
Коротко (TL;DR)
Phi-4 от Microsoft — модель, которая ломает интуицию «больше параметров — умнее». При скромных 14 млрд параметров она обходит куда более крупную GPT-4o в задачах на рассуждение, математику и науку. Секрет — не в размере, а в качестве обучающих данных. Для локального запуска это идеальная история: топовый STEM-уровень на видеокарте за 8–9 ГБ.
- Коротко (TL;DR)
- Линейка Phi-4: от mini до reasoning-vision
- Секрет: почему 14B бьёт гигантов — «учебники вместо интернета»
- Phi-4-multimodal: зрение и слух
- Сколько нужно железа: VRAM, кванты и скорость
- Бенчмарки: где Phi-4 впереди, а где честно позади
- Контекст-парадокс и «только для математики»
- Запуск: Ollama, LM Studio, llama.cpp
- Настройка под себя: контекст, RAG и API
- Русский и украинский: честно слабое место
- Phi-4 против Qwen3, Gemma и Llama
- Когда брать Phi-4, а когда нет
- Риски и грабли
- FAQ
- Малая, но сильная в логике. Phi-4 14B набирает 56,1 на научном тесте GPQA против 50,6 у GPT-4o и 80,4 на математическом MATH против 74,6 (по техническому отчёту Microsoft). Это лучший «разум на гигабайт» среди открытых моделей.
- Скромное железо. В кванте Q4 модель занимает около 8–9 ГБ и запускается на видеокарте уровня RTX 3060. Лицензия — свободная MIT.
- Но это не энциклопедия. Phi-4 училась «по учебникам», а не по всему интернету, поэтому на фактических вопросах («кто написал такую-то книгу») часто ошибается. И контекст у базовой версии всего 16K токенов — меньше, чем у конкурентов.
Честный вывод для нашей аудитории: Phi-4 — узкий специалист по рассуждению и STEM, а не универсал. Для русского и украинского текста она слабее Qwen3 и Gemma. Данные актуальны на 16 июня 2026 года.
Линейка Phi-4: от mini до reasoning-vision
«Phi-4» — это не одна модель, а целое семейство под разные задачи. Phi-5, к слову, на середину 2026 года ещё не вышел, так что Phi-4 остаётся актуальной линейкой Microsoft.Модель Параметры Контекст Особенность Дата Phi-4-mini 3,8 млрд 128K Самая лёгкая, длинный контекст февраль 2025 Phi-4-multimodal 5,6 млрд 128K Текст + изображения + аудио февраль 2025 Phi-4 (базовая) 14 млрд 16K Флагман по reasoning/STEM декабрь 2024 Phi-4-reasoning / plus 14 млрд 32K Заточена под математику апрель 2025 Phi-4-reasoning-vision 15 млрд — Зрение + адаптивные рассуждения март 2026
Для большинства задач выбор такой: Phi-4 14B — если нужен максимум логики и STEM на одной карте; Phi-4-mini — если железо совсем скромное или нужен длинный контекст (у неё, что любопытно, окно больше, чем у старшей 14B); Phi-4-multimodal — если нужно работать с картинками и звуком. Версии reasoning — специализированные, о них подробнее ниже.
Секрет: почему 14B бьёт гигантов — «учебники вместо интернета»
Это главный information gain статьи. Обычно качество модели растёт с размером и объёмом данных из интернета. Microsoft пошла другим путём: около 40% обучающих данных Phi-4 — это синтетические «учебниковые» материалы, специально сгенерированные и отобранные для обучения рассуждению, а не сырой веб.

Аналогия простая: одну модель учили «по всему интернету подряд», а Phi-4 — «по тщательно составленным учебникам». В результате при том же числе параметров Phi-4 рассуждает заметно лучше — она тренировалась именно на качественных примерах решения задач, а не на случайных текстах.
У этого подхода есть оборотная сторона, о которой — отдельный честный раздел: модель, выучившая «учебник по физике», хуже помнит случайные факты из «энциклопедии». Но для задач, где нужна логика, а не эрудиция, приём работает блестяще — и именно он позволяет 14-миллиардной модели обходить гигантов.
Конкретный эффект виден на контрасте задач. Дайте Phi-4 олимпиадную задачу по математике или логическую головоломку — и она часто решит её на уровне моделей в несколько раз крупнее, потому что именно этому её и учили. Но спросите дату рождения малоизвестной исторической фигуры или сюжет редкого фильма — и она с большой вероятностью ошибётся: таких «случайных» фактов в её тщательно отобранных учебниках просто не было. Это не делает модель хуже — это делает её другой: инструментом для рассуждения, а не справочником.
Phi-4-multimodal: зрение и слух
Отдельного внимания заслуживает Phi-4-multimodal — версия на 5,6 млрд параметров, которая работает не только с текстом, но и с изображениями и звуком одновременно. Это редкое сочетание для такой компактной модели: она умеет описать картинку, разобрать диаграмму или график, распознать текст с фотографии, а также обработать аудио — например, расшифровать речь или ответить на вопрос по звуковому фрагменту.
При своих 5,6 млрд параметров и контексте 128K она остаётся лёгкой — запускается на видеокарте среднего класса, — но закрывает сразу несколько сценариев, для которых обычно нужны отдельные специализированные модели. Для локального помощника, который должен и читать документы с фото, и работать с голосом, и при этом не требовать мощного железа, Phi-4-multimodal — один из самых экономных вариантов. Учтите общий для мультимодальных моделей нюанс: обработка изображения или звука требует дополнительной видеопамяти сверх размера самой модели.
Сколько нужно железа: VRAM, кванты и скорость
Phi-4 нетребовательна — это часть её привлекательности. Как обычно, модель запускают в квантованном виде (формат GGUF).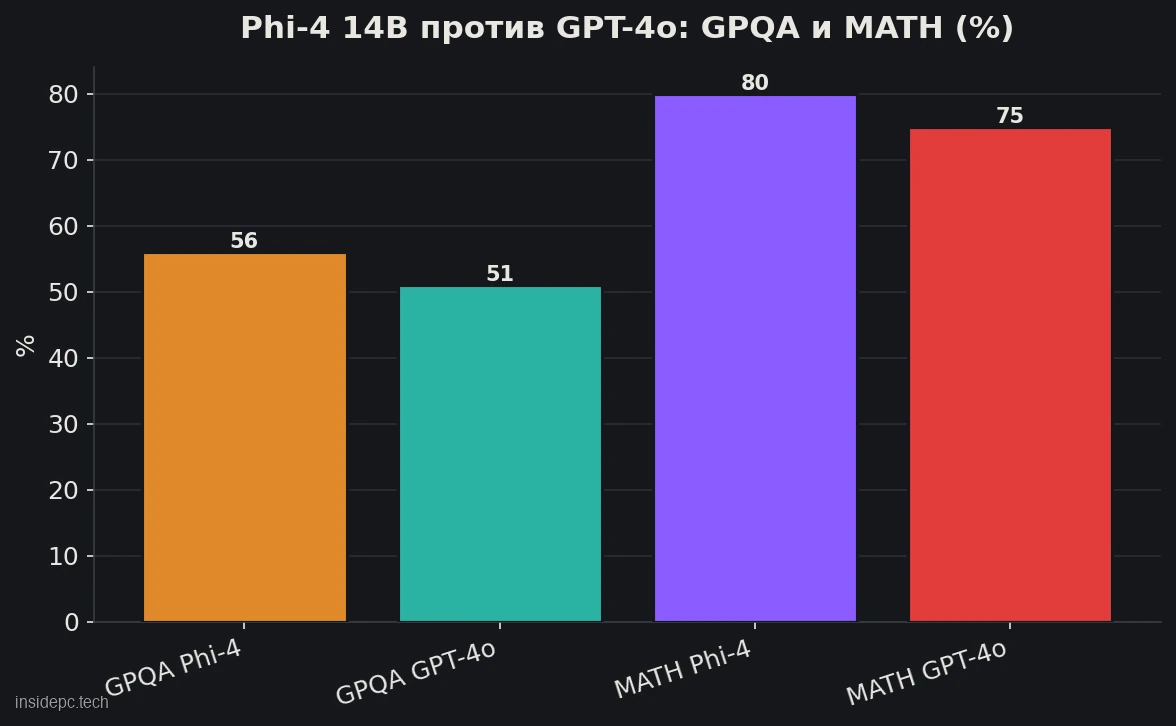
Формат Phi-4 14B VRAM Железо Скорость Q4 (INT4 / Q4_0) ~8–9 ГБ RTX 3060 8 ГБ и выше высокая (зависит от GPU)* GPTQ 4-bit (vLLM) ~11 ГБ RTX 3060 12 ГБ / 4070 высокая FP16 (без сжатия) ~32 ГБ проф. карта / 2 GPU эталон качества
*Конкретные tok/s сильно зависят от карты: на профессиональной RTX PRO 4500 Blackwell (32 ГБ GDDR7) Phi-4 14B в Q4 выдаёт около 75 токенов/с (замер сообщества, июнь 2026); на RTX 3060 заметно меньше. Размеры файлов — по каталогу Ollama; свежие замеры сверяйте там же.
Главный вывод: топовый по рассуждению Phi-4 заходит на видеокарту уровня RTX 3060 (8–9 ГБ в Q4) — это один из самых доступных способов получить сильную STEM-модель локально. Маленькая Phi-4-mini (3,8 млрд) и вовсе занимает около 2,5 ГБ (по каталогу Ollama) и работает даже на слабом железе.
Если выбираете видеокарту под локальный ИИ, отталкивайтесь от объёма VRAM — подробный разбор в гиде по выбору GPU для ИИ.
Бенчмарки: где Phi-4 впереди, а где честно позади
Сила Phi-4 — рассуждение и STEM, и здесь цифры впечатляют (по техническому отчёту Microsoft, декабрь 2024):
- GPQA (наука уровня аспирантуры): 56,1 — выше, чем у GPT-4o (50,6).
- MATH (олимпиадная математика): 80,4 — снова выше GPT-4o (74,6).
- Phi-4-reasoning на сложном AIME 2024 берёт 75,3, а версия plus — 81,3 (по карточке модели на Hugging Face, апрель 2025).
А теперь честная вторая сторона, которую большинство обзоров замалчивают. На тесте фактических знаний SimpleQA Phi-4 набирает всего 3,0 из 100. Это не баг — это следствие «учебникового» обучения: модель отлично решает задачи, но плохо помнит факты вроде «кто написал конкретный роман». Вывод практический: для фактических вопросов Phi-4 нужно подключать к базе знаний (RAG) или поиску — сама по себе она не энциклопедия.
Эта пара цифр — GPQA 56 и SimpleQA 3 — лучше всего описывает характер Phi-4. Она не «знает меньше», она устроена иначе: блестяще работает с тем, что вы ей дали, и слаба там, где нужно вспоминать факты из ниоткуда. Для разработчика или студента, который и так подкладывает модели нужный контекст (код, условие задачи, документ), это идеальный профиль; для замены поисковика или Википедии — нет. Понимание этого различия экономит часы разочарования: к Phi-4 не идут с вопросом «расскажи мне про X», к ней идут с задачей «реши, разбери, выведи».
Контекст-парадокс и «только для математики»
Два нюанса, на которых легко обжечься.
Парадокс контекста. Логично ожидать, что у более мощной модели и окно контекста больше. У Phi-4 наоборот: базовая 14B держит лишь 16K токенов, а маленькая Phi-4-mini — целых 128K. Так что если вам нужно скармливать модели длинные документы, «старшая» 14B-версия — не лучший выбор; берите mini или конкурента с большим окном. Это контринтуитивно, и об этом редко предупреждают.
Reasoning — официально только для математики. Версии Phi-4-reasoning Microsoft прямо в карточке модели помечает как предназначенные и протестированные только для математических рассуждений. Использовать их для написания текстов или ответов на общие вопросы — за пределами зоны поддержки. И ещё тонкость: по данным исследования (arXiv, апрель 2026), reasoning-версия резко теряет качество, если давать ей примеры в промпте (few-shot) — ставьте задачу напрямую, без образцов.
Запуск: Ollama, LM Studio, llama.cpp
Самый простой путь — Ollama (проверено по каталогу Ollama, июнь 2026):
ollama run phi4 # базовая 14B, STEM и логика
ollama run phi4-mini # лёгкая 3.8B, длинный контекст
ollama run phi4-reasoning # заточена под математику
ollama run phi4-reasoning:plus # максимум по математике (AIME 81,3)
Ollama сразу поднимает локальный API, совместимый с форматом OpenAI, — удобно для подключения к редакторам кода и ботам.
LM Studio — графический интерфейс с каталогом моделей; в сообществе хвалят Q8-вариант Phi-4 от Unsloth для систем с ограниченной памятью. Хороший выбор, если не любите терминал.
llama.cpp напрямую — для тонкой настройки и максимальной производительности на конкретном железе; ключевой параметр здесь — --n-gpu-layers (сколько слоёв модели вынести на видеокарту).
Типовые ошибки и решения:
- CUDA out of memory — модель не влезла в видеопамять: возьмите квант поменьше (Q4 вместо Q8) или закройте приложения, занимающие VRAM.
- Ошибка при
ollama pull— чаще всего не хватает места на диске: проверьте свободное пространство перед загрузкой. - Модель обрывает длинный ответ — упёрлись в контекст 16K: сократите запрос или перейдите на Phi-4-mini с окном 128K.
- Медленная генерация — модель считается на процессоре, а не на GPU: проверьте командой
ollama ps, на чём идёт инференс.
Совет по настройке: учитывая контекст всего 16K у базовой версии, держите запросы компактными и не пытайтесь скормить ей огромные документы целиком — для этого берите Phi-4-mini с её окном 128K.
Настройка под себя: контекст, RAG и API
Несколько практических моментов.
- Контекст (num_ctx). У базовой Phi-4 окно всего 16K — этого хватает для задач и диалога, но не для длинных документов. Не пытайтесь задать в Ollama больше, чем поддерживает модель; нужен длинный контекст — переходите на Phi-4-mini (128K).
- RAG для фактов. Поскольку Phi-4 слаба в фактической памяти, для вопросов «что/кто/когда» подключайте её к базе знаний или поиску: модель отлично рассуждает над переданным ей текстом, даже если сам факт не помнит. Это превращает её слабость в управляемое ограничение.
- Температура. Для математики, кода и логики ставьте низкую (0.1–0.3) — рассуждению не нужна «творческость». Это общепринятые ориентиры сообщества.
- Без few-shot для reasoning. Reasoning-версиям не давайте примеры в промпте — формулируйте задачу напрямую.
Режим API. Ollama поднимает сервер на localhost:11434 в формате OpenAI: подключайте Phi-4 к редакторам кода, агентам и скриптам. Для локального STEM-помощника в связке с RAG это рабочая и приватная конфигурация — данные не покидают компьютер, а за токены платить не нужно.
Русский и украинский: честно слабое место
Здесь Phi-4 проигрывает, и об этом нужно сказать прямо. Microsoft в карточке модели прямо заявляет, что Phi-4 не предназначена для мультиязычного использования: доля неанглийских данных в обучении — всего около 8%. Это видно и по цифрам: на многоязычном тесте MMLU маленькая Phi-4-mini набирает 49,3 против 64,4 у сопоставимой по размеру Qwen2.5-7B.
На практике это значит: простые запросы на русском Phi-4 поймёт и ответит, но в нюансированном тексте, аргументации и фактических вопросах на русском или украинском она заметно уступает. Если язык — главное в вашей задаче (перевод, копирайтинг, диалог на русском), берите Qwen3 или Gemma. Phi-4 же раскрывается там, где задача — логика, математика и код, а язык общения преимущественно английский.
Phi-4 против Qwen3, Gemma и Llama
«Лучшей модели вообще» не бывает. Вот честное сравнение Phi-4 14B с тремя соперниками в локальном сегменте (по состоянию на июнь 2026).Критерий Phi-4 Qwen3 Gemma 4 Llama Размер 14B (лёгкая) 8–32B 12–31B 8–70B Рассуждение / STEM Очень сильно Сильно Сильно Средне Русский/украинский Слабо Лучший Хорошо Средне Контекст (база) 16K 128K 128–256K 128K Фактическая память Слабо (нужен RAG) Хорошо Хорошо Хорошо Лицензия MIT Apache 2.0 Apache 2.0 Community
Где Phi-4 объективно впереди: рассуждение и STEM на минимальном железе — по соотношению «качество логики на гигабайт VRAM» ей мало равных. Где стоит выбрать иначе: для русского, длинного контекста и фактических задач сильнее Qwen3 и Gemma.
Когда брать Phi-4, а когда нет
Берите Phi-4, если:
- ваша задача — математика, логика, рассуждение или код, а не эрудиция;
- железо скромное (8–12 ГБ VRAM), а хочется качество уровня крупных моделей;
- нужен локальный STEM-помощник для учёбы или разработки на английском;
- важна свободная лицензия MIT для коммерческого продукта.
Выберите альтернативу, если:
- главное — грамотный русский или украинский: берите Qwen3 или Gemma;
- нужны длинные документы (контекст 16K у базовой Phi-4 мал) — берите Phi-4-mini или конкурента;
- нужна фактическая эрудиция без RAG — Phi-4 не энциклопедия.
Риски и грабли
- Не энциклопедия (главный нюанс). SimpleQA = 3 из 100: на фактических вопросах Phi-4 часто ошибается. Для таких задач обязателен RAG или поиск — модель сильна в логике, а не в памяти фактов.
- Контекст 16K у базовой версии. Меньше, чем у mini (128K) и у конкурентов. Длинные документы целиком не поместятся.
- Слабый русский и украинский. Модель официально не для мультиязычности — для кириллицы есть варианты получше.
- Reasoning — только математика. Версии Phi-4-reasoning Microsoft поддерживает только для матзадач; не используйте их как универсальный чат.
- Few-shot вредит reasoning. Примеры в промпте резко роняют качество reasoning-версий — ставьте задачу напрямую.
- Критика «переобучения». Ранние модели Phi упрекали в подгонке под бенчмарки. В Phi-4 Microsoft усилила очистку данных и в качестве проверки прогнала модель на свежих олимпиадах AMC-10 и AMC-12 (ноябрь 2024), которых не было в обучении, — результаты совпали с бенчмарками. Это весомый контраргумент, но рекордные цифры всё равно проверяйте на своих задачах.
- Перегрев при долгих сессиях. Длительная нагрузка греет видеокарту — следите за температурами на компактных сборках.
FAQ
Какая видеокарта нужна для Phi-4? Базовая Phi-4 14B в кванте Q4 занимает около 8–9 ГБ и работает на видеокарте уровня RTX 3060. Маленькая Phi-4-mini (3,8 млрд) умещается в 3–4 ГБ и пойдёт даже на слабом железе. Для полного формата FP16 нужно порядка 32 ГБ.
Правда ли, что Phi-4 обходит GPT-4o? В задачах на рассуждение и STEM — да: по тестам GPQA (56,1 против 50,6) и MATH (80,4 против 74,6) Phi-4 14B опережает гораздо более крупную GPT-4o. Но это касается именно логики и математики; в фактических знаниях и многих других задачах GPT-4o сильнее.
Почему Phi-4 ошибается в простых фактах? Потому что её учили преимущественно на синтетических «учебниковых» данных, а не на всём интернете. Она отлично решает задачи, но плохо помнит случайные факты (тест SimpleQA — всего 3 из 100). Для фактических вопросов подключайте к ней базу знаний или поиск (RAG).
Подходит ли Phi-4 для русского языка? Слабо. Microsoft официально не позиционирует Phi-4 как мультиязычную модель — неанглийских данных в обучении всего около 8%. Простые запросы она поймёт, но для качественного русского или украинского текста лучше взять Qwen3 или Gemma.
Какую версию Phi-4 выбрать для длинных документов? Phi-4-mini: несмотря на меньший размер (3,8 млрд против 14), у неё окно контекста 128K против всего 16K у базовой 14B-версии. Это тот случай, когда младшая модель подходит для длинного текста лучше старшей.
Сколько места на диске займёт Phi-4? Базовая 14B в кванте Q4 — около 9 ГБ, mini — порядка 2,5 ГБ (по каталогу Ollama), multimodal — несколько гигабайт (точный размер уточните в каталоге Ollama). Закладывайте запас под несколько версий. Ollama хранит скачанные модели в своей папке и подгружает нужную при запуске.
Чем Phi-4-reasoning отличается от обычной Phi-4? Reasoning-версия дообучена специально под математические рассуждения и держит больший контекст (32K против 16K), показывая высокие результаты на олимпиадных тестах вроде AIME. Но Microsoft поддерживает её только для матзадач — как универсальный чат или для написания текстов она не предназначена. Для общих задач берите базовую Phi-4.













