
Коротко (TL;DR)
Mistral Small — линейка открытых моделей от французской Mistral AI, единственного европейского разработчика ИИ мирового уровня. У неё репутация «самой эффективной модели в своём классе» и сильная сторона, которую ценят разработчики: нативная работа с функциями и инструментами. Но в 2026 году важно не запутаться, потому что под одним именем скрываются две очень разные модели.
- Коротко (TL;DR)
- Два Mistral Small: домашний 3.x и серверный 4
- Сколько нужно железа: VRAM, кванты и скорость
- Mistral Small 4: MoE-парадокс и reasoning_effort
- Сильная сторона: функции и агенты
- Запуск: Ollama, LM Studio, llama.cpp
- Настройка под себя: контекст, функции и API
- EU-угол: французская модель и приватность
- Русский и украинский: честная оценка
- Бенчмарки: где стоит Mistral Small
- Mistral против Qwen3, Gemma и Llama
- Когда брать Mistral Small, а когда альтернативу
- Риски и грабли
- FAQ
- Для дома — Mistral Small 3.x (24 млрд параметров). Помещается на одну видеокарту 24 ГБ, быстрая, мультимодальная (видит изображения). Это та модель, которую реально запускают на домашнем ПК.
- Для сервера — Mistral Small 4 (119 млрд, архитектура MoE). Несмотря на слово «Small», для неё нужны две серверные карты H100 — на домашней RTX 4090 она не работает. Это корпоративный инструмент.
- Общее у обеих — свобода и приватность. Лицензия Apache 2.0 (можно в коммерцию без ограничений), европейское происхождение и локальный запуск — то есть данные никуда не уходят.
Минимальное железо для домашней версии: Mistral Small 3.x в кванте Q4 занимает около 14 ГБ и комфортно работает на карте 16–24 ГБ. Честный нюанс для нашей аудитории: в русском и украинском Mistral приличен, но уступает Qwen3 и Gemma. Данные актуальны на 16 июня 2026 года.
Два Mistral Small: домашний 3.x и серверный 4
Это первое, в чём нужно разобраться, потому что выбрать не ту версию — значит либо не запустить модель вообще, либо упустить актуальную. Вот навигатор по линейке.Версия Параметры Контекст Железо Статус Для кого Small 3.1 24 млрд 128K RTX 4090 (24 ГБ) снята с поддержки (ноябрь 2025) устарела Small 3.2 24 млрд 128K RTX 4090 (24 ГБ) актуальна до июля 2026 домашний запуск Small 4 119 млрд (MoE, ~6 активных) 256K 2× H100 (сервер) актуальная флагманская сервер, бизнес
Что это значит на практике. Если у вас домашний ПК с одной видеокартой — ваш выбор Mistral Small 3.2 (последняя «домашняя» версия линейки). Версию 3.1 уже сняли с официальной поддержки, но в каталогах она ещё встречается. А Small 4, несмотря на название, — это серверная модель: её 119 млрд параметров не поместятся ни на одну потребительскую карту. Дальше мы подробно разберём обе, но фокус — на той, что реально работает дома.
Сколько нужно железа: VRAM, кванты и скорость
Для домашней Mistral Small 3.x требования скромные относительно её качества. Как обычно, модель запускают в квантованном виде (формат GGUF, ходовой квант Q4_K_M).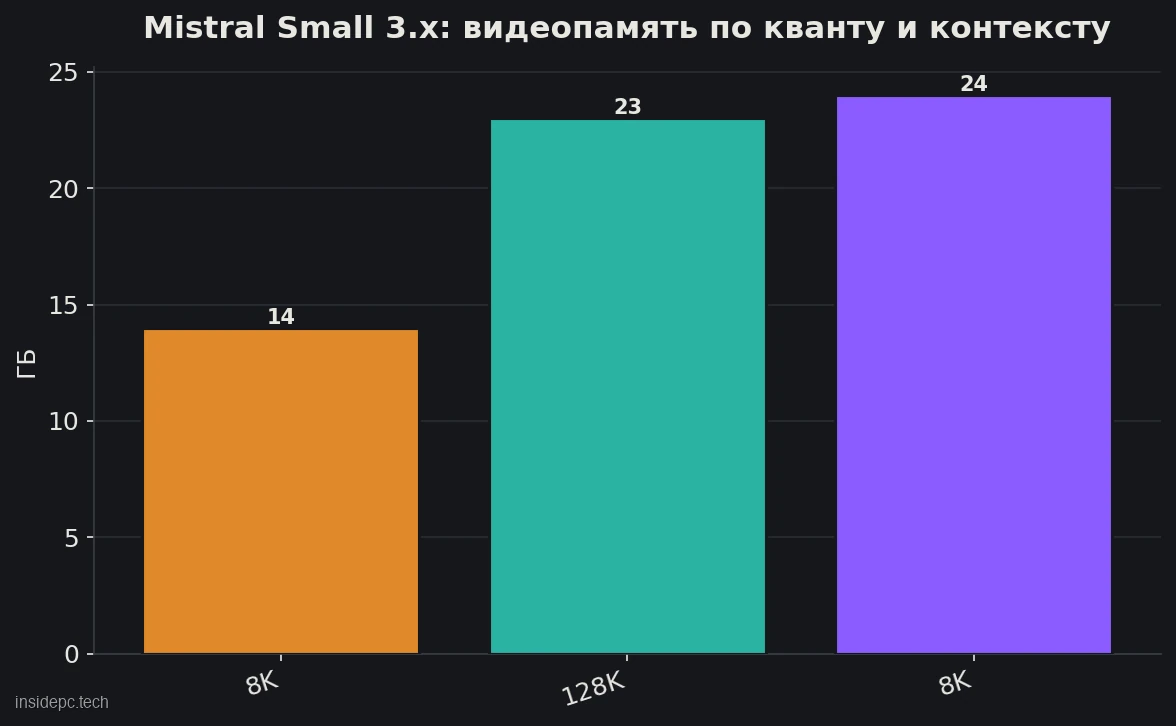
Конфигурация Small 3.x (24B) VRAM Железо Скорость Q4_K_M, контекст 8K ~13–14 ГБ RTX 4060 Ti 16 ГБ и выше ~40–70 tok/s (RTX 4090) Q4_K_M, контекст 128K ~22–23 ГБ RTX 3090/4090 (24 ГБ) зависит от загрузки Q8, контекст 8K ~24 ГБ RTX 3090/4090 (24 ГБ) ниже, зато выше качество

Главный практический вывод: 24-миллиардная Mistral Small целиком влезает на одну карту 24 ГБ — и это её ключевое преимущество. Важная поправка: видеопамять расходуется не только на веса, но и на контекст (KV-кэш), и у Mistral это особенно заметно — при полном окне 128K потребность вырастает с ~14 до ~23 ГБ. Если упёрлись в нехватку памяти, первым делом сокращайте контекст. Цифры скорости — ориентир (по замерам на RTX 4090, Q4, март 2026) и зависят от железа и кванта.
Помимо видеокарт, домашняя Mistral Small отлично идёт на Apple Silicon: на Mac с чипами M-серии и единой памятью 24 ГБ и больше она запускается через Ollama или LM Studio без отдельной видеокарты. Скорость на ноутбуке будет ниже, чем на десктопной RTX 4090, но для чата, работы с документами и агентных задач её достаточно — а тишина и низкое энергопотребление идут в плюс. Для многих владельцев MacBook это самый доступный способ держать приличную локальную модель под рукой, не покупая отдельную видеокарту и не собирая отдельный ПК специально под локальный ИИ.
А вот Mistral Small 4 в домашний бюджет не вписывается совсем: для неё нужны как минимум две серверные карты H100 (вариант INT4), а для полноценной работы — больше, либо станция вроде NVIDIA DGX Spark с большим объёмом единой памяти. На обычной RTX 4090 запустить её не получится — об этом отдельный раздел ниже.
Если выбираете видеокарту под локальный ИИ, отталкивайтесь от объёма VRAM — подробный разбор в гиде по выбору GPU для ИИ.
Mistral Small 4: MoE-парадокс и reasoning_effort
Раз уж Small 4 — флагман линейки, стоит понять, чем она интересна, даже если запускать её вы будете в облаке, а не дома.
Small 4 построена на архитектуре «смеси экспертов» (MoE): всего 119 млрд параметров, но на каждый токен активны лишь около 6 млрд (8 млрд с учётом эмбеддингов, по данным Mistral). Отсюда «парадокс»: модель по качеству играет в высшей лиге, но по скорости работает как небольшая — Mistral заявляет до 40% прироста и втрое больше запросов в секунду против Small 3. Платой за это становится память: чтобы активировать любого из экспертов, в неё нужно загрузить все 119 млрд весов. MoE экономит вычисления, но не видеопамять — поэтому домашняя карта и не тянет.
Вторая любопытная деталь Small 4 — параметр reasoning_effort (усилие на рассуждение) с несколькими уровнями: от минимального (быстрый ответ почти без размышлений) до high (модель думает дольше и тщательнее). Это не выбор между «быстрой» и «умной» моделью, а единый регулятор на каждый запрос: для простого вопроса — низкое усилие, для сложной задачи — высокое. По сути «газ и тормоз» для глубины размышления.
Сильная сторона: функции и агенты
Если у Qwen3 главный козырь — мультиязычность, а у Gemma — мультимодальность, то у Mistral это нативная работа с функциями и инструментами (function calling). Модель обучена выдавать структурированный ответ в формате JSON и вызывать внешние инструменты — это именно то, что нужно для построения агентов и автоматизаций.
На практике это значит, что Mistral Small удобно ставить в основу локального ассистента, который не просто болтает, а выполняет действия: дёргает API, заполняет формы, маршрутизирует запросы, работает по чёткому протоколу. Для разработчика, собирающего агентный пайплайн на своём железе, это весомый аргумент в пользу Mistral — особенно в связке с её низкой задержкой ответа.
Конкретный пример: на Mistral Small удобно собрать домашнего ассистента, который по команде ищет в ваших документах, добавляет события в календарь через API и форматирует ответ строго по заданной схеме — и всё это локально, без утечки данных наружу. Там, где обычная чат-модель просто опишет, что надо сделать, Mistral вернёт готовый вызов функции с параметрами, который ваш код исполнит без дополнительного разбора текста.
Запуск: Ollama, LM Studio, llama.cpp
Самый простой путь для домашней Small 3.x — Ollama:
ollama run mistral-small3.2 # актуальная домашняя версия, 24B
ollama run mistral-small # тег latest — проверьте, какую версию тянет
Здесь кроется типичная ловушка 2026 года: тег mistral-small без номера в разное время может указывать на разные версии. Чтобы получить именно то, что нужно, указывайте версию явно (mistral-small3.2), а не полагайтесь на latest. Перед скачиванием сверьтесь со страницей модели в каталоге Ollama.
LM Studio — графический интерфейс с каталогом моделей; удобно, если не любите терминал и хотите видеть настройки наглядно.
llama.cpp и vLLM — для тонкой настройки и серверных сценариев. Учтите: поддержка громоздкой Small 4 в локальных движках появилась не сразу после релиза, поэтому если планируете запускать именно её (на подходящем железе), заранее проверьте актуальный статус совместимости.
Как и другие модели, Ollama сразу поднимает локальный API на localhost:11434 в формате OpenAI — это особенно ценно для Mistral, учитывая её сильные стороны в функциях: подключайте её к агентам, ботам и редакторам кода напрямую.
Настройка под себя: контекст, функции и API
Несколько параметров, которые стоит подстроить под задачу.
- Длина контекста (num_ctx). Mistral Small держит до 128K токенов, но Ollama по умолчанию выделяет меньше. Для длинных документов поднимайте
num_ctx— помня, что контекст у Mistral заметно расходует видеопамять (с ~14 до ~23 ГБ на полном окне). - Температура. Общепринятые ориентиры сообщества: для кода, функций и фактических задач — низкая (0.1–0.3), для свободного текста — выше (около 0.7).
- Function calling. Главная фишка Mistral раскрывается через API: передавайте описание инструментов в формате, совместимом с OpenAI, и модель сама решит, когда их вызвать, и вернёт структурированный JSON. Это основа для агентов и автоматизаций.
- Системный промпт. Закрепляет роль и язык ответа; для русского и украинского явное указание языка стабилизирует вывод.
Все данные при работе с локальной Mistral остаются на вашем компьютере, а за токены платить не нужно — для приватных агентных сценариев это решающий плюс.
EU-угол: французская модель и приватность
Это наш information gain, важный именно для практичного выбора. Mistral AI — французская компания и единственный европейский разработчик ИИ мирового уровня. Для части аудитории это не абстракция, а конкретный довод.
- Юрисдикция данных. При работе с облачным API Mistral данные обрабатываются в дата-центрах ЕС, и на компанию не распространяется американский CLOUD Act. Для бизнеса, чувствительного к тому, где и по чьим законам хранятся данные, это весомо.
- Локальный запуск снимает вопрос вовсе. Когда модель работает на вашем железе, данные не уходят никуда — ни в США, ни в ЕС. С учётом полного вступления в силу европейского регламента EU AI Act в 2026 году локальное развёртывание заметно упрощает соответствие требованиям.
- Свобода лицензии. Apache 2.0 у Mistral Small снимает юридические ограничения на коммерческое использование — в отличие от лицензии Llama с её порогами.
Иными словами, Mistral Small — выбор для тех, кому важны не только бенчмарки, но и контроль над данными и юридическая чистота.
Важная оговорка: «европейская юрисдикция» значима прежде всего при работе с облачным API Mistral. При локальном запуске страна происхождения модели уже не влияет на то, где лежат ваши данные, — они на вашем диске. Но и здесь происхождение остаётся косвенным плюсом: Mistral как EU-компания строит модели с оглядкой на европейские нормы по данным и прозрачности, что снижает риск неприятных сюрпризов в лицензии или поведении модели.
Русский и украинский: честная оценка
Не будем приукрашивать: в русском и украинском Mistral Small уступает лидерам. Модель официально многоязычна и поддерживает оба языка, но качество здесь среднее — по независимым замерам у Mistral заметно ниже средняя точность на не-английских языках, а эффективность токенизации для украинского, по данным академических исследований, невысока (это означает больше токенов на тот же текст — медленнее и дороже по контексту).
Практический вывод: для задач, где главное — грамотный русский или украинский текст (перевод, копирайтинг, диалог), лучше взять Qwen3 или Gemma. А вот если язык интерфейса вторичен, а главное — скорость, функции и агентные сценарии (где данные и команды чаще на английском), Mistral остаётся сильным вариантом независимо от языка.
Бенчмарки: где стоит Mistral Small
Цифры — ориентир, официальные результаты сверяйте в карточке модели. Домашняя Small 3.1 в своё время показывала около 80,6% на тесте общих знаний MMLU и порядка 88% на программировании HumanEval — крепкий результат для 24B-модели. Серверная Small 4 заметно сильнее: примерно 71% на сложном научном GPQA Diamond и 78% на MMLU-Pro, а на отдельных бенчмарках кода она обходит даже куда более крупную GPT-OSS 120B (по данным Mistral, март 2026).
Главный практический смысл этих цифр для домашнего пользователя: Mistral Small 3.x при своих скромных 24 млрд параметров играет на уровне моделей покрупнее, особенно в задачах, требующих структурированности и точности, — а это и есть её ниша.
Mistral против Qwen3, Gemma и Llama
«Лучшей модели вообще» не бывает. Вот честное сравнение домашней Mistral Small 3.x с тремя главными соперниками в локальном сегменте (по состоянию на июнь 2026).Критерий Mistral Small Qwen3 Gemma 4 Llama Русский/украинский Средне Лучший Хорошо Средне Функции и агенты Очень сильно Хорошо Хорошо Средне Мультимодальность Vision Есть варианты Сильная Vision Лицензия Apache 2.0 Apache 2.0 Apache 2.0 Community Размер под 24 ГБ 24B (с запасом) 32B 31B 70B с offload Юрисдикция ЕС (Франция) Китай США США
Где Mistral объективно впереди: функции и агенты, компактность (24B оставляет запас памяти под контекст) и европейская юрисдикция. Где стоит выбрать иначе: для русского и украинского сильнее Qwen3 и Gemma, а если нужна продвинутая мультимодальность — у Gemma она богаче.
Когда брать Mistral Small, а когда альтернативу
Сведём выбор к простым сценариям.
Берите Mistral Small 3.x, если:
- вы строите локального агента или автоматизацию с вызовом инструментов — здесь её function calling один из лучших;
- важна компактность и скорость: 24B оставляет на карте 24 ГБ запас под контекст и отвечает с низкой задержкой;
- для вас принципиальны юрисдикция данных и свобода лицензии — европейское происхождение и Apache 2.0;
- язык интерфейса и команд преимущественно английский.
Выберите альтернативу, если:
- главное — грамотный русский или украинский текст: берите Qwen3 или Gemma;
- нужна богатая мультимодальность (фото, видео, аудио, OCR) — у Gemma она шире;
- вам нужна именно серверная мощность Small 4, но нет двух карт H100 — практичнее облачный API или другая модель под ваше железо.
Универсального ответа нет: Mistral Small — это про эффективность, функции и контроль над данными, а не про абсолютный максимум качества или лучший в классе русский.
Риски и грабли
- Путаница версий — главная ловушка. «Mistral Small» — это и снятая с поддержки 3.1, и домашняя 3.2, и серверная 4. Для дома берите именно 3.2; не пытайтесь запускать Small 4 на потребительской карте — не заработает.
- Тег
latestнепредсказуем. В Ollamamistral-smallбез номера может тянуть не ту версию — указывайте её явно. - Слабее лидеров в кириллице. Для русско- и украиноязычных текстов Mistral — не первый выбор; это её известное ограничение.
- Контекст ест память. Полное окно 128K поднимает потребность с ~14 до ~23 ГБ — на карте 16 ГБ длинный контекст не выйдет.
- Small 4 и локальные движки. Поддержка большой MoE-модели в llama.cpp/Ollama появилась не сразу; если нацелились на Small 4, проверьте актуальный статус.
- Перегрев при долгих сессиях. Длительная нагрузка греет видеокарту — следите за температурами на компактных сборках.
FAQ
Какую версию Mistral Small ставить на домашний ПК? Mistral Small 3.2 — это последняя «домашняя» версия линейки (24 млрд параметров), она помещается на карту 24 ГБ и поддерживается до июля 2026 года. Версия 3.1 уже снята с поддержки, а Small 4 — серверная и на домашней видеокарте не запустится.
Почему Mistral Small 4 не работает на моей RTX 4090? Потому что, несмотря на слово «Small», это модель на 119 млрд параметров (архитектура MoE). В память нужно загрузить все веса — это около 60 ГБ даже в формате INT4, что требует как минимум двух серверных карт H100. Для домашнего железа берите Small 3.2.
Хорош ли Mistral Small для русского языка? Приемлем, но не лучший. Mistral официально поддерживает русский и украинский, однако по качеству уступает Qwen3 и Gemma, а токенизация для украинского менее эффективна. Если язык — главное в вашей задаче, выбирайте конкурентов; если важнее скорость и функции — Mistral подойдёт.
Чем Mistral Small выделяется среди других локальных моделей? Тремя вещами: нативной работой с функциями и инструментами (удобно для агентов), компактностью при высоком качестве (24B с запасом влезает в 24 ГБ) и европейским происхождением с лицензией Apache 2.0 — то есть свободой для коммерции и контролем над данными.
Какую команду использовать для запуска в Ollama?
Для домашней версии — ollama run mistral-small3.2 с явным указанием номера. Избегайте тега mistral-small без версии: он может указывать на разные модели в разное время. Перед скачиванием сверьтесь со страницей модели в каталоге Ollama.
Сколько места на диске займёт Mistral Small? Домашняя версия 3.x в кванте Q4 — около 14 ГБ, в Q8 — порядка 24 ГБ. Закладывайте запас под несколько моделей и кэш. Ollama хранит скачанные модели в своей папке и подгружает нужную при запуске; на серверную Small 4 место не закладывайте — она в любом случае не для домашней карты.













