Коротко (TL;DR)
Этот обзор Claude Sonnet 5 — про среднюю модель Anthropic, которая вышла 30 июня 2026 и сразу стала моделью по умолчанию для бесплатного и Pro-тарифов. Главный смысл релиза в одной фразе: Sonnet 5 подтягивает качество почти к уровню флагмана Opus 4.8, но стоит как обычный Sonnet. По данным Anthropic, на агентном кодировании (SWE-bench Pro) модель набирает 63,2% против 58,1% у Sonnet 4.6 и 69,2% у Opus 4.8, а на тесте реальной офисной работы GDPval-AA v2 даже слегка обходит сам Opus 4.8.
- Коротко (TL;DR)
- Что нового в Claude Sonnet 5
- Бенчмарки: Claude Sonnet 5 против Sonnet 4.6 и Opus 4.8
- Сколько стоит Claude Sonnet 5 и где скрыта реальная цена
- Проверка на задачах: что показывают независимые тесты
- Claude Sonnet 5 против Opus 4.8 и конкурентов: что выбрать
- Доступность, оплата и как начать
- Риски и ограничения
- FAQ
Кому подходит: разработчикам, авторам, аналитикам и бизнесу, которым нужен сильный «рабочий» ИИ для длинных, многошаговых задач без флагманского ценника. Кому стоит подождать: командам с большим потоком мелких правок и жёсткими требованиями к скорости — Sonnet 5 заметно «задумчивее» предшественника. Главный конкурент по цене и качеству — собственный Opus 4.8, а на рынке — OpenAI GPT-5.6 и Google Gemini 3.5.
Цена API на старте (до 31 августа 2026): 2 доллара за миллион входных токенов и 10 долларов за миллион выходных; с 1 сентября 2026 — 3 и 15 долларов. Идентификатор модели — claude-sonnet-5.
Что нового в Claude Sonnet 5
Claude Sonnet 5 — это новое поколение «средней» линейки Anthropic, пришедшее на смену Sonnet 4.6. Anthropic называет её самой агентной Sonnet на сегодня: модель сама строит план, пользуется инструментами вроде браузера и терминала и доводит многошаговые задачи до конца там, где прежние Sonnet останавливались на полпути.
Если убрать маркетинг, ключевых изменений три:

- Адаптивное мышление включено всегда. Модель сама решает, сколько «думать» над задачей, и уровень усилий (effort) можно регулировать вплоть до отключения. На API и в Claude Code по умолчанию стоит высокий уровень.
- Самопроверка результата. По отзывам ранних тестеров, Sonnet 5 без отдельной просьбы перепроверяет свою работу: пишет тест, прогоняет его, ищет и устраняет ошибку, прежде чем отдать ответ.
- Новый токенайзер. Тот же текст теперь дробится на большее число токенов — на этом мы подробно остановимся в разделе про цену, потому что это напрямую влияет на счёт.
Характеристики на 30 июня 2026 короткой строкой: контекстное окно — 1 млн токенов, максимальный вывод — 128 тысяч токенов (до 300 тысяч через бета-режим Batch), порог обучающих данных — январь 2026, на входе текст и изображения (vision), на выходе текст. Это всё та же мультимодальная модель семейства Claude, а не отдельный «кодинг-движок».
Отдельный контекст релиза: он вышел в момент, когда два самых мощных продукта Anthropic — Fable 5 и исследовательский Mythos — попали под ограничения из-за киберрисков (подробнее в нашем разборе, почему Fable 5 и Mythos оказались недоступны). На этом фоне Anthropic явно подаёт Sonnet 5 как безопасную рабочую лошадку: модель специально не обучали кибератакам, а защитные фильтры включены по умолчанию.
Бенчмарки: Claude Sonnet 5 против Sonnet 4.6 и Opus 4.8
Главный вопрос к любой новой средней модели — насколько она отстаёт от флагмана. По опубликованной Anthropic таблице бенчмарков Sonnet 5 обходит предшественника во всех тестах и вплотную подбирается к Opus 4.8, а в одном тесте даже обгоняет его. Все цифры ниже — заявления Anthropic на 30 июня 2026; независимую проверку смотрите в разделе «Проверка на задачах».Бенчмарк (что измеряет) Sonnet 5 Sonnet 4.6 Opus 4.8 SWE-bench Pro (агентное кодирование) 63,2% 58,1% 69,2% Terminal-Bench 2.1 (работа в терминале) 80,4% 67,0% — Humanity’s Last Exam (рассуждения, с инструментами) 57,4% — 57,9% OSWorld-Verified (управление компьютером) 81,2% 78,5% — GDPval-AA v2 (реальная офисная работа, баллы) 1618 — 1615 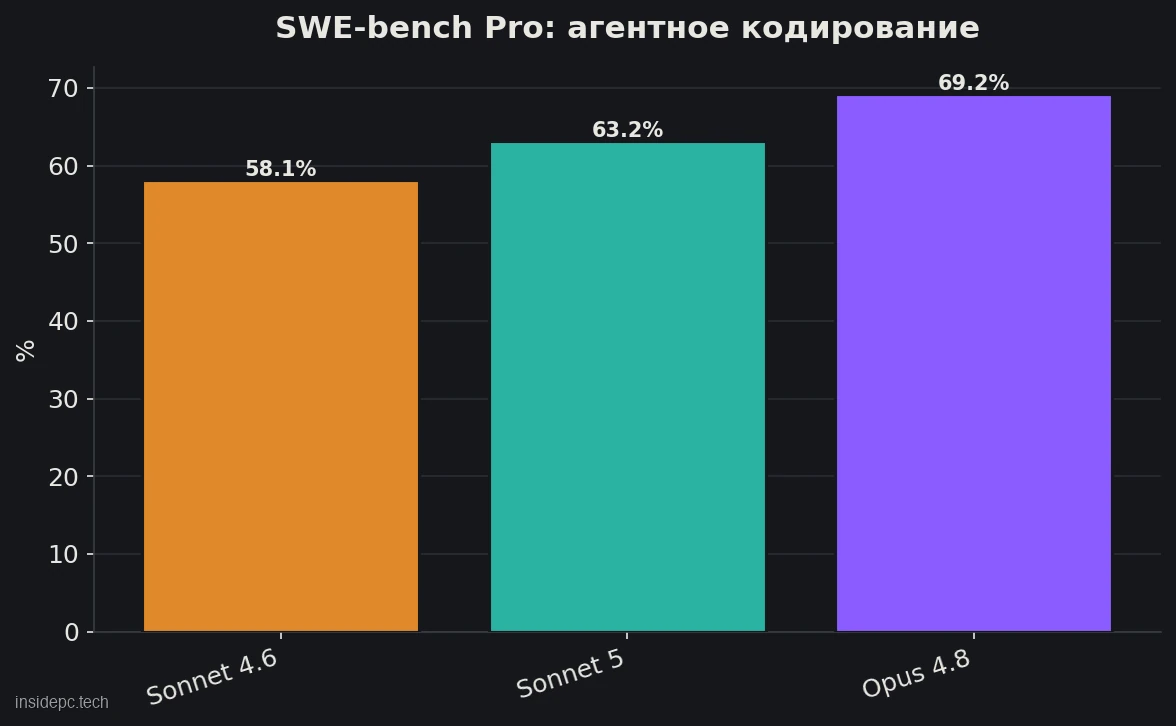
Что из этого следует. На чистом кодировании (SWE-bench Pro) разрыв с флагманом сохраняется: 63,2% против 69,2% — Opus всё ещё впереди, и на самых сложных задачах это чувствуется. Зато на рассуждениях с инструментами разница почти исчезает (57,4% против 57,9%), а на тесте реальной офисной работы GDPval-AA v2 Sonnet 5 формально опережает более дорогой Opus 4.8 (1618 против 1615 баллов). Для «средней» модели это нетипично — обычно мид-сегмент проигрывает флагману по всем фронтам.
Важная оговорка про сопоставимость. Цифры Terminal-Bench 2.1 из таблицы Anthropic нельзя напрямую сравнивать с теми же названиями бенчмарков из чужих публикаций: например, в таблице OpenAI к анонсу GPT-5.6 тот же Terminal-Bench 2.1 даёт другие значения и другую расстановку моделей. Это разные прогоны и разные условия теста, поэтому корректно сравнивать модели только внутри одной таблицы. Любой бенчмарк — это лабораторное измерение, а не гарантия результата на вашей задаче.
Сколько стоит Claude Sonnet 5 и где скрыта реальная цена
Цена API Sonnet 5 на старте ниже, чем у предшественника, но с подвохом, о котором редко пишут. Сначала факты, затем расчёт.Параметр (API) Sonnet 5 (до 31.08.2026) Sonnet 5 (с 01.09.2026) Opus 4.8 Вход, за 1M токенов $2 $3 $5 Выход, за 1M токенов $10 $15 $25 Чтение из кэша, за 1M $0,20 $0,30 $0,50 Batch API (вход / выход) $1 / $5 $1,5 / $7,5 $2,5 / $12,5
Стандартная цена Sonnet 5 (3 и 15 долларов) с сентября совпадает с ценой Sonnet 4.6 — то есть по прайс-листу новая модель не дорожает. Вводные 2 и 10 долларов до конца лета 2026 — это скидка на период перехода.
Теперь подвох. Sonnet 5 использует новый токенайзер, который дробит тот же текст примерно на 30% больше токенов (по оценке Anthropic — в диапазоне от 1,0 до 1,35 раза в зависимости от типа контента). Платите вы за токены, а значит один и тот же запрос на Sonnet 5 будет стоить дороже, чем формально показывает цена за миллион. Anthropic прямо признаёт, что вводную скидку выставили так, чтобы переход с 4.6 получился примерно нейтральным по затратам — то есть экономия от снижения цены за токен гасится ростом числа токенов.
Простой расчёт. Допустим, задача на Sonnet 4.6 занимала 100 тысяч входных и 20 тысяч выходных токенов. Это 100000 / 1000000 × 3 + 20000 / 1000000 × 15 = 0,3 + 0,3 = 0,60 доллара. На Sonnet 5 та же задача в токенах вырастает примерно на 30% (до 130 и 26 тысяч). По вводной цене это 130000 / 1000000 × 2 + 26000 / 1000000 × 10 = 0,26 + 0,26 = 0,52 доллара, а по стандартной (с сентября) — 0,39 + 0,39 = 0,78 доллара. Вывод: пока действует скидка, переход выходит чуть дешевле; после сентября та же работа на Sonnet 5 обойдётся дороже, чем на 4.6 — за счёт токенайзера. И это ещё без учёта того, что агентная модель делает больше шагов и перепроверок, то есть тратит больше токенов сама по себе.
Практический вывод по деньгам: считайте стоимость не по цене за миллион токенов, а по реальному счёту на ваших типовых задачах, и обязательно используйте кэширование промптов (чтение из кэша стоит лишь $0,20–0,30 за миллион) и Batch API для неспешных задач — там скидка 50%.
Что устареет в этой статье первым: цены. Вводная скидка действует только до 31 августа 2026, а с 1 сентября тарифы вырастут до $3/$15 — это ближайший дедлайн. Все данные здесь приведены на 30 июня 2026; актуальный прайс всегда смотрите в официальной таблице цен Claude Platform.
Проверка на задачах: что показывают независимые тесты
Цифры вендора — это одно, а поведение модели в реальной работе — другое. Один из первых независимых разборов сделала команда CodeRabbit, которая прогнала Sonnet 5 через свой фиксированный набор пул-реквестов с известными багами. Картина смешанная.
На написании кода Sonnet 5 — лучшая модель своего класса, которую они тестировали: она пишет тесты до самой фичи, прогоняет их и доводит сложную задачу до конца сама, без подталкивания. Это поведение раньше было доступно только в более дорогих моделях.
А вот на ревью чужого кода вышел парадокс. Точность комментариев (доля попаданий, а не шума) у Sonnet 5 выросла с примерно 29% у Sonnet 4.6 до 38–40% — то есть модель стала «чище». Но строгая доля пойманных багов при этом просела: Sonnet 5 находит около 50–51% багов, тогда как «шумный» Sonnet 4.6 ловил около 63%, а собственный продакшн-базлайн CodeRabbit — около 57%. Получается, более старая 4.6 заваливает вас комментариями, но и пропускает меньше реальных ошибок. Поднятие уровня усилий до максимума почти не улучшало результат, зато примерно удваивало стоимость.
Сообщество подтверждает и сильные, и слабые стороны. На старте Sonnet 5 быстро появился в сторонних инструментах — например, в Visual Studio и Cursor, — а анонс в профильных сообществах вызвал заметный интерес. Но звучит и критика: разработчики жалуются, что модель «думает слишком долго» и неэкономна по токенам на простых задачах. То есть та самая дотошность, которая помогает на длинных задачах, мешает на мелких.
А что с текстом, русским и украинским?
Рубрика «Нейросети для текста» — это не только код, поэтому отдельно про письмо, перевод и работу с документами. Здесь важная оговорка: на день выхода (30 июня 2026) независимых замеров качества именно русского и украинского текста ещё нет — модели всего несколько часов. Делать вид, что мы «протестировали» её на сотне текстов, было бы нечестно. Что можно сказать по фактам: вся линейка Claude традиционно сильна в мультиязычных задачах, контекст в 1 млн токенов позволяет загружать целые книги и большие документы целиком, а адаптивное мышление помогает на длинных структурных текстах (лонгриды по ТЗ, разбор документов). Практический совет до накопления данных: прогоните на Sonnet 5 свои типовые тексты сами — статью по структуре, перевод с идиомами, резюмирование документа — и сравните с привычной моделью. И учитывайте нюанс токенайзера: по общей закономерности токенайзеров кириллица дробится на токены тяжелее латиницы, так что RU/UA-запросы по счёту, скорее всего, окажутся ближе к верхней границе заявленного диапазона роста — то есть дороже англоязычных.
Claude Sonnet 5 против Opus 4.8 и конкурентов: что выбрать
Короткий ответ: Sonnet 5 закрывает большинство рабочих задач, а Opus 4.8 держите для самого сложного. По бенчмаркам Anthropic Opus 4.8 впереди на тяжёлом кодировании (69,2% против 63,2% на SWE-bench Pro), но стоит в 2,5 раза дороже на выходе ($25 против $10 за миллион токенов на 30 июня 2026). Если вы платили за флагман только ради качества — есть смысл сравнить Sonnet 5 со своей текущей моделью на реальной нагрузке перед следующим продлением.
Как ориентироваться по задачам:
- Длинные агентные задачи, кодинг «с нуля», автоматизация рутины — Sonnet 5 на среднем уровне усилий: лучший баланс цены и качества.
- Самые сложные и ответственные задачи, где важна максимальная точность — Opus 4.8.
- Строгий поиск багов в ревью — как ни странно, здесь старый Sonnet 4.6 пока ловит больше; либо комбинируйте модели.
- Высокий поток мелких правок с жёсткой задержкой — Sonnet 5 пока не лучший выбор из-за «задумчивости».
На внешнем рынке прямые соперники Sonnet 5 — OpenAI GPT-5.6 (линейка Sol/Terra/Luna) и Google Gemini 3.5. Здесь есть нюанс доступности: например, публичный релиз GPT-5.6 в США притормозили по требованию регулятора, тогда как Sonnet 5 доступен сразу и всем. Корректно сравнивать эти модели по цифрам сложно — у каждой лаборатории свои бенчмарки и свои условия; разумная стратегия в 2026 году — не привязываться к одной модели, а маршрутизировать запросы по сложности и бюджету.
Доступность, оплата и как начать
Где доступна. Sonnet 5 с 30 июня 2026 — модель по умолчанию на бесплатном и Pro-тарифах Claude, доступна на Max, Team и Enterprise, в Claude Code, а для разработчиков — через Claude API, AWS, Amazon Bedrock, Google Cloud и Microsoft Foundry. Для нашей аудитории это важно: чтобы попробовать модель, достаточно зайти на claude.ai — отдельная подписка для базового знакомства не нужна, базовый доступ есть и на бесплатном тарифе.
Как перейти разработчику. Миграция с Sonnet 4.6 в большинстве случаев — это замена идентификатора модели на claude-sonnet-5. Но есть три изменения API, на которых легко споткнуться:
- Ручное расширенное мышление (extended thinking) больше не работает — вместо него адаптивное мышление, которое всегда включено; явный вызов старого режима вернёт ошибку.
- Нестандартные параметры сэмплинга (temperature, top_p, top_k) тоже дают ошибку — управляющие подсказки нужно переносить в системный промпт.
- Пересчитайте бюджеты токенов с учётом нового токенайзера (+~30%), иначе упрётесь в лимиты раньше, чем ожидали.
Если вы пользуетесь Claude в командных инструментах, обратите внимание и на смежные продукты Anthropic — например, на Claude Tag, автономного ИИ-коллегу для рабочих чатов. А пример большой прикладной задачи на моделях Claude мы разбирали в обзоре Claude Design.
Риски и ограничения
Честный список слабых мест Sonnet 5 на 30 июня 2026 — то, о чём не пишут в пресс-релизах.
- Безопасность лучше, но не идеальна. По данным System Card, Sonnet 5 реже галлюцинирует и подхалимничает, чем 4.6, и лучше сопротивляется prompt-инъекциям. Но по сводной оценке «нежелательного поведения» (misalignment) модель всё же хуже, чем более дорогой Opus 4.8 и исследовательский Mythos Preview. Для критичных сценариев это стоит учитывать.
- Парадокс ревью. Как показано выше, на строгом поиске багов Sonnet 5 (около 50–51%) проигрывает даже собственному предшественнику 4.6 (около 63%). Для задач, где пропущенный баг дорого стоит, новая модель — не автоматический апгрейд.
- Скрытый рост стоимости. Токенайзер +30% и агентная многошаговость означают, что реальный счёт может вырасти, особенно после окончания вводной скидки 1 сентября 2026.
- Медлительность на мелочах. Модель «задумчивая»: на коротких задачах она тратит больше времени и токенов, чем нужно. Для высокочастотных сценариев с жёсткой задержкой это минус.
- Кибербез-фильтры могут мешать. Защитные фильтры включены по умолчанию; легальная работа по безопасности может иногда упираться в отказы. В тестах на эксплойты для Firefox 147 Sonnet 5 не смог собрать ни одного рабочего эксплойта (0%), но показал 13,2% частичного успеха — чуть выше, чем 4.6.
- Приватность и права на контент. Это вопрос не к самой модели, а к плану, на котором вы работаете: условия использования данных на бесплатном тарифе и в Enterprise отличаются, и для конфиденциальных документов это стоит проверить заранее. Права на сгенерированный текст и код также определяются условиями Anthropic, а не «по умолчанию ваши» — для коммерческого использования читайте актуальные условия сервиса.
FAQ
Claude Sonnet 5 лучше, чем Opus 4.8? Не в целом. По бенчмаркам Anthropic Opus 4.8 сильнее на тяжёлом кодировании (69,2% против 63,2% на SWE-bench Pro), но Sonnet 5 почти догоняет его на рассуждениях и даже немного обходит на тесте реальной офисной работы GDPval-AA v2. При этом Sonnet 5 в 2,5 раза дешевле на выходе. Для большинства задач хватит Sonnet 5, Opus оставьте для самого сложного.
Стоит ли переходить с Sonnet 4.6 на Sonnet 5? Для написания кода и длинных агентных задач — да, это заметный шаг вперёд. Для строгого ревью кода и потока мелких правок с жёсткими требованиями к скорости — не торопитесь: 4.6 на ревью ловит больше багов и работает быстрее. Лучше протестировать обе модели на своей нагрузке.
Почему реальный счёт за Claude Sonnet 5 выше, чем цена за миллион токенов? Из-за нового токенайзера: он дробит тот же текст примерно на 30% больше токенов, а платите вы именно за токены. Поэтому один и тот же запрос обходится дороже, чем подсказывает прайс. Anthropic специально сделала вводную скидку (2 и 10 долларов до 31 августа 2026) так, чтобы переход с 4.6 был примерно нейтральным по затратам; после перехода на стандартные 3 и 15 долларов с сентября та же работа выйдет дороже.
Какое контекстное окно у Claude Sonnet 5? 1 миллион токенов, максимальный вывод — 128 тысяч токенов (до 300 тысяч в бета-режиме Batch API). Порог обучающих данных — январь 2026. Модель принимает на вход текст и изображения, на выходе выдаёт текст.
Бесплатен ли Claude Sonnet 5? Базово — да: с 30 июня 2026 это модель по умолчанию на бесплатном тарифе Claude, попробовать её можно на claude.ai без подписки. Платить нужно за повышенные лимиты (планы Pro, Max и выше) и за доступ по API, где тарификация идёт за токены.