
Коротко (TL;DR)
Mac Mini M4 Pro — это самый дешёвый серьёзный вход в локальный ИИ на единой памяти. Маленькая бесшумная коробка с до 64 ГБ единой памяти и пропускной способностью 273 ГБ/с запускает открытые модели без облака и без оплаты за токены.
Главное — правильно понять, что он реально тянет. Сильная сторона — модели 8–32 млрд параметров: Llama 3.1 8B идёт около 36 токенов/с, модели на 27–32B — комфортные 10–11 ток/с. Модель на 70B (в конфигурации 48–64 ГБ) тоже загрузится, но пойдёт всего ~4 ток/с и память будет впритык — это «можно, но не для ежедневной работы». Для самых больших моделей (235B–671B) нужен уже Mac Studio, а для максимальной скорости — видеокарта.
Цена начинается с $599 за базовый Mac Mini M4 (16 ГБ — на 7–8B модели), а «сладкая точка» для локального ИИ — M4 Pro c 48 ГБ за ~$1 999 или 64 ГБ за ~$2 199–2 399 (по данным на июнь 2026). Сразу развеем вирусный миф: «Mac Mini за $599 с 64 ГБ» не существует — за $599 продаётся база с 16 ГБ, а 64 ГБ бывают только у M4 Pro за ~$2 200+. Ниже — таблица «что влезает», реальная скорость и кому это подходит.
(Данные актуальны на 15 июня 2026; цены и бенчмарки — с датами в тексте.)
Задача и бюджет
Mac Mini M4 Pro — устройство под локальный инференс открытых LLM одним пользователем: приватный ассистент, кодовый помощник, RAG по своим документам, тихий ИИ-сервер, работающий 24/7. Его козыри — низкая цена входа, бесшумность и копеечное энергопотребление. Не его задачи — быстрый инференс 70B, дообучение моделей и обслуживание многих пользователей (для этого нужен дискретный GPU или NVIDIA-стек).

Бюджет гибкий — от $599 за базовую модель до ~$2 400 за топовый M4 Pro с 64 ГБ. И тут действует главное правило покупки: модель должна влезть в память. Объём памяти решает, ЧТО вы вообще запустите, а чип — КАК быстро это пойдёт. Память распаяна в корпус и не наращивается — выбирать объём нужно сразу.
Оговорка по ожиданиям: локально вы запускаете открытые модели (Llama, Qwen, Gemma, DeepSeek), а не облачные Gemini или Claude. Для рутинной приватной работы их хватает; за самым сложным по-прежнему идут в облако.
Что такое M4 Pro и при чём тут память
Mac Mini предлагают на двух чипах. Базовый M4 (10 ядер CPU / 10 ядер GPU, до 32 ГБ, 120 ГБ/с) — для самых маленьких моделей. Старший M4 Pro (14 ядер CPU / 20 ядер GPU, до 64 ГБ, 273 ГБ/с, 16-ядерный Neural Engine) — именно он интересен для локального ИИ за счёт вдвое большей пропускной способности и до 64 ГБ памяти.
Почему так важна единая память. У обычного ПК с видеокартой модель ограничена объёмом видеопамяти (8–24 ГБ), и всё, что туда не влезло, уходит в медленный режим. У Apple Silicon процессор, графика и нейромодуль делят один общий пул памяти без PCIe-бутылочного горлышка — вся оперативка доступна под модель. 48-гигабайтный Mac Mini даёт 48 ГБ под модель (минус ~4 ГБ под macOS).
Но у пропускной способности 273 ГБ/с есть потолок: это столько же, сколько у NVIDIA DGX Spark, и примерно треть от Mac Studio M3 Ultra (819 ГБ/с). Поэтому на крупных моделях Mac Mini «думает» медленно. Память решает, что влезет; пропускная способность — как быстро побегут токены.
Что влезает по памяти
Главная таблица для покупателя. macOS забирает ~4 ГБ, поэтому под модель доступно «объём минус 4». Грубое правило: размер модели в гигабайтах ≈ нужная память (модель 70B в кванте Q4 весит ~40 ГБ).Память Доступно под модель Что реально запустите 16 ГБ (M4, $599) ~12 ГБ 7–8B (Llama 3.1 8B Q4, Mistral 7B) 24 ГБ (M4/M4 Pro) ~20 ГБ 8B FP16, 22B Q4 (Mixtral 8x7B) 32 ГБ (M4 макс) ~28 ГБ 32B Q4 (Qwen 32B), 70B в жёстком Q2 48 ГБ (M4 Pro, ~$1 999) ~44 ГБ 70B Q4 — «сладкая точка» 64 ГБ (M4 Pro, ~$2 200+) ~60 ГБ 70B в Q6/Q8, 72B Q4
Реальный пример с дешёвого конца: модель QwQ-32B (32 млрд параметров) запускается даже на 24-гигабайтном M4 Pro через Ollama — впритык по ресурсам, но рабоче. А 48 ГБ уже дают комфортный простор под 32B-модель плюс эмбеддинги и контекст.
Реальная скорость
Загрузить модель — половина дела; вторая половина — скорость. Ниже — генерация (decode) на M4 Pro по моделям в кванте Q4 (расчёт по пропускной способности, методология BIZON, май 2026).Модель Размер Q4 Decode, ток/с Llama 3.1 8B ~4,9 ГБ ~36 Gemma 3 27B ~16,5 ГБ ~11 Qwen3 30B-A3B ~18,6 ГБ ~10 Llama 3.3 70B ~42,5 ГБ ~4 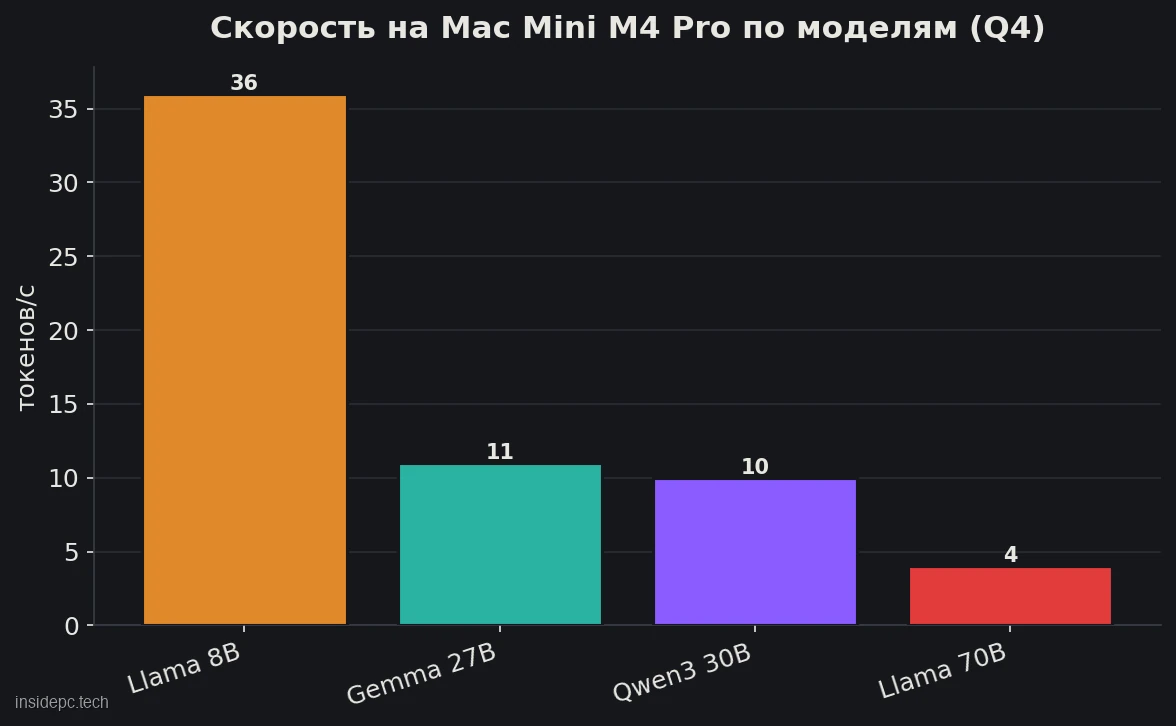
Закономерность ясная: на 8–13B моделях Mac Mini быстр (8B — больше 30 ток/с, это быстрее, чем вы читаете), на 27–32B — комфортные 10–11 ток/с, а вот плотная 70B падает до ~4 ток/с — медленнее чтения, узкое место те самые 273 ГБ/с. Поэтому честный «рабочий диапазон» M4 Pro — 8–32B: именно эти модели и решают большинство задач (код, чат, RAG). 70B держите как «можно при необходимости», а не как ежедневный инструмент.
Сколько стоит
Полная ценовая лестница Mac Mini (новый, MSRP на июнь 2026; на Amazon часто дешевле на $50–100):
- M4, 16 ГБ — $599; 24 ГБ — $999; 32 ГБ — ~$1 199 (максимум для M4).
- M4 Pro, 24 ГБ — $1 399; 48 ГБ — ~$1 999 (sweet spot); 64 ГБ — ~$2 199–2 399 (максимум).
Конфигурации 32 ГБ и 64 ГБ — только под заказ на сайте Apple. Если нужно 48 или 64 ГБ, придётся брать M4 Pro — заодно получите и более высокую пропускную способность для скорости.
Можно сэкономить и на вторичке. Свежие M4 пока почти не подешевели (~15% от новой цены), а вот Mac Mini на M1/M2 теряют 45–60%: б/у M2 Pro с 32 ГБ берут примерно за $850, а M1 с 16 ГБ — около $375 (по данным Starmorph, февраль 2026). Для первого знакомства с локальным ИИ б/у M2 Pro на 32 ГБ — отличная недорогая ступенька, хоть и медленнее M4 по генерации. Память у Apple держит остаточную стоимость лучше, чем компоненты ПК, — это плюс при будущей перепродаже.
И ещё раз про вирусный миф. По соцсетям ходит тейк «Mac Mini за $599 и сразу 64 ГБ заменил мне подписки на ИИ». Экономическая суть верна (об этом ниже), но цифры перепутаны: $599 — это база с 16 ГБ, а 64 ГБ доступны только у M4 Pro за ~$2 200+. Не ориентируйтесь на «$599 / 64 ГБ» — такого нет.
Против альтернатив
За близкие деньги у Mac Mini есть прямые конкуренты. Сравним ключевое.Решение Память / ПС Цена Сильная сторона Mac Mini M4 Pro до 64 ГБ / 273 ГБ/с $1 399–2 399 дешёвый вход, тишина, ресейл Strix Halo (Framework Desktop) 128 ГБ / 256 ГБ/с ~$2 350 вдвое больше памяти NVIDIA DGX Spark 128 ГБ / 273 ГБ/с $4 699 стек CUDA/датацентр Mac Studio M3 Ultra до 512 ГБ / 819 ГБ/с от $3 999 держит 671B, втрое быстрее
Главный неудобный вопрос — против Strix Halo. За сопоставимые деньги — около $2 350 за Framework Desktop на Ryzen AI Max+ 395 — вы получаете 128 ГБ единой памяти против 64 ГБ у Mac при почти равной пропускной способности (256 против 273 ГБ/с); готовые боксы вроде GMKtec дороже (~$3 300). По «памяти за доллар» Mac проигрывает. Его аргументы — другие: зрелый софт (MLX, Ollama «из коробки»), полная бесшумность, macOS и высокая остаточная стоимость при перепродаже. Полный разбор Strix Halo — в нашем обзоре Ryzen AI Max+ 395.
Если же вам нужны очень большие модели или скорость — это ступень вверх: Mac Studio M3 Ultra (до 512 ГБ, держит DeepSeek R1 671B) или дискретный GPU. Mac Mini — это осознанный «вход», а не потолок.
Софт и сценарий «тихий сервер 24/7»
Программная сторона у Apple Silicon приятная: Ollama (самый простой путь, OpenAI-совместимый локальный сервер), LM Studio (с графическим интерфейсом и встроенным MLX), MLX (нативная производительность Apple) и llama.cpp. Поставить и запустить модель — минут пять. Если упёрлись в один Mac Mini, две машины можно объединить через EXO по сети и распределить 70B на обе. Пошаговый разбор софта — в разделе локальные нейросети.
Где Mac Mini особенно хорош — роль бесшумного ИИ-сервера, работающего круглосуточно. Под ИИ-нагрузкой он потребляет около 30 Вт (в простое ~7 Вт), тогда как сборка на паре видеокарт — 600+ Вт. Это делает его идеальной площадкой для self-hosted ИИ-агентов вроде OpenClaw, которые висят в фоне и отвечают на задачи. Электричество при таком сценарии — около $3 в месяц.
Именно отсюда — реальная экономика. Пользователи, тратившие $200–400 в месяц на облачные ИИ-инструменты, переносят рутину на локальную коробку, и она окупается примерно за год (по данным Starmorph и обсуждений в соцсетях, июнь 2026). За самым сложным по-прежнему ходят в облако — но «дешёвые токены» рутины теперь бесплатны.
Риски и слабые места
Честный список (с датами):
- 70B «влезает, но мучается». На M4 Pro 70B-модель идёт ~4 ток/с (расчётная оценка по пропускной способности — реальная может отличаться) и память впритык под контекст и ОС; по разбору MindStudio, на 64 ГБ для 70B «становится тесно» (2026). Реальный комфорт — 8–32B; покупать M4 Pro «ради 70B» — разочарование.
- За сопоставимые деньги Strix Halo даёт вдвое больше памяти. 128 ГБ против 64 ГБ за ~$2 350 (Framework Desktop) — если нужна ёмкость, Mac проигрывает по «гигабайтам за доллар» (r/LocalLLaMA, 2026).
- Не CUDA. Нет продакшн-сервинга на vLLM и CUDA-дообучения; prefill (обработка длинного промпта) слабее, чем у видеокарты — общее ограничение Apple Silicon (MindStudio/BIZON, 2026).
- Память распаяна. Нарастить нельзя — ошиблись с объёмом, придётся брать новый Mac. Берите с запасом сразу (Starmorph, 2026).
- Путаница в ценах. Вирусные «$599 / 64 ГБ» вводят в заблуждение: 64 ГБ M4 Pro стоит ~$2 200–2 400.
Справедливости ради — плюсы делают его лучшим входом: самая низкая цена среди unified-memory машин, быстрый на реально нужных 8–32B моделях, бесшумный и экономичный (~30 Вт, $3/мес) для работы 24/7, зрелый софт и отличная остаточная стоимость.
Кому подходит, а кому ступенька выше
- Берите Mac Mini M4 Pro (48–64 ГБ), если вы один пользователь или knowledge worker, которому нужны локальные модели 8–32B для кода, чата и RAG, важны тишина, размер и работа 24/7, а 70B-на-скорости и дообучение не в приоритете.
- Берите базовый M4 (16–24 ГБ, $599–999), если хотите просто попробовать локальный ИИ на 7–13B моделях с минимальными вложениями.
- Возьмите Strix Halo, если за сопоставимые ~$2 350 важнее 128 ГБ памяти, чем экосистема Apple.
- Шагните на Mac Studio M3 Ultra или GPU-сборку, если нужны очень большие модели (235B+) либо максимальная скорость и многопользовательский сервинг.
FAQ
Какой Mac Mini выбрать для локального ИИ? Для серьёзной работы — M4 Pro с 48 ГБ (~$1 999): он комфортно тянет модели до 32B и грузит 70B в Q4. 64 ГБ (~$2 200–2 400) дают запас под 70B в более высоком качестве и несколько моделей одновременно. Базовый M4 на 16–24 ГБ ($599–999) — только чтобы попробовать на 7–13B.
Запустит ли Mac Mini M4 Pro модель на 70 миллиардов параметров? Да, в конфигурации 48–64 ГБ модель 70B в Q4 (~40 ГБ) загрузится. Но скорость — всего ~4 токена/с, и памяти останется впритык под контекст. Это рабочий вариант «при необходимости», а не для ежедневного использования. Комфортный диапазон M4 Pro — модели 8–32B.
Правда ли, что Mac Mini за $599 заменяет подписки на ИИ? За $599 продаётся базовый Mac Mini M4 с 16 ГБ — он подойдёт для 7–8B моделей и как лёгкий шлюз для ИИ-агента. Экономика реальна: перенеся рутину на локальную модель, можно сэкономить на подписках, и коробка окупается примерно за год. Но «$599 + 64 ГБ» — миф: 64 ГБ есть только у M4 Pro за ~$2 200+.
Mac Mini M4 Pro или мини-ПК на Strix Halo? За сопоставимые ~$2 350 (Framework Desktop) Strix Halo даёт 128 ГБ против 64 ГБ у Mac при почти равной пропускной способности — то есть вдвое больше памяти под модели. Mac берёт зрелым софтом (MLX, Ollama), бесшумностью и высокой остаточной стоимостью. Нужна ёмкость — Strix Halo; нужна экосистема Apple и тишина — Mac.
Сколько электричества потребляет Mac Mini как ИИ-сервер? Очень мало: около 7 Вт в простое и ~30 Вт под ИИ-нагрузкой (против 600+ Вт у сборки на видеокартах). При работе 24/7 это примерно $3 в месяц — поэтому Mac Mini популярен как тихий always-on сервер для локальных агентов.













