
Коротко (TL;DR)
DeepSeek-R1 — модель, которая в начале 2025 года показала, что открытая нейросеть умеет рассуждать вслух: перед ответом она выписывает цепочку мыслей в блоке <think>, как человек на черновике. По математике и логике это вывело её на уровень закрытой o1 от OpenAI. Но есть нюанс, который ломает большинство ожиданий.
- Коротко (TL;DR)
- Что такое DeepSeek-R1 и зачем она нужна
- Полная R1 671B против дистиллятов: почему 671B не для дома
- Линейка R1-Distill: шесть моделей на реальное железо
- Сколько нужно железа: дистиллят, квант и скорость
- Дистиллят — это не «маленький R1»
- Лицензия: свободная MIT и нюанс Llama-base
- Запуск: Ollama, LM Studio, llama.cpp
- Настройка под себя: контекст, рассуждения и режим API
- Бенчмарки: что реально умеет
- Русский и украинский: Qwen-base против Llama-base
- Что нового в 2025–2026
- Qwen3, QwQ, Llama: с чем сравнивать
- Риски и грабли
- FAQ
- Полная R1 — не для дома. Это модель на 671 млрд параметров; чтобы запустить её локально, нужен сервер с сотнями гигабайт памяти. На обычном ПК её не поднять.
- Домашний путь — дистилляты. DeepSeek выпустила шесть уменьшенных моделей (от 1,5B до 70B), которые «научили думать» как R1. Дистиллят на 7–8B запускается на видеокарте с 8 ГБ, а 32B-версия на карте 24 ГБ по математике обходит o1-mini.
- Важно понимать, что это. Дистиллят — не «маленькая R1», а обычная Qwen или Llama, дообученная на рассуждениях R1. Он умнее базовой модели на логических задачах, но это не та же сеть, что полная R1.
Лицензия — свободная MIT (с одной оговоркой для версий на базе Llama). Честный минус: DeepSeek — китайская модель, и политическая цензура зашита прямо в веса, то есть работает даже при локальном запуске без интернета. Разберём, какой дистиллят выбрать, чего ждать по скорости и где подводные камни.
Данные актуальны на 16 июня 2026 года.
Что такое DeepSeek-R1 и зачем она нужна
Обычная языковая модель отвечает «с ходу»: получила вопрос — сразу выдала текст. Рассуждающая (reasoning) модель работает иначе: сначала она проговаривает про себя ход решения — разбивает задачу, проверяет шаги, отбрасывает тупиковые ветки — и только потом формулирует ответ. У DeepSeek-R1 эта внутренняя «мысль» видна явно: она заключена в блок <think>...</think>, который модель генерирует перед итоговым ответом.
Такой подход резко поднимает качество на задачах, где важна логика: математика, программирование, анализ, многошаговые рассуждения. На простом вопросе «какая столица Франции» рассуждения не нужны и даже вредят (модель тратит время впустую), а вот на олимпиадной задаче или отладке кода они дают заметный прирост.

DeepSeek-R1 вышла в январе 2025 года и стала первой открытой моделью, которая догнала закрытую o1 от OpenAI по reasoning-бенчмаркам — при свободной лицензии и возможности запуска у себя. Именно это сделало её событием: рассуждающий ИИ перестал быть привилегией платных облачных сервисов.
Для домашнего пользователя у этого есть конкретный смысл. Рассуждающая модель на своём ПК — это приватный «решатель» сложных задач: разбор кода, проверка математических выкладок, помощь с логикой и анализом — без отправки данных в облако и без оплаты за каждый запрос. Цена — время: за прозрачность мысли вы платите ожиданием, пока модель «думает». Поэтому R1-дистилляты держат не вместо быстрой модели, а рядом с ней — для задач, где качество рассуждения важнее скорости.
Полная R1 671B против дистиллятов: почему 671B не для дома
Полная DeepSeek-R1 — это модель на архитектуре «смеси экспертов» (MoE) с 671 млрд параметров (из них 37 млрд активны на каждый токен) и контекстом 128K. Даже в сжатом виде её веса занимают сотни гигабайт, и для запуска нужен многокарточный сервер или рабочая станция с огромным объёмом памяти. Для домашнего ПК это нереально — ни одна потребительская видеокарта столько не вместит.
Поэтому вместе с R1 команда DeepSeek выпустила дистилляты — шесть моделей поменьше. Идея проста: взяли готовые открытые модели (Qwen и Llama) и дообучили их на 800 тысячах примеров рассуждений, сгенерированных полной R1. В результате небольшая модель перенимает манеру «думать вслух» и заметно прибавляет на логических задачах, оставаясь при этом по размеру и требованиям обычной 7B или 32B.
Ключевая мысль, которую стоит усвоить сразу: дистиллят — это не уменьшенная копия R1. Это Qwen или Llama, выученная имитировать рассуждения R1. Она лучше своей исходной версии на математике и коде, но до качества полной 671B не дотягивает. Об этом честно — в отдельном разделе ниже.
Линейка R1-Distill: шесть моделей на реальное железо
Дистилляты построены на двух семействах — Qwen и Llama. Это важно: от базы зависит и качество языков, и лицензия.Дистиллят База Параметры Контекст R1-Distill-Qwen-1.5B Qwen2.5-Math 1,5 млрд 128K R1-Distill-Qwen-7B Qwen2.5-Math 7 млрд 128K R1-Distill-Llama-8B Llama 3.1 8 млрд 128K R1-Distill-Qwen-14B Qwen2.5 14 млрд 128K R1-Distill-Qwen-32B Qwen2.5 32 млрд 128K R1-Distill-Llama-70B Llama 3.3 70 млрд 128K
Версии на базе Qwen (1.5B, 7B, 14B, 32B) обычно лучше работают с русским и украинским — об этом ниже. Версии на базе Llama (8B, 70B) сильны в английском, но наследуют лицензию Llama со своими ограничениями. Самые ходовые для дома — 7B/8B (универсал на 8 ГБ) и 32B (максимум качества на 24 ГБ).
Сколько нужно железа: дистиллят, квант и скорость
Как и другие локальные модели, дистилляты запускают в квантованном виде (формат GGUF, ходовой квант Q4_K_M). Вот сколько они занимают и какого железа требуют.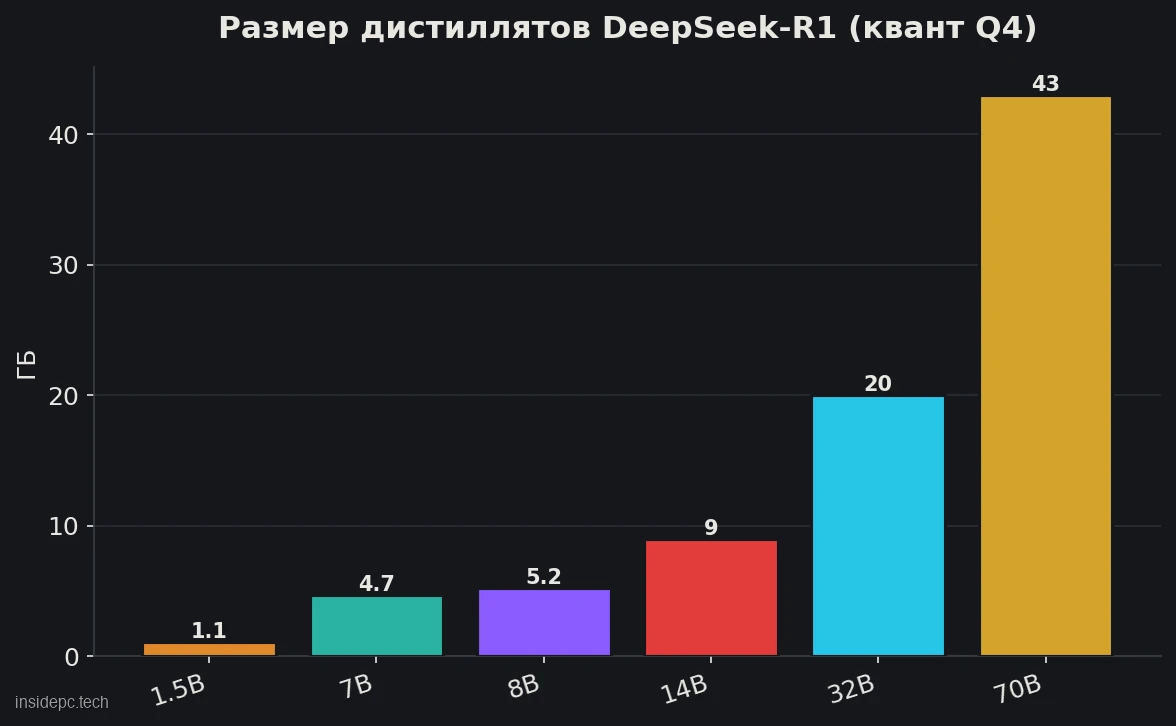
Дистиллят (Q4) Размер файла VRAM / железо Скорость* 1.5B ~1,1 ГБ 4–6 ГБ, даже CPU ~150+ tok/s 7B ~4,7 ГБ 8 ГБ (RTX 3060, Mac M1) ~90 tok/s 8B ~5,2 ГБ 8 ГБ (RTX 3060, Mac M1) ~90 tok/s 14B ~9 ГБ 12–16 ГБ (RTX 4060 Ti) ~45 tok/s 32B ~20 ГБ 24 ГБ (RTX 3090/4090) ~25–35 tok/s 70B ~43 ГБ 48 ГБ или 2 карты ~5–10 tok/s
*Скорость — ориентир на одиночной RTX 4090 (квант Q4): дистиллят по скорости инференса близок к своей базовой модели Qwen/Llama той же размерности, ведь дистилляция не меняет архитектуру. Размеры файлов — по каталогу Ollama на июнь 2026 года; точные цифры под вашу конфигурацию смотрите там же на странице модели.
Два важных уточнения:
- Размер файла — это не вся потребность в памяти. Сверх весов видеокарте нужна память под контекст (KV-кэш), а у рассуждающей модели контекст разрастается быстро: цепочка мыслей сама по себе длинная. Поэтому к размеру файла добавляйте запас — особенно если работаете с длинными задачами.
- Reasoning ест и время. Прежде чем ответить, модель генерирует рассуждения — иногда очень длинные. Обновлённая R1-0528 тратит до 23 тысяч токенов на одну олимпиадную задачу (по данным карточки модели). На слабом железе это означает заметное ожидание ответа, так что закладывайте терпение или берите модель помощнее.
Главное про скорость помнить вот что: рассуждающая модель ощущается медленнее обычной той же размерности не потому, что генерирует токены медленнее, а потому, что их у неё намного больше — на длинную цепочку мыслей уходит время. Сами по себе цифры в таблице — ориентир и зависят от железа, кванта и бэкенда; свежие замеры под конкретную модель сверяйте на её странице в каталоге Ollama.
Если выбираете видеокарту под локальный ИИ, ориентируйтесь на объём VRAM — подробный разбор в гиде по выбору GPU для ИИ.
Дистиллят — это не «маленький R1»
На этом стоит остановиться, потому что многие обзоры создают ложное впечатление. Когда вы запускаете deepseek-r1:7b, вы запускаете не уменьшенную R1, а Qwen2.5, дообученную на её рассуждениях.
Что это значит на практике:
- Плюс: дистиллят заметно умнее базовой модели на математике, логике и коде. R1-Distill-Qwen-32B набирает 72,6% на олимпиадном AIME 2024 — это лучше, чем у o1-mini от OpenAI. Для модели, которая помещается на одну карту 24 ГБ, результат отличный.
- Минус: до полной R1 (79,8% на том же AIME) и тем более до обновлённой R1-0528 (91,4%) дистилляты не дотягивают. Чем сложнее и нестандартнее задача, тем заметнее разрыв.
Вывод простой: дистиллят — это «рассуждающий апгрейд» обычной модели, отличный для домашних задач, но не замена серверной R1. Если вам нужен именно потолок качества — это облачный API DeepSeek или мощный сервер, а не домашняя видеокарта.
Лицензия: свободная MIT и нюанс Llama-base
Сама DeepSeek-R1 распространяется под лицензией MIT — одной из самых свободных: разрешено коммерческое использование, модификация и даже обучение своих моделей на выходах R1 (то, что прямо запрещает лицензия Llama). Для разработчиков это большой плюс.
Но есть тонкость с дистиллятами. Они наследуют лицензию своей базовой модели:
- дистилляты на базе Qwen (1.5B, 7B, 14B, 32B) — лицензия Apache 2.0, такая же свободная;
- дистилляты на базе Llama (8B, 70B) — лицензия Llama со своим порогом в 700 млн пользователей в месяц и ограничениями (подробнее — в обзоре Llama).
Для домашнего использования разница незаметна. Но если строите коммерческий продукт, выбирайте дистиллят на базе Qwen — он чище по лицензии.
Запуск: Ollama, LM Studio, llama.cpp
Самый простой путь — Ollama. Команды (проверено по каталогу Ollama, июнь 2026):
ollama run deepseek-r1:1.5b # самая лёгкая, даже на CPU
ollama run deepseek-r1:7b # универсал на 8 ГБ
ollama run deepseek-r1:14b # 12–16 ГБ
ollama run deepseek-r1:32b # максимум качества на 24 ГБ
ollama run deepseek-r1:70b # рабочая станция
Важная деталь: команда ollama run deepseek-r1 без указания размера тянет версию latest, а это R1-0528-Qwen3-8B — свежий дистиллят на базе Qwen3 (о нём ниже). Если вам нужен конкретный размер, указывайте тег явно.
LM Studio — графический интерфейс с каталогом моделей и удобным просмотром блока рассуждений отдельно от ответа. Хороший выбор, если не любите терминал.
llama.cpp напрямую — для максимальной производительности и тонкой настройки на мощном железе.
Совет по работе с рассуждающей моделью: не используйте few-shot промптинг (примеры в запросе). По данным анализа (Nature, 2025) примеры в промпте у R1 наоборот ухудшают качество рассуждений — модель лучше работает, когда вы просто чётко ставите задачу без образцов (zero-shot).
Настройка под себя: контекст, рассуждения и режим API
У рассуждающей модели свои особенности настройки.
- Температура. DeepSeek рекомендует для R1 не нулевую, а умеренную температуру — около 0.5–0.7 (оптимально 0.6). При нуле модель склонна зацикливаться и повторяться, а слишком высокая ломает логику рассуждений. Это важное отличие от обычных моделей, где для фактических задач ставят почти ноль.
- Длина контекста (num_ctx). Рассуждения занимают много места, поэтому скупой контекст быстро переполняется и ответ обрезается на середине мысли. В Ollama поднимайте
num_ctx(например, командой/set parameter num_ctx 8192прямо в чате) — иначе длинная цепочка<think>не уместится. Помните про расход видеопамяти на контекст. - Отделяйте мысли от ответа. Блок
<think>...</think>— это «черновик» модели, а не финальный ответ. В чате его видно, а при работе через API его обычно отрезают программно, оставляя пользователю только итог. В большинстве интерфейсов (LM Studio, веб-обёртки) рассуждения показываются отдельным сворачиваемым блоком. - Не навязывайте «думай шагами». Модель и так рассуждает по своей природе — лишние инструкции в системном промпте могут только сбить её. Чётко формулируйте саму задачу.
Режим API. Через Ollama дистиллят поднимает сервер на localhost:11434, совместимый с форматом OpenAI, — это удобно для интеграции в редакторы кода, ботов и скрипты. Но с оговоркой: ответы приходят с задержкой на рассуждения, поэтому для интерактивных сценариев (автодополнение кода в реальном времени) рассуждающая модель подходит хуже обычной. Её стихия — задачи, где важнее правильность, чем мгновенность: разбор сложного бага, математика, глубокий анализ.
Бенчмарки: что реально умеет
Цифры — с первоисточников (карточка модели и репозиторий DeepSeek). Все reasoning-бенчмарки для полной R1 и дистиллятов:Модель AIME 2024 (математика) MATH-500 DeepSeek-R1 (полная) 79,8% 97,3% OpenAI o1-1217 79,2% 96,4% R1-Distill-Qwen-32B 72,6% — R1-Distill-Qwen-7B 55,5% 92,8% OpenAI o1-mini 63,6% —
Что из этого следует: полная R1 идёт вровень с o1 (и даже чуть выше на MATH-500). Дистиллят 32B обходит o1-mini, а маленький 7B при своих скромных размерах решает 92,8% задач MATH-500 — для модели, влезающей на 8 ГБ, это очень сильно. Но помните оговорку из предыдущего раздела: бенчмарки дистиллятов — это всё ещё не уровень полной R1.
Русский и украинский: Qwen-base против Llama-base
Это наш information gain. У DeepSeek нет официальной поддержки русского как отдельной фичи, но качество текста на русском и украинском у дистиллятов сильно зависит от базовой модели.
- Дистилляты на Qwen (7B, 14B, 32B) обычно дают более грамотный русский и украинский: базовые Qwen2.5 обучены на широком многоязычном корпусе, включающем эти языки.
- Дистилляты на Llama (8B, 70B) в русском заметно слабее — у Llama эти языки не в приоритете.
Практический вывод: если для вас важен русскоязычный текст, при равном размере выбирайте Qwen-версию. Проверить легко — попросите обе модели написать короткое эссе на русском и сравните. И учтите: рассуждения (блок <think>) модель часто ведёт на английском или китайском даже при русском вопросе — это нормально, важно качество итогового ответа.
Что нового в 2025–2026
DeepSeek активно развивает линейку, и важно не запутаться в версиях.
- R1-0528 (28 мая 2025) — крупное обновление R1: точность на AIME 2025 выросла до 87,5%, добавились вызов функций и системные промпты. Платой стала «многословность» — до 23 тысяч токенов рассуждений на сложную задачу.
- R1-0528-Qwen3-8B — дистиллят нового поколения на базе Qwen3 (а не Qwen2.5). Набирает 86% на AIME 2024 — фактически на уровне гигантской Qwen3-235B, но в размере 8B. Именно эта модель теперь скрывается за тегом
latestв Ollama, и многие этого не заметили. - DeepSeek-V3.2 (декабрь 2025) и V4 Preview (апрель 2026) — это уже не reasoning-линейка R1, а универсальные модели DeepSeek. Не путайте: R1 «думает вслух», V3/V4 — обычные быстрые ответчики.
Практический приём: держите под рукой и быструю модель, и рассуждающую — простые вопросы отправляйте быстрой, а сложные логические задачи — R1-дистилляту. Reasoning стоит времени, и тратить его на «который час» смысла нет.
Qwen3, QwQ, Llama: с чем сравнивать
DeepSeek-R1 уже не единственная открытая рассуждающая модель. Вот с чем её сравнивают в 2026 году.Модель Рассуждения Русский Лицензия Замечание DeepSeek-R1 дистилляты Да (сильные) Средне (Qwen-base лучше) MIT / Apache / Llama Цензура в весах Qwen3 Да (гибрид, переключаемый) Лучший Apache 2.0 Reasoning включается командой QwQ-32B Да Хорошо Apache 2.0 Специализирован на рассуждениях Llama 3.x Нет (обычная) Средне Llama license Нужна отдельная reasoning-модель
Главный конкурент дистиллятов R1 сегодня — Qwen3: он тоже умеет рассуждать, но переключает режим командой и при этом сильнее в русском, а лицензия Apache 2.0 чище. Для многих пользователей Qwen3 стал более универсальным выбором, а R1-дистилляты берут под конкретные задачи, где важна именно их манера рассуждать.
Риски и грабли
- Цензура зашита в веса (главный честный минус). В отличие от фильтра на сайте, цензура DeepSeek работает на уровне самой модели: по данным исследования (arXiv, май 2025), около 10 тысяч запросов на политические темы про Китай вызывают отказ или искажение ответа даже при полностью локальном запуске без интернета. Нюанс по дистиллятам: версии на базе Qwen наследуют эту цензуру сильнее, а на базе Llama (8B, 70B) — лишь частично. Для большинства задач разработки и анализа фильтр незаметен, но если тема для вас важна — учитывайте.
- Дистиллят выдают за полную R1. Самое частое заблуждение.
deepseek-r1:7b— это не R1, а Qwen, выученная рассуждать. Не ждите от неё уровня серверной модели. - Reasoning медленный и многословный. Длинные цепочки мыслей съедают время и контекст. Для простых задач рассуждающая модель избыточна — используйте обычную.
- Few-shot вредит. Примеры в промпте ухудшают качество R1 — ставьте задачу напрямую, без образцов.
- Путаница R1 и V3/V4. R1 — рассуждающая, V3/V4 — обычные. Это разные линейки, проверяйте, что именно качаете.
- Нет контроля длины рассуждений. В отличие от некоторых конкурентов, у R1 нет параметра «думай не больше N токенов» — на сложной задаче она может «уйти в себя» надолго.
- Перегрев при долгих сессиях. Длинные рассуждения держат видеокарту под нагрузкой дольше обычного — следите за температурами на компактных сборках.
FAQ
Какой дистиллят DeepSeek-R1 выбрать для видеокарты на 8 ГБ? Версию 7B (на базе Qwen, лучше для русского) или 8B (на базе Llama, сильнее в английском) в кванте Q4_K_M — обе умещаются в 8 ГБ. Для русскоязычных задач берите 7B. Модели 14B и крупнее на 8 ГБ целиком не поместятся.
В чём разница между DeepSeek-R1 и DeepSeek-V3? R1 — рассуждающая модель: перед ответом она выписывает цепочку мыслей, что помогает на математике, коде и логике, но медленнее. V3 (и более новая V4) — обычная быстрая модель для повседневных ответов без видимых рассуждений. Для сложных логических задач берите R1, для скорости — V3/V4.
Работает ли цензура DeepSeek, если запустить модель локально без интернета? Да. Цензура зашита в сами веса модели, а не в сайт DeepSeek, поэтому она проявляется и при полностью офлайн-запуске. Касается она в основном политических тем, связанных с Китаем; на обычных задачах не мешает.
Дистиллят R1 на 32B — это то же самое, что полная R1? Нет. 32B-дистиллят — это Qwen2.5, дообученная на рассуждениях R1. Она сильна на логических задачах (обходит o1-mini), но это не та же сеть, что полная R1 на 671 млрд параметров, и на сложных задачах уступает ей.
Почему ollama run deepseek-r1 без размера качает 8B-модель?
Потому что тег latest в Ollama сейчас указывает на R1-0528-Qwen3-8B — свежий дистиллят на базе Qwen3. Если нужен другой размер, указывайте его явно, например deepseek-r1:32b.
Нужно ли давать R1 примеры в промпте для лучшего результата? Наоборот. По данным исследований, few-shot (примеры в запросе) ухудшает рассуждения R1. Лучше всего она работает в режиме zero-shot — когда вы просто чётко формулируете задачу без образцов.
Сколько места на диске займут дистилляты DeepSeek-R1? Зависит от размера: 7–8B в Q4 — около 5 ГБ, 14B — 9 ГБ, 32B — 20 ГБ, а 70B — порядка 43 ГБ. Самая лёгкая версия 1.5B — всего около гигабайта. Если хотите держать несколько размеров под разные задачи, закладывайте 50–80 ГБ свободного места.













