
Коротко (TL;DR)
Phi-4 від Microsoft — модель, яка ламає інтуїцію «більше параметрів — розумніше». За скромних 14 млрд параметрів вона обходить значно більшу GPT-4o в задачах на міркування, математику й науку. Секрет — не в розмірі, а в якості навчальних даних. Для локального запуску це ідеальна історія: топовий STEM-рівень на відеокарті за 8–9 ГБ.
- Коротко (TL;DR)
- Лінійка Phi-4: від mini до reasoning-vision
- Секрет: чому 14B б’є гігантів — «підручники замість інтернету»
- Phi-4-multimodal: зір і слух
- Скільки потрібно заліза: VRAM, кванти і швидкість
- Бенчмарки: де Phi-4 попереду, а де чесно позаду
- Контекст-парадокс і «тільки для математики»
- Запуск: Ollama, LM Studio, llama.cpp
- Налаштування під себе: контекст, RAG і API
- Українська і російська: чесно слабке місце
- Phi-4 проти Qwen3, Gemma і Llama
- Коли брати Phi-4, а коли ні
- Ризики й граблі
- FAQ
- Мала, але сильна в логіці. Phi-4 14B набирає 56,1 на науковому тесті GPQA проти 50,6 у GPT-4o і 80,4 на математичному MATH проти 74,6 (за технічним звітом Microsoft). Це найкращий «розум на гігабайт» серед відкритих моделей.
- Скромне залізо. У кванті Q4 модель займає близько 8–9 ГБ і запускається на відеокарті рівня RTX 3060. Ліцензія — вільна MIT.
- Але це не енциклопедія. Phi-4 училася «за підручниками», а не за всім інтернетом, тому на фактичних питаннях («хто написав таку-то книжку») часто помиляється. І контекст у базової версії всього 16K токенів — менше, ніж у конкурентів.
Чесний висновок для нашої аудиторії: Phi-4 — вузький спеціаліст із міркування та STEM, а не універсал. Для української та російської вона слабша за Qwen3 і Gemma. Дані актуальні на 16 червня 2026 року.
Лінійка Phi-4: від mini до reasoning-vision
«Phi-4» — це не одна модель, а ціле сімейство під різні задачі. Phi-5, до речі, на середину 2026 року ще не вийшов, тож Phi-4 лишається актуальною лінійкою Microsoft.Модель Параметри Контекст Особливість Дата Phi-4-mini 3,8 млрд 128K Найлегша, довгий контекст лютий 2025 Phi-4-multimodal 5,6 млрд 128K Текст + зображення + аудіо лютий 2025 Phi-4 (базова) 14 млрд 16K Флагман за reasoning/STEM грудень 2024 Phi-4-reasoning / plus 14 млрд 32K Заточена під математику квітень 2025 Phi-4-reasoning-vision 15 млрд — Зір + адаптивні міркування березень 2026
Для більшості задач вибір такий: Phi-4 14B — якщо потрібен максимум логіки та STEM на одній карті; Phi-4-mini — якщо залізо зовсім скромне або потрібен довгий контекст (у неї, що цікаво, вікно більше, ніж у старшої 14B); Phi-4-multimodal — якщо потрібно працювати з картинками та звуком. Версії reasoning — спеціалізовані, про них докладніше нижче.
Секрет: чому 14B б’є гігантів — «підручники замість інтернету»
Це головний information gain статті. Зазвичай якість моделі зростає з розміром та обсягом даних з інтернету. Microsoft пішла іншим шляхом: близько 40% навчальних даних Phi-4 — це синтетичні «підручникові» матеріали, спеціально згенеровані й відібрані для навчання міркуванню, а не сирий веб.

Аналогія проста: одну модель учили «за всім інтернетом поспіль», а Phi-4 — «за ретельно складеними підручниками». У результаті за того самого числа параметрів Phi-4 міркує помітно краще — вона тренувалася саме на якісних прикладах розв’язання задач, а не на випадкових текстах.
У цього підходу є зворотний бік, про який — окремий чесний розділ: модель, що вивчила «підручник із фізики», гірше пам’ятає випадкові факти з «енциклопедії». Але для задач, де потрібна логіка, а не ерудиція, прийом працює блискуче — і саме він дозволяє 14-мільярдній моделі обходити гігантів.
Конкретний ефект видно на контрасті задач. Дайте Phi-4 олімпіадну задачу з математики або логічну головоломку — і вона часто розв’яже її на рівні моделей у кілька разів більших, бо саме цьому її й учили. Але спитайте дату народження маловідомої історичної постаті або сюжет рідкісного фільму — і вона з великою ймовірністю помилиться: таких «випадкових» фактів у її ретельно відібраних підручниках просто не було. Це не робить модель гіршою — це робить її іншою: інструментом для міркування, а не довідником.
Phi-4-multimodal: зір і слух
Окремої уваги заслуговує Phi-4-multimodal — версія на 5,6 млрд параметрів, яка працює не лише з текстом, а й із зображеннями та звуком одночасно. Це рідкісне поєднання для такої компактної моделі: вона вміє описати картинку, розібрати діаграму чи графік, розпізнати текст із фотографії, а також обробити аудіо — наприклад, розшифрувати мовлення або відповісти на питання за звуковим фрагментом.
За своїх 5,6 млрд параметрів і контексту 128K вона лишається легкою — запускається на відеокарті середнього класу, — але закриває одразу кілька сценаріїв, для яких зазвичай потрібні окремі спеціалізовані моделі. Для локального помічника, який має й читати документи з фото, й працювати з голосом, і при цьому не вимагати потужного заліза, Phi-4-multimodal — один із найекономніших варіантів. Урахуйте загальний для мультимодальних моделей нюанс: обробка зображення чи звуку вимагає додаткової відеопам’яті понад розмір самої моделі.
Скільки потрібно заліза: VRAM, кванти і швидкість
Phi-4 невибаглива — це частина її привабливості. Як зазвичай, модель запускають у квантованому вигляді (формат GGUF).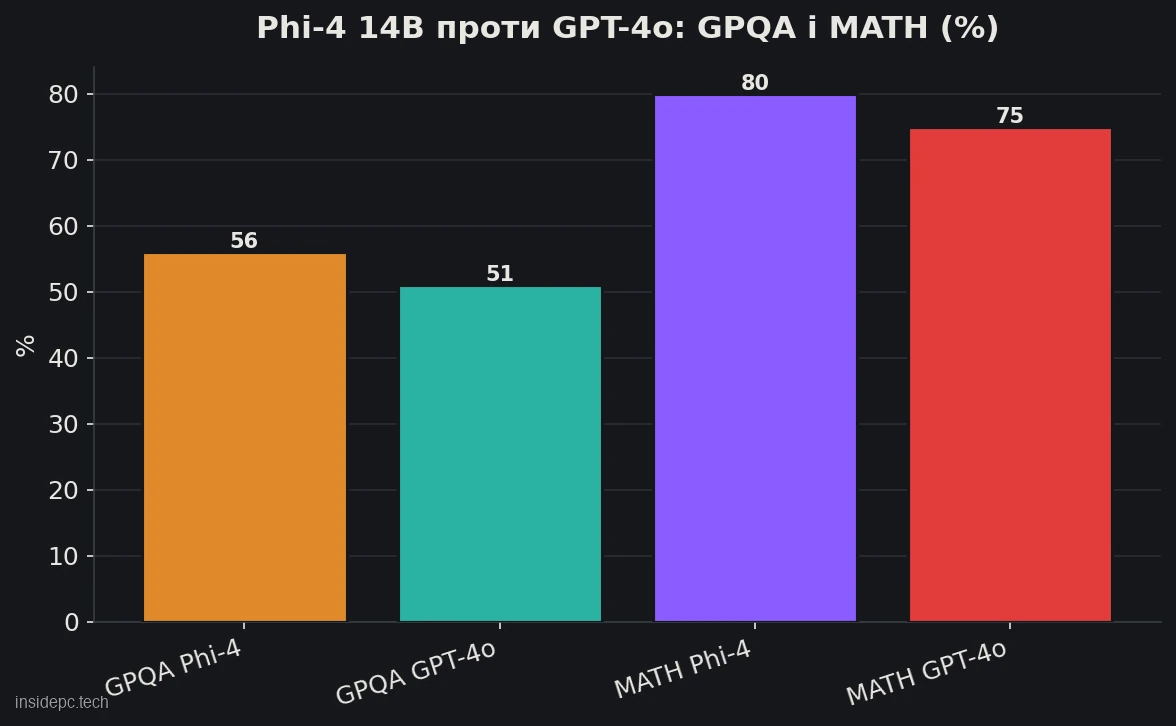
Формат Phi-4 14B VRAM Залізо Швидкість Q4 (INT4 / Q4_0) ~8–9 ГБ RTX 3060 8 ГБ і вище висока (залежить від GPU)* GPTQ 4-bit (vLLM) ~11 ГБ RTX 3060 12 ГБ / 4070 висока FP16 (без стиснення) ~32 ГБ проф. карта / 2 GPU еталон якості
*Конкретні tok/s сильно залежать від карти: на професійній RTX PRO 4500 Blackwell (32 ГБ GDDR7) Phi-4 14B у Q4 видає близько 75 токенів/с (замір спільноти, червень 2026); на RTX 3060 помітно менше. Розміри файлів — за каталогом Ollama; свіжі заміри звіряйте там же.
Головний висновок: топовий за міркуванням Phi-4 заходить на відеокарту рівня RTX 3060 (8–9 ГБ у Q4) — це один із найдоступніших способів отримати сильну STEM-модель локально. Маленька Phi-4-mini (3,8 млрд) і зовсім займає близько 2,5 ГБ (за каталогом Ollama) і працює навіть на слабкому залізі.
Якщо обираєте відеокарту під локальний ШІ, відштовхуйтеся від обсягу VRAM — докладний розбір у гіді з вибору GPU для ШІ.
Бенчмарки: де Phi-4 попереду, а де чесно позаду
Сила Phi-4 — міркування та STEM, і тут цифри вражають (за технічним звітом Microsoft, грудень 2024):
- GPQA (наука рівня аспірантури): 56,1 — вище, ніж у GPT-4o (50,6).
- MATH (олімпіадна математика): 80,4 — знову вище GPT-4o (74,6).
- Phi-4-reasoning на складному AIME 2024 бере 75,3, а версія plus — 81,3 (за карткою моделі на Hugging Face, квітень 2025).
А тепер чесна друга сторона, яку більшість оглядів замовчує. На тесті фактичних знань SimpleQA Phi-4 набирає всього 3,0 зі 100. Це не баг — це наслідок «підручникового» навчання: модель чудово розв’язує задачі, але погано пам’ятає факти на кшталт «хто написав конкретний роман». Висновок практичний: для фактичних питань Phi-4 потрібно підключати до бази знань (RAG) або пошуку — сама по собі вона не енциклопедія.
Ця пара цифр — GPQA 56 і SimpleQA 3 — найкраще описує характер Phi-4. Вона не «знає менше», вона влаштована інакше: блискуче працює з тим, що ви їй дали, і слабка там, де потрібно згадувати факти нізвідки. Для розробника чи студента, який і так підкладає моделі потрібний контекст (код, умову задачі, документ), це ідеальний профіль; для заміни пошуковика або Вікіпедії — ні. Розуміння цієї відмінності економить години розчарування: до Phi-4 не йдуть із питанням «розкажи мені про X», до неї йдуть із задачею «розв’яжи, розбери, виведи».
Контекст-парадокс і «тільки для математики»
Два нюанси, на яких легко обпектися.
Парадокс контексту. Логічно очікувати, що в потужнішої моделі й вікно контексту більше. У Phi-4 навпаки: базова 14B тримає лише 16K токенів, а маленька Phi-4-mini — цілих 128K. Тож якщо вам потрібно згодовувати моделі довгі документи, «старша» 14B-версія — не найкращий вибір; беріть mini або конкурента з більшим вікном. Це контрінтуїтивно, і про це рідко попереджають.
Reasoning — офіційно тільки для математики. Версії Phi-4-reasoning Microsoft прямо в картці моделі позначає як призначені й протестовані тільки для математичних міркувань. Використовувати їх для написання текстів чи відповідей на загальні питання — за межами зони підтримки. І ще тонкість: за даними дослідження (arXiv, квітень 2026), reasoning-версія різко втрачає якість, якщо давати їй приклади в промпті (few-shot) — ставте задачу напряму, без зразків.
Запуск: Ollama, LM Studio, llama.cpp
Найпростіший шлях — Ollama (перевірено за каталогом Ollama, червень 2026):
ollama run phi4 # базова 14B, STEM і логіка
ollama run phi4-mini # легка 3.8B, довгий контекст
ollama run phi4-reasoning # заточена під математику
ollama run phi4-reasoning:plus # максимум з математики (AIME 81,3)
Ollama одразу піднімає локальний API, сумісний із форматом OpenAI, — зручно для підключення до редакторів коду й ботів.
LM Studio — графічний інтерфейс із каталогом моделей; у спільноті хвалять Q8-варіант Phi-4 від Unsloth для систем з обмеженою пам’яттю. Хороший вибір, якщо не любите термінал.
llama.cpp напряму — для тонкого налаштування й максимальної продуктивності на конкретному залізі; ключовий параметр тут — --n-gpu-layers (скільки шарів моделі винести на відеокарту).
Типові помилки й рішення:
- CUDA out of memory — модель не влізла у відеопам’ять: візьміть квант менший (Q4 замість Q8) або закрийте застосунки, що займають VRAM.
- Помилка при
ollama pull— найчастіше бракує місця на диску: перевірте вільний простір перед завантаженням. - Модель обриває довгу відповідь — уперлися в контекст 16K: скоротіть запит або перейдіть на Phi-4-mini з вікном 128K.
- Повільна генерація — модель рахується на процесорі, а не на GPU: перевірте командою
ollama ps, на чому йде інференс.
Порада щодо налаштування: з огляду на контекст усього 16K у базової версії, тримайте запити компактними й не намагайтеся згодувати їй величезні документи цілком — для цього беріть Phi-4-mini з її вікном 128K.
Налаштування під себе: контекст, RAG і API
Кілька практичних моментів.
- Контекст (num_ctx). У базової Phi-4 вікно всього 16K — цього вистачає для задач і діалогу, але не для довгих документів. Не намагайтеся задати в Ollama більше, ніж підтримує модель; потрібен довгий контекст — переходьте на Phi-4-mini (128K).
- RAG для фактів. Оскільки Phi-4 слабка у фактичній пам’яті, для питань «що/хто/коли» підключайте її до бази знань або пошуку: модель чудово міркує над переданим їй текстом, навіть якщо сам факт не пам’ятає. Це перетворює її слабкість на кероване обмеження.
- Температура. Для математики, коду та логіки ставте низьку (0.1–0.3) — міркуванню не потрібна «творчість». Це загальноприйняті орієнтири спільноти.
- Без few-shot для reasoning. Reasoning-версіям не давайте приклади в промпті — формулюйте задачу напряму.
Режим API. Ollama піднімає сервер на localhost:11434 у форматі OpenAI: підключайте Phi-4 до редакторів коду, агентів і скриптів. Для локального STEM-помічника у зв’язці з RAG це робоча й приватна конфігурація — дані не покидають комп’ютер, а за токени платити не потрібно.
Українська і російська: чесно слабке місце
Тут Phi-4 програє, і про це потрібно сказати прямо. Microsoft у картці моделі прямо заявляє, що Phi-4 не призначена для мультимовного використання: частка неанглійських даних у навчанні — всього близько 8%. Це видно й за цифрами: на багатомовному тесті MMLU маленька Phi-4-mini набирає 49,3 проти 64,4 у співставної за розміром Qwen2.5-7B.
На практиці це означає: прості запити українською Phi-4 зрозуміє й відповість, але в нюансованому тексті, аргументації та фактичних питаннях українською чи російською вона помітно поступається. Якщо мова — головне у вашій задачі (переклад, копірайтинг, діалог українською), беріть Qwen3 або Gemma. Phi-4 ж розкривається там, де задача — логіка, математика й код, а мова спілкування переважно англійська.
Phi-4 проти Qwen3, Gemma і Llama
«Найкращої моделі взагалі» не буває. Ось чесне порівняння Phi-4 14B з трьома суперниками в локальному сегменті (станом на червень 2026).Критерій Phi-4 Qwen3 Gemma 4 Llama Розмір 14B (легка) 8–32B 12–31B 8–70B Міркування / STEM Дуже сильно Сильно Сильно Середньо Українська/російська Слабко Найкращий Добре Середньо Контекст (база) 16K 128K 128–256K 128K Фактична пам’ять Слабко (потрібен RAG) Добре Добре Добре Ліцензія MIT Apache 2.0 Apache 2.0 Community
Де Phi-4 об’єктивно попереду: міркування та STEM на мінімальному залізі — за співвідношенням «якість логіки на гігабайт VRAM» їй мало рівних. Де варто обрати інакше: для української, довгого контексту й фактичних задач сильніші Qwen3 і Gemma.
Коли брати Phi-4, а коли ні
Беріть Phi-4, якщо:
- ваша задача — математика, логіка, міркування чи код, а не ерудиція;
- залізо скромне (8–12 ГБ VRAM), а хочеться якість рівня великих моделей;
- потрібен локальний STEM-помічник для навчання чи розробки англійською;
- важлива вільна ліцензія MIT для комерційного продукту.
Оберіть альтернативу, якщо:
- головне — грамотна українська чи російська: беріть Qwen3 або Gemma;
- потрібні довгі документи (контекст 16K у базової Phi-4 малий) — беріть Phi-4-mini або конкурента;
- потрібна фактична ерудиція без RAG — Phi-4 не енциклопедія.
Ризики й граблі
- Не енциклопедія (головний нюанс). SimpleQA = 3 зі 100: на фактичних питаннях Phi-4 часто помиляється. Для таких задач обов’язковий RAG або пошук — модель сильна в логіці, а не в пам’яті фактів.
- Контекст 16K у базової версії. Менше, ніж у mini (128K) і в конкурентів. Довгі документи цілком не помістяться.
- Слабка українська і російська. Модель офіційно не для мультимовності — для кирилиці є варіанти кращі.
- Reasoning — тільки математика. Версії Phi-4-reasoning Microsoft підтримує тільки для матзадач; не використовуйте їх як універсальний чат.
- Few-shot шкодить reasoning. Приклади в промпті різко роняють якість reasoning-версій — ставте задачу напряму.
- Критика «перенавчання». Ранні моделі Phi докоряли за підгонку під бенчмарки. У Phi-4 Microsoft посилила очищення даних і для перевірки прогнала модель на свіжих олімпіадах AMC-10 та AMC-12 (листопад 2024), яких не було в навчанні, — результати збіглися з бенчмарками. Це вагомий контраргумент, але рекордні цифри все одно перевіряйте на своїх задачах.
- Перегрів за довгих сесій. Тривале навантаження гріє відеокарту — стежте за температурами на компактних збірках.
FAQ
Яка відеокарта потрібна для Phi-4? Базова Phi-4 14B у кванті Q4 займає близько 8–9 ГБ і працює на відеокарті рівня RTX 3060. Маленька Phi-4-mini (3,8 млрд) уміщується у 3–4 ГБ і піде навіть на слабкому залізі. Для повного формату FP16 потрібно порядку 32 ГБ.
Чи правда, що Phi-4 обходить GPT-4o? У задачах на міркування та STEM — так: за тестами GPQA (56,1 проти 50,6) і MATH (80,4 проти 74,6) Phi-4 14B випереджає значно більшу GPT-4o. Але це стосується саме логіки й математики; у фактичних знаннях і багатьох інших задачах GPT-4o сильніша.
Чому Phi-4 помиляється в простих фактах? Тому що її вчили переважно на синтетичних «підручникових» даних, а не на всьому інтернеті. Вона чудово розв’язує задачі, але погано пам’ятає випадкові факти (тест SimpleQA — усього 3 зі 100). Для фактичних питань підключайте до неї базу знань або пошук (RAG).
Чи підходить Phi-4 для української мови? Слабко. Microsoft офіційно не позиціонує Phi-4 як мультимовну модель — неанглійських даних у навчанні всього близько 8%. Прості запити вона зрозуміє, але для якісного українського чи російського тексту краще взяти Qwen3 або Gemma.
Яку версію Phi-4 обрати для довгих документів? Phi-4-mini: попри менший розмір (3,8 млрд проти 14), у неї вікно контексту 128K проти всього 16K у базової 14B-версії. Це той випадок, коли молодша модель підходить для довгого тексту краще за старшу.
Скільки місця на диску займе Phi-4? Базова 14B у кванті Q4 — близько 9 ГБ, mini — порядку 2,5 ГБ (за каталогом Ollama), multimodal — кілька гігабайтів (точний розмір уточніть у каталозі Ollama). Закладайте запас під кілька версій. Ollama зберігає завантажені моделі у своїй папці й підвантажує потрібну при запуску.
Чим Phi-4-reasoning відрізняється від звичайної Phi-4? Reasoning-версія донавчена спеціально під математичні міркування і тримає більший контекст (32K проти 16K), показуючи високі результати на олімпіадних тестах на кшталт AIME. Але Microsoft підтримує її тільки для матзадач — як універсальний чат чи для написання текстів вона не призначена. Для загальних задач беріть базову Phi-4.













