій ITX-корпус, підключаєте 400-Вт Flex ATX живлення і 120-мм охолодження.
- Софт — головне. CUDA тут немає, тому шлях інший: бекенд Vulkan (через LM Studio або llama.cpp) — найстабільніший; ROCm для цієї системи поки «в беті» — можливі GPU-зависання й помилки доступу до пам’яті. vLLM теж заводиться. Покроковий розбір інференсу (кванти, бекенди) — у розділі локальні нейромережі.
- NPU — нюанс. У чипа є NPU, але в LLM він сьогодні допомагає тільки в prompt-processing (не в генерації токенів), через lemonade-server і переважно на Windows. На звичайний чат він майже не впливає, але прискорює обробку довгих промптів.
- Вибір моделі. Під цю платформу свідомо беріть MoE-моделі (gpt-oss і подібні) — вони літають; щільні важкі тримайте для пакетних задач, де швидкість не критична.
Ризики та слабкі місця
Чесний список того, що треба прийняти до покупки (з датами):
- Пам’ять розпаяна. LPDDR5x впаяна в плату (32–128 ГБ), наростити потім не можна. Framework чесно пояснює: модульну пам’ять на 256-бітній шині з ПЗ 256 ГБ/с реалізувати технічно не вийшло (128 ГБ дорожче 64 ГБ на $400). Для «модульного» бренду це найспірніший компроміс — беріть обсяг один раз і одразу 128 ГБ (офіц. блог Framework, 2026).
- Пропускна здатність — стеля швидкості. 256 ГБ/с — приблизно третина від Mac Studio M3 Ultra (819 ГБ/с) або б/в RTX 3090 (936 ГБ/с) і в ~7 разів менше, ніж у RTX 5090 (1 792 ГБ/с). Тому Strix Halo сильний ємністю, а не швидкістю щільних моделей. Та сама проблема — у NVIDIA DGX Spark, іншого 128-ГБ unified-конкурента з близькою пропускною здатністю.
- Немає CUDA. Вибір софту звужений: стабільний Vulkan, ROCm для системи «в беті» (можливі GPU-зависання), є vLLM (reddit, кінець 2025).
- Маркетинг «70B в реальному часі» оптимістичний. Щільна 70B іде ~2–4 ток/с — влазить і працює, але не «літає»; розмовний темп дають MoE-моделі (замір vs офіц. заява, 2026).
- Повільний prompt-processing на великих входах. Брак «сирого» compute б’є по RAG, deep-research і пакетній обробці файлів — затримка до першого токена відчутна (reddit, 2025).
- Ціна не «бюджет». Топ-конфіг від $1 999, укомплектований ~$2 800 (на червень 2026); за ту саму ємність Mac швидший по ПЗ, хоч і дорожчий (terminalbytes, 2026).
Заради справедливості — плюси вагомі: 128 ГБ unified задешево, стійкі терміки, мейнборд окремо під свій корпус і кластер, ремонтопридатність і довга підтримка, тиха робота.
Кому підходить, а кому ні
- Беріть Framework Desktop, якщо вам потрібні 128 ГБ unified задешево під MoE-моделі й довгий контекст, важливі модульність, ремонтопридатність і опція «мейнборд окремо» під свій корпус чи кластер, і ви готові до екосистеми без CUDA.
- Зберіть кластер із мейнбордів, якщо впираєтеся в 128 ГБ: USB4/5GbE зв’язують плати під моделі аж до 671B без покупки датацентрової карти.
- Візьміть готовий бокс (EVO-X2), якщо потрібен той самий чип дешевше в максимальній комплектації і вам не критичні сустейн-терміки й довга підтримка.
- Ідіть у Mac Studio, якщо важливіша швидкість токенів: приблизно вдвічі більша пропускна здатність за тієї ж ємності.
- Не беріть Strix Halo взагалі, якщо ваша задача — швидка щільна 70B+ модель: тут потрібна відеопам’ять із високою ПЗ, а не unified на 256 ГБ/с.
FAQ
Чим Framework Desktop відрізняється від звичайного міні-ПК на Strix Halo? Тим самим чипом (Ryzen AI Max+ 395), але іншим підходом: стандартний Mini-ITX мейнборд можна купити окремо (від $799) і поставити у свій корпус чи зібрати кластер, у нього кращі стійкі терміки (повне навантаження весь день при ~65 °C проти «бурст»-тротлингу боксів) і довга підтримка BIOS. Сам APU і пам’ять при цьому такі самі.
Чи можна апгрейдити пам’ять у Framework Desktop? Ні. LPDDR5x розпаяна на платі (32–128 ГБ) і не нарощується — це плата за пропускну здатність 256 ГБ/с, яку на модульній пам’яті отримати не вийшло. Для локального ШІ беріть одразу 128-ГБ версію, потім не додати.
Які моделі реально швидкі на Framework Desktop? MoE-моделі. gpt-oss-120B (близько 5B активних параметрів на токен) іде ~30 ток/с, тоді як щільна DeepSeek-R1 70B на тій самій машині — лише ~4 ток/с. Причина — обмежена пропускна здатність (256 ГБ/с): щільні моделі проганяють усі параметри й упираються в стелю, MoE — тільки активні. Беріть платформу під ємність і MoE.
Чи правда, що Framework Desktop тягне Llama 70B в реальному часі? З поправкою. Модель на 128 ГБ справді влазить і працює, але щільна 70B іде ~2–4 ток/с — це годиться для пакетних і фонових задач, а не для жвавого діалогу. «Розмовний» темп на цій платформі дають саме MoE-моделі.
Framework Desktop чи Mac Studio для локального ШІ? Залежить від пріоритету. Framework дає 128 ГБ unified помітно дешевше (~$2 000–2 800) і плюс модульність із кластером. Mac Studio дорожчий, але його пропускна здатність вища (у M4 Max — 546 проти 256 ГБ/с, близько двох разів) — отже, вища швидкість токенів за тієї ж ємності. Потрібна ємність і DIY — Framework; потрібна швидкість — Mac.