
Коротко (TL;DR)
Збірка на NVIDIA RTX 5090 — це шлях чистої швидкості в локальному ШІ. 32 ГБ GDDR7 і 1 792 ГБ/с (на 78% більше, ніж у RTX 4090) роблять її найшвидшою споживчою картою для інференсу: на моделях, що влазять у 32 ГБ, їй немає рівних — Llama 8B біжить ~238 токенів/с, щільна 30B — близько 60. Плюс повний CUDA-стек: vLLM, FP8, донавчання — те, чого немає в Apple і AMD.
Але в цієї швидкості жорстка межа — 32 ГБ. Щільна Llama 70B (~40 ГБ у 4-біт) на одну карту не влазить; усе, що більше, або не вантажиться, або йде в системну пам’ять і втрачає ту саму швидкість. Як влучно підмічено в огляді XDA, «32 ГБ — не така висока стеля, як здається». І NVLink тут немає — дві карти не дають «64 ГБ одним пулом».
Ще одна правда — ціна. Сама карта майже не продається за MSRP $1 999: реально нові йдуть по $2 500–3 200, у скальперів до $3 000–4 200 (червень 2026). З рештою компонентів повна збірка виходить у ~$4 300–5 000. Нижче — покроковий BOM з цінами, таблиця «що влазить у 32 ГБ», реальна швидкість і чесне порівняння з unified-memory.
(Дані актуальні на 15 червня 2026; ціни та бенчмарки — з датами в тексті.)
Завдання і бюджет
Ця збірка — під швидкий локальний інференс і донавчання моделей до ~30B на одній відеокарті, з повним доступом до екосистеми CUDA (vLLM/SGLang для продакшн-сервінгу, QLoRA для тюнінгу). Цільові сценарії: кодовий асистент і чат на максимальній швидкості, продакшн-ендпоінт з батчингом, експерименти і файнтюн 7–30B, плюс генерація зображень/відео (SDXL, Flux). Не мета — запуск моделей більших за 32 ГБ: для щільних 70B і frontier-MoE потрібен інший клас заліза.

Бюджет — це повноцінний ПК, а не «коробка». Головна стаття — сама карта ($2 500–3 200 у роздробі), решта (CPU, плата, пам’ять, БЖ, охолодження, корпус) додає ~$1 800. Підсумок — близько $4 300–5 000 на червень 2026. Саме роздрібна ціна карти, а не збірка, ламає економіку — про це в кінці.
Конфігурація (BOM)
Збалансована конфігурація під локальний ШІ (карта — головне, решта не повинна її пляшково горлити). Ціни — роздріб на червень 2026.Компонент Модель Ціна Навіщо саме це Відеокарта NVIDIA RTX 5090 32 ГБ $2 500–3 200 ядро збірки: 1792 ГБ/с, FP8, CUDA Процесор AMD Ryzen 9 9950X (16 ядер) ~$550 вистачає для prefill і пайплайна; X3D під ігри не потрібен Мат. плата X870/X670E (PCIe 5.0) ~$300 PCIe 5.0 ×16 під карту, живлення Пам’ять 96 ГБ DDR5-6000 (2×48) ~$280 запас під offload MoE-експертів у RAM Блок живлення 1000–1200 Вт, ATX 3.1 ~$200 575 Вт карти + запас; нативний 12V-2×6 Охолодження CPU 360-мм AIO ~$110 тихо тримає 16 ядер під навантаженням Корпус + NVMe з продувкою + 2 ТБ NVMe ~$350 airflow критичний (пам’ять карти 88–90 °C) Разом ~$4 300–5 000
Зауваження щодо економії: якщо ігри не потрібні, беріть звичайний 9950X (не X3D) — для ШІ різниці немає, а грошей менше. І не економте на БЖ і продувці — карта на 575 Вт вимоглива до живлення і тепла.
Що реально потягне (32 ГБ)
Головне питання збірки на 5090 — не швидкість, а «чи влізе». 32 ГБ — це багато для споживчої карти, але стеля реальна. Нижче — що влазить у 32 ГБ і з якою швидкістю (пам’ять — Runpod, травень 2026; швидкість — незалежні заміри BIZON/robert-mcdermott).Модель Розмір (квант) Влазить у 32 ГБ? Швидкість, ток/с Llama 8B / Mistral 7B ~6–7 ГБ (4-біт/FP8) так, із запасом ~238 gpt-oss-20B ~12 ГБ (MXFP4) так ~325 Qwen 32B ~18 ГБ (4-біт) / ~32 (FP8) так ~60 Llama 70B ~35–40 ГБ (4-біт) ні — offload у RAM — Flux.1 Dev (картинки) ~24 ГБ так —
У FP16 ваги вдвічі важчі (8B ~14 ГБ, 13B ~26 ГБ, 32B ~64 ГБ), тому великі моделі ганяють у FP8 або 4-біт.
Висновок: комфортний діапазон однієї 5090 — моделі до ~32B (32B у FP8/4-біт, 13B у FP16, 8B як завгодно). А ось щільна 70B на одну карту практично не влазить: навіть у 4-біт це ~35–40 ГБ. Втиснути її можна хіба що в агресивному Q3 з крихітним контекстом, «з великими труднощами» — це не робочий сценарій.
І головне про стелю. Щойно модель не вміщається в 32 ГБ, вона починає вивантажуватися в системну DDR5, і вся гігантська пропускна здатність карти упирається у швидкість звичайної оперативки — швидкість падає обвально. Тому frontier-моделі (щільні 70B+, великі MoE на кшталт Qwen3-Coder-Next на ~85 ГБ) — це вже не про 5090.
Зате 5090 чудово закриває генеративну графіку і відео — область, де ємність unified-memory не потрібна, а вирішує швидкість. 32 ГБ із запасом тягнуть повнорозмірний SDXL з кількома ControlNet, Flux.1 Dev (~24 ГБ) і відеогенератори на кшталт Wan і CogVideoX без вивантаження в системну пам’ять, причому швидше за будь-яку попередню споживчу карту. Якщо збірка задумана не лише під текстові LLM, а й під зображення/відео — це помітний плюс до універсальності і ще один аргумент на користь дискретного GPU проти «коробок».
Реальна швидкість
На тому, що влазить, RTX 5090 — король. Швидкість генерації (decode) зростає майже лінійно з пропускною здатністю, а в 5090 її найбільше серед споживчих карт.
- Llama 8B (Q4): ~238 токенів/с — швидше, ніж ви читаєте.
- gpt-oss-20B: ~325 токенів/с.
- Щільна 30B: ~60 токенів/с — «під 30B ніщо не зрівняється» (Julien Simon, квітень 2026).
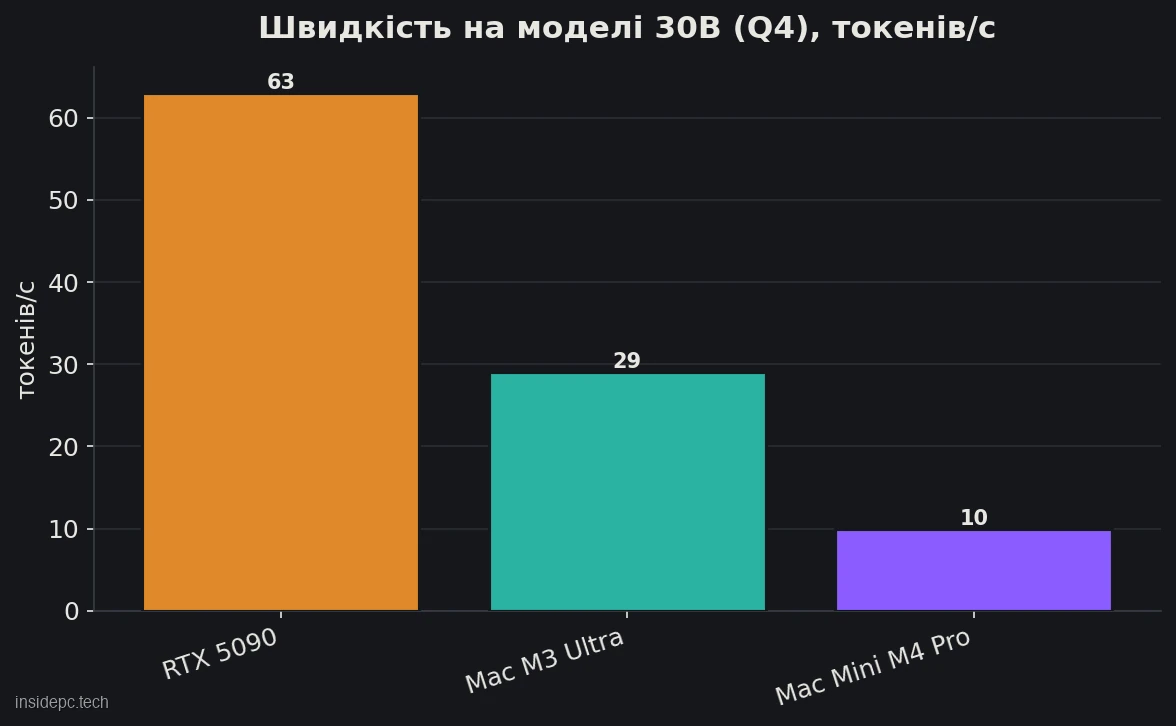
Наочно це видно на співставній 30B-моделі (Qwen3 30B-A3B, заміри BIZON): RTX 5090 видає ~63 ток/с проти ~29 у Mac Studio M3 Ultra і ~10 у Mac Mini M4 Pro — на моделі, що влазить, 5090 у 2–6 разів швидша за unified-memory машини. Додатковий козир — FP8 на тензор-ядрах Blackwell 5-го покоління: він удвічі економить пам’ять проти FP16 (більше моделей і запитів уміщається в 32 ГБ) і прискорює інференс; vLLM і SGLang це використовують, llama.cpp — ні.
RTX 5090 проти альтернатив
Де 5090 виграє, а де ні (дані на червень 2026).Рішення Пам’ять / ПЗ Ціна Сильна сторона Збірка на RTX 5090 32 ГБ / 1 792 ГБ/с ~$4 500 (вся збірка) максимум швидкості ≤32 ГБ + CUDA RTX 4090 (б/в) 24 ГБ / ~1 008 ГБ/с ~$1 100–1 800 дешевше, якщо вистачає 24 ГБ RTX 3090 (б/в) 24 ГБ / 936 ГБ/с ~$600 бюджетний король VRAM-за-долар Mac Studio M3 Ultra до 512 ГБ / 819 ГБ/с від $3 999 тримає 671B (те, що 5090 не може) Strix Halo (міні-ПК) 128 ГБ / 256 ГБ/с ~$2 350 128 ГБ дешево і тихо
Головна розвилка — швидкість проти ємності. RTX 5090 швидша за будь-яку unified-memory машину на моделях, що влазять у 32 ГБ, але вони ж її й обмежують. Mac Studio M3 Ultra повільніша на токенах, зате тримає 671B-модель цілком — те, що 5090 не запустить у принципі. Це дзеркальний вибір: 5090 — коли модель влізла і потрібна максимальна швидкість; unified-memory — коли потрібна ємність під великі моделі. Докладний розбір «потужніше за пам’яттю» — у нашому огляді Mac Studio M3 Ultra, а міні-ПК на Strix Halo — в огляді Ryzen AI Max+ 395.
Якщо 24 ГБ вистачає, чесніше придивитися до RTX 3090 б/в (~$600) — це консенсусний бюджетний вибір спільноти за VRAM-за-долар; 5090 беруть за швидкість, FP8 і +8 ГБ.
Коли брати 4090 замість 5090: якщо моделі стабільно вкладаються в 24 ГБ і максимальна швидкість не критична, RTX 4090 (~$1 100–1 800) вигідніша — ті самі моделі, але дешевше. 5090 виправдана, коли моделі потрапляють у зону 24–32 ГБ, де 4090 вже вимагає агресивного кванта, або коли упор саме в пропускну здатність і FP8-інференс.
Збірка і налаштування
Кілька практичних нюансів, без яких збірка не розкриється.
- Живлення. 575 Вт TDP плюс процесор — беріть БЖ на 1000 Вт+ (для двох карт 1500 Вт+), бажано ATX 3.1 з нативним роз’ємом 12V-2×6, щоб не городити перехідники.
- Охолодження. Під навантаженням пам’ять карти гріється до 88–90 °C — корпус із доброю продувкою обов’язковий, інакше термотротлінг.
- Софт. Для продакшн-сервінгу — vLLM (з
--dtype fp8використовує тензор-ядра Blackwell), для структурної генерації — SGLang; для локальних експериментів — llama.cpp/Ollama (GGUF), для донавчання — Transformers + bitsandbytes (QLoRA). Покроковий розбір інференсу (Ollama, кванти, бекенди) — у розділі локальні нейромережі. - Донавчання. 32 ГБ вистачає на QLoRA/LoRA-тюнінг моделей 7–30B (30B у 4-біт займає ~18–20 ГБ) — рідкісна для споживчого заліза можливість донавчати модель під свої дані, недоступна на Apple Silicon. Тюнінг 70B уже поза діапазоном однієї карти.
- Нюанс екосистеми. Споживчий Blackwell (так званий SM120: RTX 5090 і RTX PRO 6000) інколи не отримує day-0 підтримки у свіжих релізах vLLM/SGLang — пріоритет у датацентрових H100/B200 (скарга спільноти, червень 2026). На стабільних версіях усе працює, але «біжучий край» може зачекати пару тижнів.
Апгрейд-шлях
Пам’ять карти не нарощується, тому шлях зростання — інший:
- Друга RTX 5090. Дає сумарно 64 ГБ і близько 55 ток/с на 70B, але із застереженнями: NVLink не підтримується, обмін між картами йде по PCIe, а в пари 5090 відомі проблеми P2P (баг у vLLM, обговорення на форумах NVIDIA). Це не «64 ГБ одним пулом», а ручний шардинг із граблями — для серйозного розподіленого інференсу шлях не рекомендується. Потрібно багато пам’яті «як один пул» — логічніше дивитися на unified-memory або датацентровий GPU.
- Оренда замість другої карти. Перш ніж докуповувати другий прискорювач, порахуйте завантаження. Карта за $2 500–3 200 плюс електрика й охолодження окупаються лише за постійного навантаження — кілька годин інференсу або тренування щодня. Для рідкісних експериментів, разових файнтюнів і сплескових задач оренда у хмарі виходить дешевше: RTX 5090 коштує від ~$0,86/год (Spheron), без закупівлі дефіцитної карти, апгрейда БЖ і поратися з драйверами. Грубий орієнтир: прискорювач простоює більшу частину доби — економіка за оренду; завантажений майже постійно — за купівлю.
Ризики і слабкі місця
Чесний список (з датами):
- Жорстка стеля 32 ГБ. Щільна 70B і frontier-MoE не влазять; offload у DDR5 убиває швидкість (XDA/Runpod, 2026). Купувати 5090 «заради 70B» — помилка.
- Немає NVLink. 2× 5090 — це шардинг по PCIe і проблеми P2P, а не єдиний пул на 64 ГБ (Runpod/GitHub, 2026).
- Ціна і доступність. $2 500–3 200 у роздробі, до $3 000–4 200 у скальперів проти MSRP $1 999 (r/buildapc, червень 2026) — карта роздуває збірку до ~$4 300–5 000.
- Живлення і жар. 575 Вт, БЖ 1000 Вт+, пам’ять 88–90 °C — це шум, тепло в кімнаті і рахунок за електрику.
- Екосистема SM120 відстає. Споживчий Blackwell інколи без day-0 підтримки vLLM/SGLang проти датацентрових карт (спільнота, червень 2026).
Заради справедливості — плюси вагомі: це найшвидша споживча карта для моделей до 32 ГБ, повний CUDA-стек (vLLM, FP8, QLoRA-тюнінг) недоступний Apple/AMD, відмінна генерація картинок і відео, і заразом топова ігрова/рендер-карта — тобто багатоцільова, а не лише під ШІ.
Кому підходить, а кому ні
- Зберіть ПК на RTX 5090, якщо ваші моделі влазять у 32 ГБ (до ~30–32B), важливі максимальна швидкість, продакшн-сервінг на vLLM або донавчання, і ви готові до ціни ~$4 500, шуму і тепла.
- Візьміть RTX 3090/4090 (б/в), якщо вистачає 24 ГБ і хочеться заощадити — особливо 3090 за ~$600.
- Ідіть в unified-memory (Mac Studio / Strix Halo), якщо потрібні моделі більші за 32 ГБ (70B і більше) — там виграє ємність, а не швидкість.
- Орендуйте GPU у хмарі, якщо навантаження рідкісне або сплескове — $4 500 заліза окупаються лише за постійного завантаження.
FAQ
Чи запустить RTX 5090 модель Llama 70B? На одній карті — практично ні. Щільна 70B навіть у 4-біт важить ~35–40 ГБ і не влазить у 32 ГБ; втиснути можна хіба що в агресивному Q3 з крихітним контекстом, «з труднощами». Робочі варіанти для 70B — дві 5090 (із застереженнями по PCIe), unified-memory машина або датацентровий GPU. Комфортна стеля однієї 5090 — моделі до ~32B.
Скільки коштує зібрати ПК на RTX 5090 для ШІ? Близько $4 300–5 000 на червень 2026. Основна стаття — сама карта ($2 500–3 200 у роздробі, дорожче у скальперів), решта (Ryzen 9 9950X, 96 ГБ DDR5, плата X870, БЖ 1000 Вт+, охолодження, корпус) — ще ~$1 800.
RTX 5090 чи Mac Studio для локального LLM? Дзеркальний вибір. RTX 5090 швидша на моделях, що влазять у 32 ГБ (8B ~238, 30B ~60 ток/с), і дає CUDA-стек. Mac Studio M3 Ultra повільніша на токенах, але тримає моделі до 671B, які 5090 не запустить. Влазить у 32 ГБ і потрібна швидкість — 5090; потрібна ємність під великі моделі — Mac.
Чи дають дві RTX 5090 «64 ГБ» для 70B? Не у звичному сенсі. NVLink у 5090 немає, тому дві карти не утворюють єдиний пул — модель шардиться по PCIe, а в пари 5090 трапляються проблеми P2P. Технічно 70B у 4-біт так запустити можна (~55 ток/с), але для серйозного розподіленого інференсу цей шлях не рекомендується.
Який блок живлення потрібен для RTX 5090? Мінімум 1000 Вт для однієї карти (575 Вт TDP плюс процесор і запас), краще ATX 3.1 з нативним роз’ємом 12V-2×6. Для збірки на дві карти — 1500 Вт і вище. І обов’язково добра продувка корпуса: пам’ять карти під навантаженням гріється до 88–90 °C.













