Коротко (TL;DR)
Цей огляд Claude Sonnet 5 — про середню модель Anthropic, яка вийшла 30 червня 2026 і одразу стала моделлю за замовчуванням для безкоштовного та Pro-тарифів. Головний сенс релізу в одній фразі: Sonnet 5 підтягує якість майже до рівня флагмана Opus 4.8, але коштує як звичайний Sonnet. За даними Anthropic, на агентному кодуванні (SWE-bench Pro) модель набирає 63,2% проти 58,1% у Sonnet 4.6 та 69,2% в Opus 4.8, а на тесті реальної офісної роботи GDPval-AA v2 навіть трохи обходить сам Opus 4.8.
- Коротко (TL;DR)
- Що нового в Claude Sonnet 5
- Бенчмарки: Claude Sonnet 5 проти Sonnet 4.6 та Opus 4.8
- Скільки коштує Claude Sonnet 5 і де схована реальна ціна
- Перевірка на завданнях: що показують незалежні тести
- Claude Sonnet 5 проти Opus 4.8 та конкурентів: що обрати
- Доступність, оплата та як почати
- Ризики та обмеження
- FAQ
Кому підходить: розробникам, авторам, аналітикам і бізнесу, яким потрібен сильний «робочий» ШІ для довгих, багатокрокових завдань без флагманського цінника. Кому варто почекати: командам із великим потоком дрібних правок і жорсткими вимогами до швидкості — Sonnet 5 помітно «задумливіший» за попередника. Головний конкурент за ціною та якістю — власний Opus 4.8, а на ринку — OpenAI GPT-5.6 і Google Gemini 3.5.
Ціна API на старті (до 31 серпня 2026): 2 долари за мільйон вхідних токенів і 10 доларів за мільйон вихідних; з 1 вересня 2026 — 3 та 15 доларів. Ідентифікатор моделі — claude-sonnet-5.
Що нового в Claude Sonnet 5
Claude Sonnet 5 — це нове покоління «середньої» лінійки Anthropic, що прийшло на зміну Sonnet 4.6. Anthropic називає її найбільш агентною Sonnet на сьогодні: модель сама будує план, користується інструментами на кшталт браузера й термінала і доводить багатокрокові завдання до кінця там, де попередні Sonnet зупинялися на півдорозі.
Якщо прибрати маркетинг, ключових змін три:

- Адаптивне мислення увімкнене завжди. Модель сама вирішує, скільки «думати» над завданням, а рівень зусиль (effort) можна регулювати аж до вимкнення. На API і в Claude Code за замовчуванням стоїть високий рівень.
- Самоперевірка результату. За відгуками ранніх тестувальників, Sonnet 5 без окремого прохання перевіряє свою роботу: пише тест, проганяє його, шукає й усуває помилку, перш ніж віддати відповідь.
- Новий токенайзер. Той самий текст тепер дробиться на більшу кількість токенів — на цьому ми докладно зупинимось у розділі про ціну, бо це безпосередньо впливає на рахунок.
Характеристики на 30 червня 2026 коротким рядком: контекстне вікно — 1 млн токенів, максимальний вивід — 128 тисяч токенів (до 300 тисяч через бета-режим Batch), поріг навчальних даних — січень 2026, на вході текст і зображення (vision), на виході текст. Це все та сама мультимодальна модель родини Claude, а не окремий «кодинг-рушій».
Окремий контекст релізу: він вийшов у момент, коли два найпотужніші продукти Anthropic — Fable 5 та дослідницький Mythos — потрапили під обмеження через кіберризики (докладніше в нашому розборі, чому Fable 5 і Mythos виявились недоступними). На цьому тлі Anthropic явно подає Sonnet 5 як безпечну робочу конячку: модель спеціально не навчали кібератакам, а захисні фільтри увімкнені за замовчуванням.
Бенчмарки: Claude Sonnet 5 проти Sonnet 4.6 та Opus 4.8
Головне питання до будь-якої нової середньої моделі — наскільки вона відстає від флагмана. За опублікованою Anthropic таблицею бенчмарків Sonnet 5 обходить попередника в усіх тестах і впритул підбирається до Opus 4.8, а в одному тесті навіть обганяє його. Усі цифри нижче — заяви Anthropic на 30 червня 2026; незалежну перевірку дивіться в розділі «Перевірка на завданнях».Бенчмарк (що вимірює) Sonnet 5 Sonnet 4.6 Opus 4.8 SWE-bench Pro (агентне кодування) 63,2% 58,1% 69,2% Terminal-Bench 2.1 (робота в терміналі) 80,4% 67,0% — Humanity’s Last Exam (міркування, з інструментами) 57,4% — 57,9% OSWorld-Verified (керування комп’ютером) 81,2% 78,5% — GDPval-AA v2 (реальна офісна робота, бали) 1618 — 1615 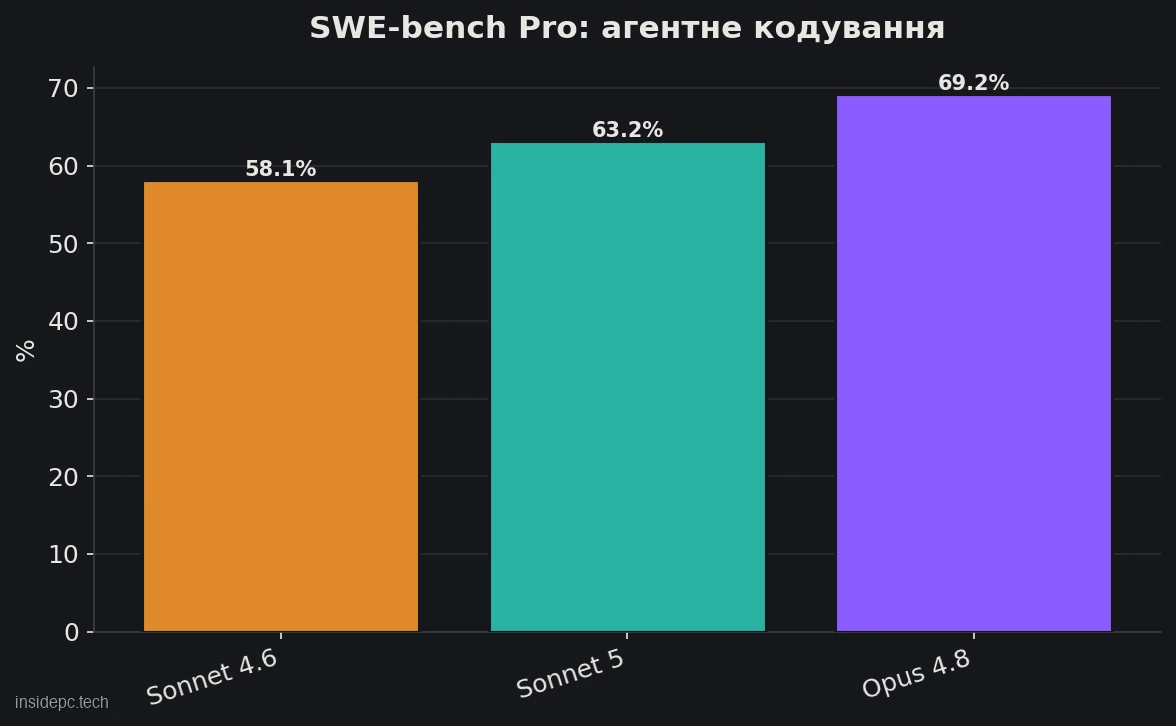
Що з цього випливає. На чистому кодуванні (SWE-bench Pro) розрив із флагманом зберігається: 63,2% проти 69,2% — Opus усе ще попереду, і на найскладніших завданнях це відчувається. Натомість на міркуваннях з інструментами різниця майже зникає (57,4% проти 57,9%), а на тесті реальної офісної роботи GDPval-AA v2 Sonnet 5 формально випереджає дорожчий Opus 4.8 (1618 проти 1615 балів). Для «середньої» моделі це нетипово — зазвичай мід-сегмент програє флагману за всіма фронтами.
Важливе застереження щодо зіставності. Цифри Terminal-Bench 2.1 з таблиці Anthropic не можна напряму порівнювати з тими самими назвами бенчмарків з чужих публікацій: наприклад, у таблиці OpenAI до анонсу GPT-5.6 той самий Terminal-Bench 2.1 дає інші значення та іншу розстановку моделей. Це різні прогони й різні умови тесту, тому коректно порівнювати моделі лише всередині однієї таблиці. Будь-який бенчмарк — це лабораторний вимір, а не гарантія результату на вашому завданні.
Скільки коштує Claude Sonnet 5 і де схована реальна ціна
Ціна API Sonnet 5 на старті нижча, ніж у попередника, але з підступом, про який рідко пишуть. Спершу факти, потім розрахунок.Параметр (API) Sonnet 5 (до 31.08.2026) Sonnet 5 (з 01.09.2026) Opus 4.8 Вхід, за 1M токенів $2 $3 $5 Вихід, за 1M токенів $10 $15 $25 Читання з кешу, за 1M $0,20 $0,30 $0,50 Batch API (вхід / вихід) $1 / $5 $1,5 / $7,5 $2,5 / $12,5
Стандартна ціна Sonnet 5 (3 та 15 доларів) з вересня збігається з ціною Sonnet 4.6 — тобто за прайс-листом нова модель не дорожчає. Вступні 2 та 10 доларів до кінця літа 2026 — це знижка на період переходу.
Тепер підступ. Sonnet 5 використовує новий токенайзер, який дробить той самий текст приблизно на 30% більше токенів (за оцінкою Anthropic — у діапазоні від 1,0 до 1,35 раза залежно від типу контенту). Платите ви за токени, а отже один і той самий запит на Sonnet 5 коштуватиме дорожче, ніж формально показує ціна за мільйон. Anthropic прямо визнає, що вступну знижку виставили так, щоб перехід із 4.6 вийшов приблизно нейтральним за витратами — тобто економія від зниження ціни за токен гаситься зростанням кількості токенів.
Простий розрахунок. Припустімо, завдання на Sonnet 4.6 займало 100 тисяч вхідних і 20 тисяч вихідних токенів. Це 100000 / 1000000 × 3 + 20000 / 1000000 × 15 = 0,3 + 0,3 = 0,60 долара. На Sonnet 5 те саме завдання в токенах зростає приблизно на 30% (до 130 і 26 тисяч). За вступною ціною це 130000 / 1000000 × 2 + 26000 / 1000000 × 10 = 0,26 + 0,26 = 0,52 долара, а за стандартною (з вересня) — 0,39 + 0,39 = 0,78 долара. Висновок: поки діє знижка, перехід виходить трохи дешевшим; після вересня та сама робота на Sonnet 5 обійдеться дорожче, ніж на 4.6 — за рахунок токенайзера. І це ще без урахування того, що агентна модель робить більше кроків і перевірок, тобто витрачає більше токенів сама собою.
Практичний висновок щодо грошей: рахуйте вартість не за ціною за мільйон токенів, а за реальним рахунком на ваших типових завданнях, і обов’язково використовуйте кешування промптів (читання з кешу коштує лише $0,20–0,30 за мільйон) та Batch API для неспішних завдань — там знижка 50%.
Що застаріє в цій статті першим: ціни. Вступна знижка діє лише до 31 серпня 2026, а з 1 вересня тарифи зростуть до $3/$15 — це найближчий дедлайн. Усі дані тут наведені на 30 червня 2026; актуальний прайс завжди дивіться в офіційній таблиці цін Claude Platform.
Перевірка на завданнях: що показують незалежні тести
Цифри вендора — це одне, а поведінка моделі в реальній роботі — інше. Один із перших незалежних розборів зробила команда CodeRabbit, яка прогнала Sonnet 5 через свій фіксований набір пул-реквестів із відомими багами. Картина змішана.
На написанні коду Sonnet 5 — найкраща модель свого класу, яку вони тестували: вона пише тести до самої фічі, проганяє їх і доводить складне завдання до кінця сама, без підштовхування. Така поведінка раніше була доступна лише в дорожчих моделях.
А ось на ревʼю чужого коду вийшов парадокс. Точність коментарів (частка влучань, а не шуму) у Sonnet 5 зросла з приблизно 29% у Sonnet 4.6 до 38–40% — тобто модель стала «чистішою». Але сувора частка спійманих багів при цьому просіла: Sonnet 5 знаходить близько 50–51% багів, тоді як «галасливий» Sonnet 4.6 ловив близько 63%, а власний продакшн-базлайн CodeRabbit — близько 57%. Виходить, старіша 4.6 завалює вас коментарями, але й пропускає менше реальних помилок. Підняття рівня зусиль до максимуму майже не покращувало результат, зате приблизно подвоювало вартість.
Спільнота підтверджує і сильні, і слабкі сторони. На старті Sonnet 5 швидко зʼявився у сторонніх інструментах — наприклад, у Visual Studio та Cursor, — а анонс у профільних спільнотах викликав помітний інтерес. Але лунає й критика: розробники скаржаться, що модель «думає надто довго» і неекономна за токенами на простих завданнях. Тобто та сама прискіпливість, яка допомагає на довгих завданнях, заважає на дрібних.
А що з текстом, українською та російською?
Рубрика «Нейромережі для тексту» — це не лише код, тож окремо про письмо, переклад і роботу з документами. Тут важливе застереження: на день виходу (30 червня 2026) незалежних замірів якості саме української та російської мов ще немає — моделі лише кілька годин. Удавати, що ми «протестували» її на сотні текстів, було б нечесно. Що можна сказати за фактами: уся лінійка Claude традиційно сильна в мультимовних завданнях, контекст у 1 млн токенів дає змогу завантажувати цілі книги й великі документи повністю, а адаптивне мислення допомагає на довгих структурних текстах (лонгриди за ТЗ, розбір документів). Практична порада до накопичення даних: проженіть на Sonnet 5 свої типові тексти самі — статтю за структурою, переклад з ідіомами, резюмування документа — і порівняйте зі звичною моделлю. І враховуйте нюанс токенайзера: за загальною закономірністю токенайзерів кирилиця дробиться на токени важче за латиницю, тож україномовні запити за рахунком, найімовірніше, опиняться ближче до верхньої межі заявленого діапазону зростання — тобто дорожчі за англомовні.
Claude Sonnet 5 проти Opus 4.8 та конкурентів: що обрати
Коротка відповідь: Sonnet 5 закриває більшість робочих завдань, а Opus 4.8 тримайте для найскладнішого. За бенчмарками Anthropic Opus 4.8 попереду на важкому кодуванні (69,2% проти 63,2% на SWE-bench Pro), але коштує у 2,5 раза дорожче на виході ($25 проти $10 за мільйон токенів на 30 червня 2026). Якщо ви платили за флагман лише заради якості — є сенс порівняти Sonnet 5 зі своєю поточною моделлю на реальному навантаженні перед наступним продовженням.
Як орієнтуватися за завданнями:
- Довгі агентні завдання, кодинг «з нуля», автоматизація рутини — Sonnet 5 на середньому рівні зусиль: найкращий баланс ціни та якості.
- Найскладніші та відповідальні завдання, де важлива максимальна точність — Opus 4.8.
- Суворий пошук багів у ревʼю — хоч як дивно, тут старий Sonnet 4.6 поки ловить більше; або комбінуйте моделі.
- Високий потік дрібних правок із жорсткою затримкою — Sonnet 5 поки не найкращий вибір через «задумливість».
На зовнішньому ринку прямі суперники Sonnet 5 — OpenAI GPT-5.6 (лінійка Sol/Terra/Luna) та Google Gemini 3.5. Тут є нюанс доступності: наприклад, публічний реліз GPT-5.6 у США пригальмували на вимогу регулятора, тоді як Sonnet 5 доступний одразу й усім. Коректно порівнювати ці моделі за цифрами складно — у кожної лабораторії свої бенчмарки та свої умови; розумна стратегія у 2026 році — не прив’язуватись до однієї моделі, а маршрутизувати запити за складністю та бюджетом.
Доступність, оплата та як почати
Де доступна. Sonnet 5 з 30 червня 2026 — модель за замовчуванням на безкоштовному та Pro-тарифах Claude, доступна на Max, Team та Enterprise, у Claude Code, а для розробників — через Claude API, AWS, Amazon Bedrock, Google Cloud та Microsoft Foundry. Для нашої аудиторії це важливо: щоб спробувати модель, достатньо зайти на claude.ai — окрема підписка для базового знайомства не потрібна, базовий доступ є й на безкоштовному тарифі.
Як перейти розробнику. Міграція з Sonnet 4.6 у більшості випадків — це заміна ідентифікатора моделі на claude-sonnet-5. Але є три зміни API, на яких легко спіткнутись:
- Ручне розширене мислення (extended thinking) більше не працює — замість нього адаптивне мислення, яке завжди увімкнене; явний виклик старого режиму поверне помилку.
- Нестандартні параметри семплінгу (temperature, top_p, top_k) теж дають помилку — керівні підказки треба переносити в системний промпт.
- Перерахуйте бюджети токенів з урахуванням нового токенайзера (+~30%), інакше впретеся в ліміти раніше, ніж очікували.
Якщо ви користуєтесь Claude у командних інструментах, зверніть увагу й на суміжні продукти Anthropic — наприклад, на Claude Tag, автономного ШІ-колегу для робочих чатів. А приклад великого прикладного завдання на моделях Claude ми розбирали в огляді Claude Design.
Ризики та обмеження
Чесний список слабких місць Sonnet 5 на 30 червня 2026 — те, про що не пишуть у пресрелізах.
- Безпека краща, але не ідеальна. За даними System Card, Sonnet 5 рідше галюцинує й підлещується, ніж 4.6, і краще опирається prompt-інʼєкціям. Але за зведеною оцінкою «небажаної поведінки» (misalignment) модель усе ж гірша, ніж дорожчий Opus 4.8 та дослідницький Mythos Preview. Для критичних сценаріїв це варто враховувати.
- Парадокс ревʼю. Як показано вище, на суворому пошуку багів Sonnet 5 (близько 50–51%) програє навіть власному попереднику 4.6 (близько 63%). Для завдань, де пропущений баг дорого коштує, нова модель — не автоматичний апгрейд.
- Прихований ріст вартості. Токенайзер +30% та агентна багатокроковість означають, що реальний рахунок може зрости, особливо після закінчення вступної знижки 1 вересня 2026.
- Повільність на дрібницях. Модель «задумлива»: на коротких завданнях вона витрачає більше часу й токенів, ніж потрібно. Для високочастотних сценаріїв із жорсткою затримкою це мінус.
- Кібербез-фільтри можуть заважати. Захисні фільтри увімкнені за замовчуванням; легальна робота з безпеки може інколи впиратись у відмови. У тестах на експлойти для Firefox 147 Sonnet 5 не зміг зібрати жодного робочого експлойта (0%), але показав 13,2% часткового успіху — трохи вище, ніж 4.6.
- Приватність і права на контент. Це питання не до самої моделі, а до плану, на якому ви працюєте: умови використання даних на безкоштовному тарифі та в Enterprise відрізняються, і для конфіденційних документів це варто перевірити заздалегідь. Права на згенерований текст і код також визначаються умовами Anthropic, а не «за замовчуванням ваші» — для комерційного використання читайте актуальні умови сервісу.
FAQ
Claude Sonnet 5 кращий за Opus 4.8? Не загалом. За бенчмарками Anthropic Opus 4.8 сильніший на важкому кодуванні (69,2% проти 63,2% на SWE-bench Pro), але Sonnet 5 майже наздоганяє його на міркуваннях і навіть трохи обходить на тесті реальної офісної роботи GDPval-AA v2. При цьому Sonnet 5 у 2,5 раза дешевший на виході. Для більшості завдань вистачить Sonnet 5, Opus залиште для найскладнішого.
Чи варто переходити з Sonnet 4.6 на Sonnet 5? Для написання коду та довгих агентних завдань — так, це помітний крок уперед. Для суворого ревʼю коду та потоку дрібних правок із жорсткими вимогами до швидкості — не поспішайте: 4.6 на ревʼю ловить більше багів і працює швидше. Краще протестувати обидві моделі на своєму навантаженні.
Чому реальний рахунок за Claude Sonnet 5 вищий, ніж ціна за мільйон токенів? Через новий токенайзер: він дробить той самий текст приблизно на 30% більше токенів, а платите ви саме за токени. Тому один і той самий запит обходиться дорожче, ніж підказує прайс. Anthropic спеціально зробила вступну знижку (2 та 10 доларів до 31 серпня 2026) так, щоб перехід із 4.6 був приблизно нейтральним за витратами; після переходу на стандартні 3 та 15 доларів з вересня та сама робота вийде дорожче.
Яке контекстне вікно у Claude Sonnet 5? 1 мільйон токенів, максимальний вивід — 128 тисяч токенів (до 300 тисяч у бета-режимі Batch API). Поріг навчальних даних — січень 2026. Модель приймає на вхід текст і зображення, на виході видає текст.
Чи безкоштовний Claude Sonnet 5? Базово — так: з 30 червня 2026 це модель за замовчуванням на безкоштовному тарифі Claude, спробувати її можна на claude.ai без підписки. Платити потрібно за підвищені ліміти (плани Pro, Max і вище) та за доступ по API, де тарифікація йде за токени.