

Коротко (TL;DR)
GPT-OSS — это маленькая сенсация: впервые с 2019 года (со времён GPT-2) OpenAI выпустила открытые модели, которые можно скачать и запустить у себя. Релиз состоялся 5 августа 2025 года, и для локального ИИ это событие — теперь у вас на диске может работать модель с фирменным «характером» OpenAI и настраиваемым рассуждением.
- Коротко (TL;DR)
- Почему это исторически важно
- Две версии и MoE-парадокс
- Сколько нужно железа: VRAM, кванты и скорость
- reasoning_effort: настройка глубины мышления
- Формат Harmony: важная грабля
- Бенчмарки: близко к o3-mini и o4-mini
- Запуск: Ollama, LM Studio, llama.cpp
- Настройка под себя: контекст, рассуждения и API
- Русский и украинский: честно неясно
- GPT-OSS против Qwen3, DeepSeek и Llama
- Когда брать GPT-OSS, а когда нет
- Риски и грабли
- FAQ
- Две версии. gpt-oss-20B — для домашнего ПК (запускается на видеокарте 16 ГБ), и gpt-oss-120B — для рабочей станции или сервера (нужна карта на 80 ГБ). Обе построены на архитектуре «смеси экспертов» (MoE) и распространяются под свободной лицензией Apache 2.0.
- Сильный reasoning на скромном железе. По бенчмаркам gpt-oss-20B соперничает с закрытой o3-mini, а 120B — с o4-mini. У моделей настраиваемая глубина рассуждений и встроенная работа с инструментами.
- Но есть честные минусы. Модель склонна к избыточным отказам («не могу помочь»), требует особого формата промптов Harmony, не работает с изображениями и — важно — не обновлялась с момента выхода.
Минимальное железо для домашней версии: gpt-oss-20B в родном кванте занимает около 16 ГБ, а на 8 ГБ её можно запустить с выгрузкой части в оперативную память. Данные актуальны на 16 июня 2026 года.
Почему это исторически важно
Чтобы оценить событие, нужен контекст. С 2019 года OpenAI не выпускала открытых моделей — компания, с которой начался бум ChatGPT, держала веса закрытыми. GPT-OSS сломала эту паузу: это первые за шесть лет модели OpenAI, которые можно скачать, запустить офлайн, изучить и встроить в свой продукт.
Особенно важна лицензия Apache 2.0 — одна из самых свободных. В отличие от лицензии Llama с её ограничениями, gpt-oss можно использовать коммерчески без порогов и согласований (есть лишь минимальная политика использования — соблюдать закон). Для бизнеса, которому нужен «движок уровня OpenAI» на собственных серверах без отправки данных в облако, это открыло новую дверь.

Для нашей аудитории это особенно ценно в одном сценарии — суверенитет данных. Юристы, врачи, компании с чувствительной информацией всё чаще выбирают локальный ИИ не ради скорости, а ради того, чтобы данные физически не покидали их инфраструктуру. GPT-OSS с её Apache 2.0 идеально ложится в эту нишу: «движок в стиле OpenAI» можно развернуть на собственном сервере, в офисе или даже на ноутбуке — без подписок, без передачи запросов наружу и без юридических ограничений на коммерцию. До GPT-OSS такой опции «от самой OpenAI» просто не существовало.

Две версии и MoE-парадокс
GPT-OSS вышла в двух размерах, и оба используют архитектуру «смеси экспертов» (MoE) — именно она объясняет, почему даже большая модель помещается на одну карту.Модель Всего параметров Активных на токен Контекст Под какое железо gpt-oss-20B 20,9 млрд 3,6 млрд 128K Видеокарта 16 ГБ (RTX 4090/3090) gpt-oss-120B 116,8 млрд 5,1 млрд 128K Карта 80 ГБ (H100) / рабочая станция 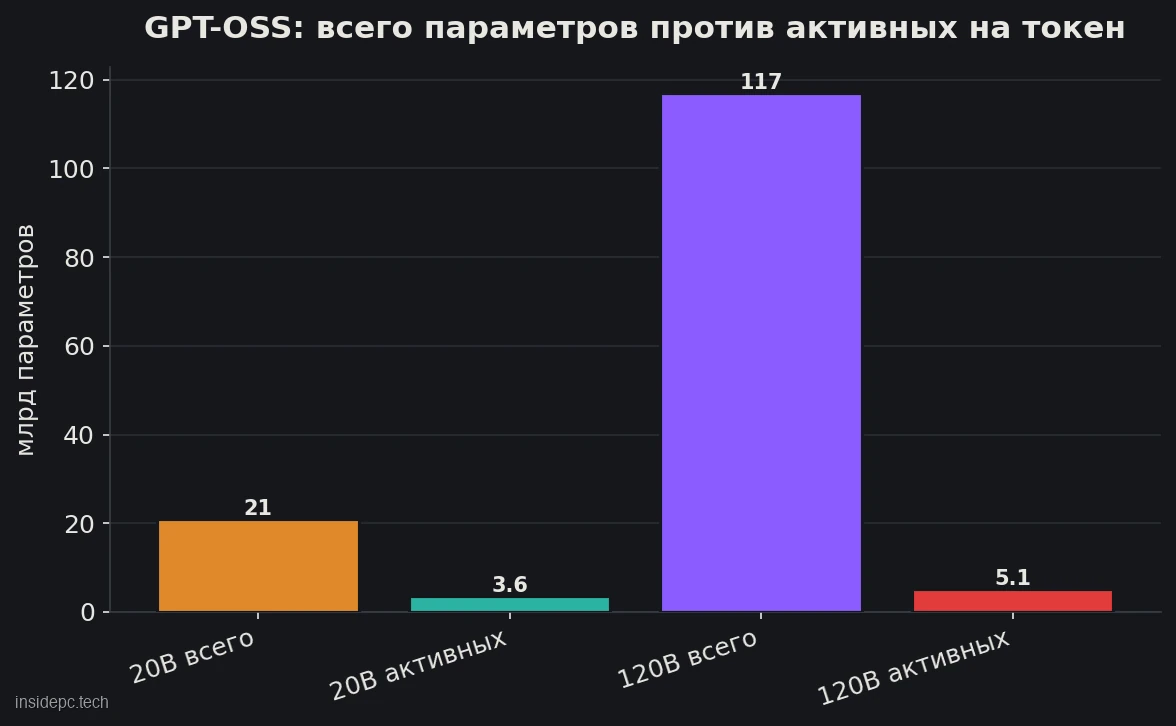
Вот в чём «парадокс»: gpt-oss-120B содержит почти 117 млрд параметров, но на каждый токен задействует лишь около 5 млрд. За счёт этого модель «думает» быстро, как небольшая. Но — и это ключевой нюанс для выбора железа — в память нужно загрузить все веса, а не только активные. Поэтому 120B требует около 80 ГБ видеопамяти (это уровень серверной карты H100), а 20B — около 16 ГБ. MoE экономит скорость вычислений, но не объём памяти.
Практический вывод: для домашнего ПК реалистична gpt-oss-20B. Версия 120B — для тех, у кого есть профессиональная карта на 80 ГБ или система с большой единой памятью (например, Mac или мини-ПК с unified memory).
Сколько нужно железа: VRAM, кванты и скорость
У GPT-OSS есть приятная особенность: модели поставляются в родном кванте MXFP4 — то есть OpenAI сразу обучила и выложила их в сжатом 4-битном формате, без потери качества от стороннего квантования. Это значит, что «официальные» требования уже учитывают сжатие.Версия (MXFP4) VRAM Железо Скорость* gpt-oss-20B ~16 ГБ RTX 4090 ~180–220 tok/s gpt-oss-20B ~16 ГБ RTX 3090 ~144–160 tok/s gpt-oss-20B (offload) 8 ГБ + ОЗУ RTX 3060/3070 + RAM ~40 tok/s gpt-oss-120B ~80 ГБ H100 (серверная) высокая gpt-oss-120B unified ~96 ГБ+ Mac Studio / мини-ПК скромнее, зависит от чипа
*Скорость — по замерам сообщества (июнь 2026); зависит от кванта, контекста и бекенда.
Что отсюда следует:

- 16 ГБ VRAM (RTX 4090, 3090) — комфортный дом для gpt-oss-20B: скорость на RTX 4090 достигает 180–220 токенов/с (по замерам сообщества), на RTX 3090 — около 144–160.
- 8 ГБ VRAM — 20B всё ещё можно запустить, выгрузив часть слоёв-«экспертов» в оперативную память. Скорость упадёт примерно до 40 токенов/с, но модель заработает даже на скромной карте. Это полезный приём для старого железа.
- 80 ГБ — территория 120B: профессиональная карта H100 или платформа с большой единой памятью.
Отдельно про 120B на «домашнем» железе: благодаря MoE её реально запустить не только на серверной H100, но и на системах с большой единой памятью — Mac Studio или мини-ПК на чипах с unified memory (около 96 ГБ и больше). Скорость там скромнее, чем на H100, но сам факт, что модель почти на 117 млрд параметров крутится на компактном устройстве, — заслуга именно архитектуры «смеси экспертов». Подробнее о таких платформах — в наших обзорах сборок для локального ИИ.
Важная техническая оговорка: родной формат MXFP4 нативно ускоряется только на новых архитектурах (Hopper и Blackwell). На видеокартах до них — это потребительские RTX 30xx и 40xx — формат эмулируется программно: модель запустится, но без аппаратного выигрыша в скорости от самого MXFP4. Нативное ускорение есть на RTX 50xx и серверных картах.
Если выбираете видеокарту под локальный ИИ, отталкивайтесь от объёма VRAM — подробный разбор в гиде по выбору GPU для ИИ.
reasoning_effort: настройка глубины мышления
Как и некоторые современные модели, GPT-OSS умеет «думать вслух» (chain-of-thought) перед ответом. Но у неё есть удобный регулятор — параметр reasoning_effort с тремя уровнями: low, medium, high.
Задаётся он прямо в системном промпте строкой вида Reasoning: low. Логика простая:
- low — быстрый ответ с минимумом рассуждений, для простых задач и чата;
- medium — баланс, подходит для большинства задач;
- high — максимум размышлений, для сложной математики, логики и кода.
Это удобно: не нужно держать две модели — «быструю» и «умную». Для рутины ставите low, для трудной задачи переключаете на high прямо в запросе. Чем выше уровень, тем дольше ответ и больше расход контекста на рассуждения — об этом стоит помнить на длинных диалогах.
На практике это выглядит так: добавляете в системный промпт строку Reasoning: high — и на вопрос по сложному алгоритму модель развернёт подробную цепочку рассуждений, прежде чем дать ответ. Поставите Reasoning: low — и простой запрос она закроет мгновенно, не тратя время на размышления. Одна модель превращается в гибкий инструмент: от быстрого ассистента до вдумчивого «решателя» задач — переключением одной строки.
Формат Harmony: важная грабля
Это нюанс, на котором спотыкаются при ручном запуске. GPT-OSS обучена работать в особом формате промптов под названием Harmony — со специальными разделителями вроде <|channel|>analysis (рассуждения) и final (итоговый ответ). Если подать модели запрос «не в том формате», она ведёт себя странно: путает рассуждения с ответом или выдаёт мусор.
Хорошая новость: при запуске через Ollama или LM Studio об этом думать не нужно — они применяют формат Harmony автоматически. Грабли возникают, если вы используете llama.cpp или собственный код напрямую и неправильно настроили шаблон промпта (известны несовместимости с jinja-шаблонами). Вывод практический: для простого локального запуска берите Ollama — она избавляет от возни с форматом. Ручная настройка Harmony нужна только продвинутым пользователям при интеграции в свой код.
Бенчмарки: близко к o3-mini и o4-mini
Главное достижение GPT-OSS — высокий уровень рассуждений для открытых моделей. По официальным данным OpenAI (август 2025):
- gpt-oss-120B на максимальном reasoning берёт 92,5% на сложном математическом AIME 2025, 80,1% на научном GPQA Diamond и 62,4% на тесте программирования SWE-Bench — это почти уровень закрытой o4-mini.
- gpt-oss-20B показывает 91,7% на AIME 2025 и 71,5% на GPQA — на уровне или выше o3-mini.
Что это значит на практике: для задач на математику, логику и код GPT-OSS даёт результат, сопоставимый с закрытыми «mini»-моделями OpenAI, но локально и бесплатно. Оговорка стандартная: бенчмарки отражают узкие задачи; на реальной работе многое зависит от ваших сценариев, и рекордные цифры стоит проверять самому.
Ещё важная деталь: эти рекордные цифры достигаются на максимальном уровне рассуждений (high). На low модель отвечает быстрее, но проще — и результат на сложных бенчмарках падает. Это не обман, а та самая гибкость: вы сами решаете, тратить ли вычисления на глубокое размышление. Для повседневных задач хватает medium, а high приберегите для действительно трудных вопросов.
Если сравнивать с другими открытыми «думающими» моделями, GPT-OSS играет в одной лиге с DeepSeek-R1 и reasoning-режимом Qwen3, но с двумя оговорками. Плюс GPT-OSS — настраиваемое усилие рассуждений и совместимость с экосистемой OpenAI «из коробки». Минус — те самые избыточные отказы и отсутствие данных по русскому. Для чисто математических и логических задач на английском GPT-OSS — один из сильнейших открытых вариантов; для русскоязычной работы и стабильной отзывчивости конкуренты выглядят надёжнее.
Запуск: Ollama, LM Studio, llama.cpp
Самый простой путь — Ollama, который сам разбирается с форматом Harmony (проверено по каталогу Ollama, июнь 2026):
ollama run gpt-oss:20b # домашняя версия, 16 ГБ
ollama run gpt-oss:120b # серверная версия, 80 ГБ
Ollama сразу поднимает локальный API, совместимый с форматом OpenAI, — удобно для подключения к редакторам кода и ботам.
LM Studio — графический интерфейс с каталогом моделей и удобным просмотром рассуждений отдельно от ответа; тоже корректно работает с Harmony.
llama.cpp и vLLM — для тонкой настройки и серверных сценариев. Здесь будьте внимательны к формату Harmony и шаблонам промптов (см. раздел выше). Например, запуск 120B через сервер llama.cpp выглядит так:
llama-server -hf ggml-org/gpt-oss-120b-GGUF -c 0 -fa --jinja --reasoning-format none
Флаг --jinja подключает шаблон Harmony — без него ответы будут «сырыми».
Типовые ошибки и решения:
- Модель «не помещается» — для 20B нужно 16 ГБ; на 8 ГБ запускайте с выгрузкой слоёв в оперативную память, на 120B потребуется 80 ГБ.
- Странные ответы (рассуждения вперемешку с ответом) — нарушен формат Harmony; используйте Ollama или LM Studio, которые применяют его сами.
- Медленно на старой карте — формат MXFP4 не ускоряется аппаратно до Hopper; это ожидаемо, модель всё равно работает.
Настройка под себя: контекст, рассуждения и API
Несколько параметров под свои задачи.
- Уровень рассуждений. Главный регулятор GPT-OSS —
reasoning_effortв системном промпте (low/medium/high). Держите low для рутины и переключайте на high для сложных задач; это прямо влияет на скорость и расход контекста. - Длина контекста (num_ctx). Модель поддерживает 128K токенов, но Ollama по умолчанию выделяет меньше. Для длинных документов поднимайте
num_ctxвручную, помня про расход видеопамяти на контекст — с включёнными рассуждениями он растёт быстрее. - Температура. Для математики, кода и точных задач ставьте низкую (0.1–0.3). Это общепринятые ориентиры сообщества.
- Встроенные инструменты. GPT-OSS из коробки умеет вызывать инструменты (поиск, выполнение кода) — это помогает обойти ограничение «знаний до июня 2024», подключив модели актуальный источник данных. Настройка зависит от бекенда.
Режим API. Ollama поднимает сервер на localhost:11434 в формате OpenAI: подключайте GPT-OSS к редакторам кода, агентам и скриптам. Поскольку формат API совпадает с облачным OpenAI, перевести существующий проект с облачного GPT на локальный gpt-oss часто можно сменой адреса сервера — данные при этом остаются на вашем компьютере.
Русский и украинский: честно неясно
Здесь придётся быть откровенными. OpenAI не публиковала отдельных данных по качеству русского и украинского у GPT-OSS. Модель многоязычна, но в официальном многоязычном тесте (MMMLU, 14 языков) русского и украинского нет — поэтому судить о качестве напрямую по цифрам нельзя.
По косвенным признакам (общий уровень многоязычности 81,3% у 120B и 75,7% у 20B на поддерживаемых языках, по данным model card) можно ожидать приличного, но не топового результата на русском. Есть и тревожный сигнал: независимое red-teaming-исследование (arXiv, октябрь 2025) по «языкам с малым ресурсом» выявило у GPT-OSS повышенную склонность к выдумыванию фактов на редких языках. Русский к редким не относится, но осторожность не помешает.
Практический вывод: если русский или украинский — главное в вашей задаче, надёжнее взять Qwen3, у которого оба языка официально поддержаны и проверены. GPT-OSS берите ради reasoning и экосистемы OpenAI, а качество на русском проверяйте на своих примерах.
GPT-OSS против Qwen3, DeepSeek и Llama
«Лучшей модели вообще» не бывает. Вот честное сравнение с тремя соперниками в локальном сегменте (по состоянию на июнь 2026).Критерий GPT-OSS Qwen3 DeepSeek-R1 Llama Рассуждение Сильное (настраиваемое) Сильное (гибрид) Сильное Среднее Русский/украинский Неясно (нет данных) Лучший Средне Средне Лицензия Apache 2.0 Apache 2.0 MIT Community Мультимодальность Нет (только текст) Есть варианты Нет Vision (отд. версии) Отказы (цензура) Высокие Средние (политика) В весах (Китай) Низкие Обновления Нет (с авг. 2025) Регулярные Регулярные Регулярные
Где GPT-OSS сильна: reasoning уровня o-mini локально, свободная лицензия и «характер» OpenAI. Где стоит выбрать иначе: для русского сильнее Qwen3, для работы с картинками — Gemma или Qwen-Vision, а если важны регулярные обновления — у конкурентов с ними лучше.
Когда брать GPT-OSS, а когда нет
Сведём выбор к простым сценариям.
Берите GPT-OSS, если:
- вам нужен сильный reasoning локально уровня o3-mini/o4-mini для математики, логики и кода;
- важен суверенитет данных и свободная лицензия Apache 2.0 для бизнеса;
- вы хотите «характер» и экосистему OpenAI на своём железе, с привычным API;
- задачи преимущественно на английском, а формат запросов — структурированный.
Выберите альтернативу, если:
- главное — русский или украинский: берите Qwen3;
- нужна мультимодальность (картинки, звук) — GPT-OSS только текст, смотрите Gemma или Qwen-Vision;
- вас раздражают избыточные отказы — Qwen3 и DeepSeek дают меньше «не могу помочь»;
- важны регулярные обновления — GPT-OSS не развивается с августа 2025.
Универсального ответа нет: GPT-OSS — это про reasoning и контроль над данными в экосистеме OpenAI, а не про лучший русский или свежесть весов.
Риски и грабли
- Избыточные отказы (главный минус). GPT-OSS унаследовала строгие настройки безопасности OpenAI и часто отказывается отвечать даже на безобидные запросы, заполняя «рассуждения» ссылками на политику. Это известная претензия сообщества; часть пользователей уходит на «расцензуренные» (abliterated) версии от сторонних авторов — учтите, что это уже не официальная модель.
- Не обновлялась с релиза. На июнь 2026 — это больше 10 месяцев без новых весов. Сообщество разочаровано: модель хороша, но OpenAI не развивает её, тогда как Qwen и DeepSeek выпускают версии регулярно.
- Только текст. GPT-OSS не работает с изображениями и звуком — для мультимодальных задач нужна другая модель.
- Знания до июня 2024. Модель не знает событий после этой даты; для актуальной информации подключайте поиск или базу знаний (RAG).
- Формат Harmony. При ручной интеграции легко ошибиться с форматом промпта — для простого запуска используйте Ollama.
- MXFP4 без ускорения на старых картах. На видеокартах до Hopper родной формат эмулируется программно — без прироста скорости.
- Перегрев при долгих сессиях. Длительная нагрузка греет видеокарту — следите за температурами на компактных сборках.
FAQ
Потянет ли GPT-OSS моя видеокарта на 8 ГБ? Версию gpt-oss-20B — да, но с оговоркой: 16 ГБ для неё штатный объём, а на 8 ГБ её запускают с выгрузкой части «экспертов» в оперативную память. Скорость упадёт примерно до 40 токенов/с, но модель заработает. Версия 120B на 8 ГБ невозможна — ей нужно около 80 ГБ.
Нужен ли сервер H100 для gpt-oss-120B? Практически да: 120B требует около 80 ГБ видеопамяти, и это уровень профессиональной карты H100. Альтернатива — система с большой единой памятью (например, Mac или мини-ПК с unified memory от 96 ГБ). На обычной игровой видеокарте 120B не запустится; для дома берите 20B.
Что такое формат Harmony и нужно ли с ним возиться? Это особый формат промптов, под который обучена GPT-OSS (с разделителями рассуждений и ответа). При запуске через Ollama или LM Studio он применяется автоматически — возиться не нужно. Ручная настройка требуется только при интеграции через llama.cpp или собственный код.
Хорош ли GPT-OSS для русского языка? Точных данных нет — русского и украинского нет в официальных многоязычных тестах модели. Ожидаемо результат приличный, но не лучший среди открытых моделей. Для русскоязычных задач надёжнее Qwen3; GPT-OSS проверяйте на своих примерах.
Почему GPT-OSS часто отказывается отвечать? Это следствие строгих настроек безопасности OpenAI: модель перестраховывается и отклоняет даже безобидные запросы. Известная претензия к ней. Часть пользователей переходит на сторонние «расцензуренные» версии, но это уже неофициальные модели — применяйте на свой риск.
Чем gpt-oss-20B отличается от 120B, кроме размера? В основном мощностью рассуждений и требованиями к железу. 20B запускается на домашней карте 16 ГБ и по бенчмаркам сопоставима с o3-mini; 120B сильнее (уровень o4-mini), но требует около 80 ГБ видеопамяти. Архитектура у обеих одинаковая (MoE), лицензия и формат тоже — выбор сводится к тому, какое железо у вас есть.
Можно ли использовать GPT-OSS в коммерческом продукте? Да. Лицензия Apache 2.0 разрешает коммерческое использование без порогов и роялти; есть лишь минимальная политика использования (соблюдать применимое законодательство). Это делает GPT-OSS удобным выбором для встраивания в продукты и развёртывания на собственных серверах.
GPT-OSS обновляется? На июнь 2026 — нет. С момента релиза в августе 2025 OpenAI не выпустила новых весов, и сообщество отмечает это как разочарование: модель хороша, но «застыла». Конкуренты вроде Qwen и DeepSeek за это время выпустили несколько обновлений. Если для вас важна свежесть модели, учитывайте это при выборе.















