Коротко (TL;DR)
Framework Desktop — это модульный, ремонтопригодный взгляд на Strix Halo: компактный 4,5-литровый Mini-ITX десктоп на AMD Ryzen AI Max+ 395 со 128 ГБ unified-памяти. От компании, известной чинибельными ноутбуками, и с её фирменной идеологией: стандартный мейнборд можно купить отдельно от $799 и поставить в свой корпус, а несколько плат — соединить в кластер под модели крупнее 128 ГБ. Топ-конфиг — от $1 999.
Это та же платформа, что в базовой статье серии про Ryzen AI Max+ 395 — туда за полным разбором «что тянет Strix Halo». Здесь — про сам продукт Framework: чем он лучше готовых боксов, где у «модульности» предел и какая реальная скорость.
И сразу честная рамка. Во-первых, «модульность» тут про корпус, ввод-вывод и мейнборд, а не про память: она распаяна (32–128 ГБ) и не апгрейдится — это плата за пропускную способность 256 ГБ/с. Во-вторых, покупать Framework Desktop стоит ради ёмкости, а не скорости: плотная модель 70B упирается в пропускную способность (~2–4 токена/с), а по-настоящему быстро идут MoE-модели — gpt-oss-120B даёт ~30 ток/с против ~4 у плотной 70B на той же машине. И CUDA здесь нет.
(Данные актуальны на 15 июня 2026; цены и бенчмарки — с датами в тексте.)
Задача и бюджет
Этот десктоп — для DIY-энтузиаста локального ИИ, которому важны не только токены, но и подход: открытость, ремонтопригодность, право поставить плату в свой корпус и нарастить систему кластером. Типичный сценарий — приватный инференс больших MoE-моделей и работа с длинным контекстом дома, плюс тихая рабочая станция «всё в одном» для разработки.

Бюджет. Топ-конфигурация (Ryzen AI Max+ 395 / 128 ГБ) стартует от $1 999, полностью укомплектованная — около $2 800. База (Ryzen AI Max 385 / 32 ГБ) — от $1 099, но для ИИ нужен именно 128-ГБ вариант. Отдельный мейнборд — от $799: это и есть ключ к кластеру или сборке в нестандартном корпусе. Для локального ИИ берут версию на 128 ГБ — меньше смысла нет, а распаянную память потом не нарастить.
Трезвая оговорка: если важнее скорость токенов, чем ёмкость, за близкие деньги Mac Studio обгонит Strix Halo за счёт кратно большей пропускной способности. Framework берут за «много памяти задёшево» и за модульность, а не за рекорды t/s.
Что такое Framework Desktop
В отличие от запаянного «боксика», Framework Desktop собран на максимуме PC-стандартов:
- Mini-ITX мейнборд с ATX-хедерами, слотом PCIe x4 и полным задним I/O (2× USB4, 2× DisplayPort, HDMI, 5 Гбит Ethernet) — его можно поставить в любой ITX-корпус.
- Карты-расширения Framework (две спереди, две сзади): сами выбираете порты — USB-C, USB-A, аудиоджек, SD-ридер или картридж-накопитель.
- Стандартные компоненты: 400-Вт блок Flex ATX (с FSP), 120-мм вентиляторы (совместно с Cooler Master и Noctua, можно поставить свой), два слота M.2 2280 до 16 ТБ, Wi-Fi 7.
- DIY Edition: свой накопитель и ОС. Поддерживаются Windows 11 и Linux (Ubuntu, Fedora, игровые Bazzite/Playtron). По словам Framework, «самый простой ПК, что вы соберёте».
Внутри — APU Ryzen AI Max+ 395 (до 16 ядер Zen5, графика Radeon 8060S) и до 128 ГБ unified LPDDR5x с пропускной способностью 256 ГБ/с. В десктопном корпусе чип работает на 120 Вт в постоянной нагрузке и 140 Вт в бусте — выше, чем в ноутбучных боксах, и при этом тихо.
Что реально потянет
Главная ценность 128 ГБ — вместить большую модель целиком. Но скорость генерации зависит от пропускной способности и от типа модели, и тут начинается самое важное.Модель Тип Скорость, ток/с Комментарий Llama 8B Q4 плотная ~16 небольшая, идёт бодро DeepSeek-R1 70B плотная ~4,1 влезает, но генерация медленная gpt-oss-120B MoE (5B активных) ~30 sweet spot платформы
Цифры — с одной и той же машины (Framework Desktop, 128 ГБ). Контринтуитивный результат: 120-миллиардная MoE-модель идёт в разы быстрее «маленькой» плотной 70B. Причина проста: MoE на каждый токен считает лишь активные параметры (у gpt-oss-120B — около 5B), а плотная 70B прогоняет все 70 миллиардов. Скорость генерации почти линейно зависит от пропускной способности памяти, а её у Strix Halo всего 256 ГБ/с — поэтому плотные «тяжёлые» модели упираются в потолок.

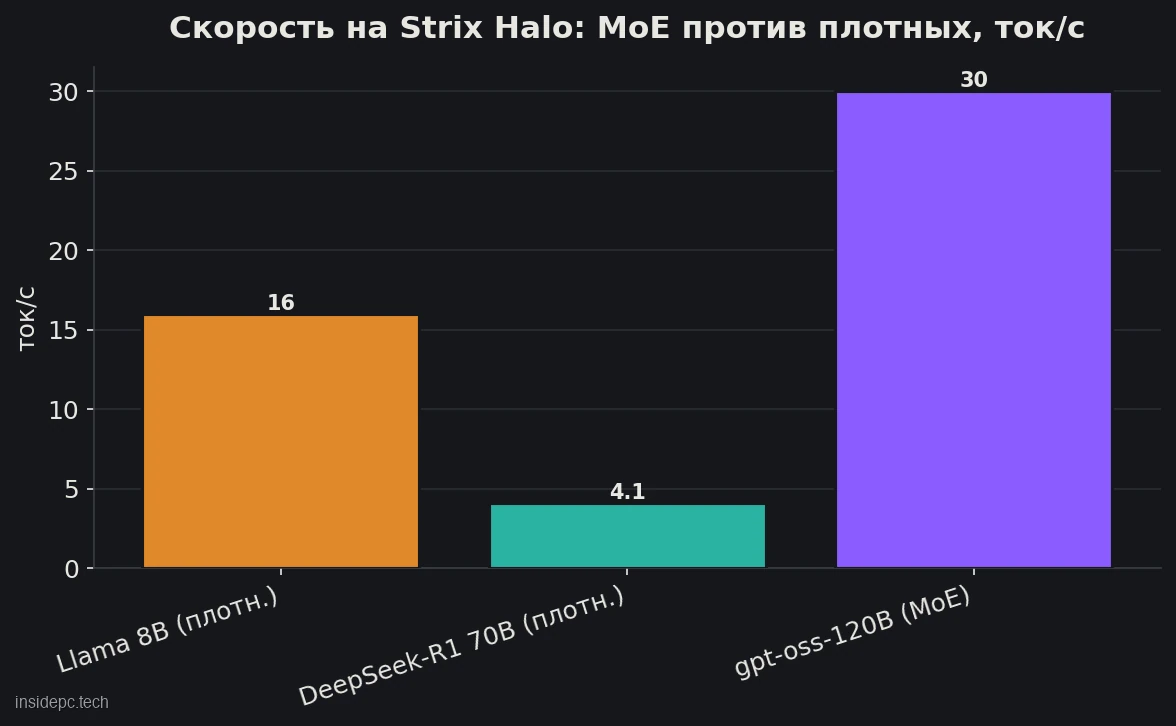
Отсюда практический вывод: Framework Desktop — машина под ёмкость и MoE, а не под скоростную плотную генерацию. 128 ГБ позволяют держать в памяти огромную MoE-модель с большим контекстом — и она будет отвечать в разговорном темпе. А вот маркетинговое «Llama 3.3 70B Q6 в реальном времени» стоит читать с поправкой: модель действительно влезает и работает, но плотная 70B идёт ~2–4 ток/с — это годится для пакетных задач, а не для бойкого чата.
Есть и второй нюанс — скорость обработки промпта (prompt-processing). У Strix Halo немного «сырого» compute, поэтому первичная прогонка длинного запроса идёт небыстро. Для обычного чата это незаметно, но в сценариях с большими входами — RAG по своей базе, «глубокий ресёрч», пакетная обработка файлов, генерация изображений — задержка до первого токена будет ощутимой. Частично это лечит NPU чипа (см. ниже), но именно генерацию токенов он не ускоряет. Если ваш профиль — длинные входы и батчи, закладывайте это в ожидания. Полная карта «что тянет Strix Halo» по моделям и квантам — в базовой статье серии.
Главная фишка: материнка отдельно и кластер
Вот чего нет у запаянных боксов. Framework продаёт мейнборд без корпуса от $799, и это открывает два сценария.
Первый — свой форм-фактор. Стандартный Mini-ITX ставится в любой корпус: тихий HTPC, ультракомпакт, кастомная стойка. Хотите лучше охлаждение или тише — берёте свой кейс и вентиляторы, плата это позволяет.
Второй, и для ИИ более интересный, — кластер. Через USB4 и 5 Гбит Ethernet несколько мейнбордов соединяются для запуска моделей, которые не влезают в 128 ГБ одной платы — вплоть до полной DeepSeek R1 671B. Framework не просто декларирует это, а собрала демонстрационный мини-рэк из четырёх мейнбордов для ИИ-тестов. Для исследователя это путь наращивать ёмкость постепенно, а не покупать сразу датацентровую карту.
Экономика кластера тоже логична: вместо одного дорогого устройства с фиксированной памятью вы стартуете с одной платы за $799–1 999 и докупаете мейнборды по мере роста задач. Связка по 5-гигабитному Ethernet — не PCIe и не NVLink, поэтому межузловой обмен медленный, и сценарий это скорее «вместить очень большую модель», чем «ускорить» её. Но для приватного инференса 200B–671B дома без датацентровой карты это рабочий и недорогой путь — комьюнити уже гоняет на таких боксах MoE-модели на сотни миллиардов параметров.
Именно это отличает Framework Desktop от собратьев на том же чипе: вы покупаете не «вещь в себе», а компонент, который можно развивать.
Framework против готовых боксов
Чип у всех боксов Strix Halo один — Ryzen AI Max+ 395, поэтому потолок производительности одинаков. Разница — в исполнении (данные на середину 2026).Решение 128 ГБ, цена Сильная сторона Слабая сторона Framework Desktop $1 999 / ~$2 800 термики, мейнборд отдельно, поддержка память распаяна GMKtec EVO-X2 ~$1 999–3 299 дешевле в максималке «бёрст»-троттлинг, вопросы к поддержке Mac Studio M4 Max (128 ГБ) ~$3 700 ПС 546 ГБ/с (~2× быстрее) дороже, экосистема Apple
Ключевое преимущество Framework для ИИ — устойчивые термики. У него десктопное охлаждение: по отзывам владельцев, он «крутит полную нагрузку весь день, не выходя за теплоотвод, не выше ~65 °C». Готовый бокс вроде GMKtec EVO-X2 «построен как ноутбук» — выигрывает в коротких бенчмарках, но в длинных троттлит и сбрасывает частоты. Для локального инференса, где модель молотит часами, это решает: важна не пиковая, а сустейн-скорость.
Второй довод — долговечность. Framework (как и HP в этом классе) даёт длинную поддержку BIOS и ремонтопригодность; к мелким брендам тут вопросы — обновления прошивок у них часто прекращаются быстро. HP лучше по сервису, но почти вдвое дороже: «за цену одного HP берут почти два Framework».
Сборка и настройка
Framework Desktop — DIY-машина, но собирается просто; куда важнее правильно настроить софт под Strix Halo.
- Сборка. Если взяли систему — добавляете свой M.2-накопитель и ставите ОС (Windows 11 или Linux; для ИИ удобнее Linux). Если взяли мейнборд отдельно — ставите его в свой ITX-корпус, подключаете 400-Вт Flex ATX питание и 120-мм охлаждение.
- Софт — главное. CUDA здесь нет, поэтому путь иной: бэкенд Vulkan (через LM Studio или llama.cpp) — самый стабильный; ROCm для этой системы пока «в бете» — возможны GPU-зависания и ошибки доступа к памяти. vLLM тоже заводится. Пошаговый разбор инференса (кванты, бэкенды) — в разделе локальные нейросети.
- NPU — нюанс. У чипа есть NPU, но в LLM он сегодня помогает только в prompt-processing (не в генерации токенов), через lemonade-server и преимущественно на Windows. На обычный чат он почти не влияет, но ускоряет обработку длинных промптов.
- Выбор модели. Под эту платформу осознанно берите MoE-модели (gpt-oss, и подобные) — они летают; плотные тяжёлые держите для пакетных задач, где скорость не критична.
Риски и слабые места
Честный список того, что нужно принять до покупки (с датами):
- Память распаяна. LPDDR5x впаяна в плату (32–128 ГБ), нарастить потом нельзя. Framework честно объясняет: модульную память на 256-битной шине с ПС 256 ГБ/с реализовать технически не вышло (128 ГБ дороже 64 ГБ на $400). Для «модульного» бренда это самый спорный компромисс — берите объём один раз и сразу 128 ГБ (офиц. блог Framework, 2026).
- Пропускная способность — потолок скорости. 256 ГБ/с — примерно треть от Mac Studio M3 Ultra (819 ГБ/с) или б/у RTX 3090 (936 ГБ/с) и в ~7 раз меньше, чем у RTX 5090 (1 792 ГБ/с). Поэтому Strix Halo силён ёмкостью, а не скоростью плотных моделей. Та же проблема — у NVIDIA DGX Spark, другого 128-ГБ unified-конкурента с близкой пропускной способностью.
- Нет CUDA. Выбор софта сужен: стабилен Vulkan, ROCm для системы «в бете» (возможны GPU-зависания), есть vLLM (reddit, конец 2025).
- Маркетинг «70B в реальном времени» оптимистичен. Плотная 70B идёт ~2–4 ток/с — влезает и работает, но не «летает»; разговорный темп дают MoE-модели (замер vs офиц. заявление, 2026).
- Медленный prompt-processing на больших входах. Нехватка «сырого» compute бьёт по RAG, deep-research и пакетной обработке файлов — задержка до первого токена ощутима (reddit, 2025).
- Цена не «бюджет». Топ-конфиг от $1 999, укомплектованный ~$2 800 (на июнь 2026); за ту же ёмкость Mac быстрее по ПС, хоть и дороже (terminalbytes, 2026).
Справедливости ради — плюсы весомы: 128 ГБ unified задёшево, устойчивые термики, мейнборд отдельно под свой корпус и кластер, ремонтопригодность и длинная поддержка, тихая работа.
Кому подходит, а кому нет
- Берите Framework Desktop, если вам нужны 128 ГБ unified задёшево под MoE-модели и длинный контекст, важны модульность, ремонтопригодность и опция «мейнборд отдельно» под свой корпус или кластер, и вы готовы к экосистеме без CUDA.
- Соберите кластер из мейнбордов, если упираетесь в 128 ГБ: USB4/5GbE связывают платы под модели вплоть до 671B без покупки датацентровой карты.
- Возьмите готовый бокс (EVO-X2), если нужен тот же чип дешевле в максимальной комплектации и вам не критичны сустейн-термики и долгая поддержка.
- Идите в Mac Studio, если важнее скорость токенов: примерно вдвое большая пропускная способность при той же ёмкости.
- Не берите Strix Halo вообще, если ваша задача — быстрая плотная 70B+ модель: тут нужна видеопамять с высокой ПС, а не unified на 256 ГБ/с.
FAQ
Чем Framework Desktop отличается от обычного мини-ПК на Strix Halo? Тем же чипом (Ryzen AI Max+ 395), но иным подходом: стандартный Mini-ITX мейнборд можно купить отдельно (от $799) и поставить в свой корпус или собрать кластер, у него лучше устойчивые термики (полная нагрузка весь день при ~65 °C против «бёрст»-троттлинга боксов) и длинная поддержка BIOS. Сам APU и память при этом такие же.
Можно ли апгрейдить память в Framework Desktop? Нет. LPDDR5x распаяна на плате (32–128 ГБ) и не наращивается — это плата за пропускную способность 256 ГБ/с, которую на модульной памяти получить не вышло. Для локального ИИ берите сразу 128-ГБ версию, потом не добавить.
Какие модели реально быстрые на Framework Desktop? MoE-модели. gpt-oss-120B (около 5B активных параметров на токен) идёт ~30 ток/с, тогда как плотная DeepSeek-R1 70B на той же машине — лишь ~4 ток/с. Причина — ограниченная пропускная способность (256 ГБ/с): плотные модели прогоняют все параметры и упираются в потолок, MoE — только активные. Берите платформу под ёмкость и MoE.
Правда ли, что Framework Desktop тянет Llama 70B в реальном времени? С поправкой. Модель на 128 ГБ действительно влезает и работает, но плотная 70B идёт ~2–4 ток/с — это годится для пакетных и фоновых задач, а не для бойкого диалога. «Разговорный» темп на этой платформе дают именно MoE-модели.
Framework Desktop или Mac Studio для локального ИИ? Зависит от приоритета. Framework даёт 128 ГБ unified заметно дешевле (~$2 000–2 800) и плюс модульность с кластером. Mac Studio дороже, но его пропускная способность выше (у M4 Max — 546 против 256 ГБ/с, около двух раз) — значит, выше скорость токенов при той же ёмкости. Нужна ёмкость и DIY — Framework; нужна скорость — Mac.