
Коротко (TL;DR)
GPT-OSS — це маленька сенсація: уперше з 2019 року (з часів GPT-2) OpenAI випустила відкриті моделі, які можна завантажити й запустити в себе. Реліз відбувся 5 серпня 2025 року, і для локального ШІ це подія — тепер на вашому диску може працювати модель із фірмовим «характером» OpenAI і настроюваним міркуванням.
- Коротко (TL;DR)
- Чому це історично важливо
- Дві версії і MoE-парадокс
- Скільки потрібно заліза: VRAM, кванти і швидкість
- reasoning_effort: налаштування глибини мислення
- Формат Harmony: важлива грабля
- Бенчмарки: близько до o3-mini і o4-mini
- Запуск: Ollama, LM Studio, llama.cpp
- Налаштування під себе: контекст, міркування і API
- Українська і російська: чесно неясно
- GPT-OSS проти Qwen3, DeepSeek і Llama
- Коли брати GPT-OSS, а коли ні
- Ризики й граблі
- FAQ
- Дві версії. gpt-oss-20B — для домашнього ПК (запускається на відеокарті 16 ГБ), і gpt-oss-120B — для робочої станції або сервера (потрібна карта на 80 ГБ). Обидві побудовані на архітектурі «суміші експертів» (MoE) і поширюються під вільною ліцензією Apache 2.0.
- Сильний reasoning на скромному залізі. За бенчмарками gpt-oss-20B змагається із закритою o3-mini, а 120B — з o4-mini. У моделей настроювана глибина міркувань і вбудована робота з інструментами.
- Але є чесні мінуси. Модель схильна до надмірних відмов («не можу допомогти»), вимагає особливого формату промптів Harmony, не працює із зображеннями і — важливо — не оновлювалася з моменту виходу.
Мінімальне залізо для домашньої версії: gpt-oss-20B у рідному кванті займає близько 16 ГБ, а на 8 ГБ її можна запустити з вивантаженням частини в оперативну пам’ять. Дані актуальні на 16 червня 2026 року.
Чому це історично важливо
Щоб оцінити подію, потрібен контекст. З 2019 року OpenAI не випускала відкритих моделей — компанія, з якої почався бум ChatGPT, тримала ваги закритими. GPT-OSS зламала цю паузу: це перші за шість років моделі OpenAI, які можна завантажити, запустити офлайн, вивчити й вбудувати у свій продукт.
Особливо важлива ліцензія Apache 2.0 — одна з найвільніших. На відміну від ліцензії Llama з її обмеженнями, gpt-oss можна використовувати комерційно без порогів і погоджень (є лише мінімальна політика використання — дотримуватися закону). Для бізнесу, якому потрібен «рушій рівня OpenAI» на власних серверах без надсилання даних у хмару, це відкрило нові двері.

Для нашої аудиторії це особливо цінно в одному сценарії — суверенітет даних. Юристи, лікарі, компанії з чутливою інформацією дедалі частіше обирають локальний ШІ не заради швидкості, а заради того, щоб дані фізично не покидали їхню інфраструктуру. GPT-OSS з її Apache 2.0 ідеально лягає в цю нішу: «рушій у стилі OpenAI» можна розгорнути на власному сервері, в офісі чи навіть на ноутбуці — без підписок, без передавання запитів назовні і без юридичних обмежень на комерцію. До GPT-OSS такої опції «від самої OpenAI» просто не існувало.

Дві версії і MoE-парадокс
GPT-OSS вийшла у двох розмірах, і обидва використовують архітектуру «суміші експертів» (MoE) — саме вона пояснює, чому навіть велика модель вміщується на одну карту.Модель Усього параметрів Активних на токен Контекст Під яке залізо gpt-oss-20B 20,9 млрд 3,6 млрд 128K Відеокарта 16 ГБ (RTX 4090/3090) gpt-oss-120B 116,8 млрд 5,1 млрд 128K Карта 80 ГБ (H100) / робоча станція 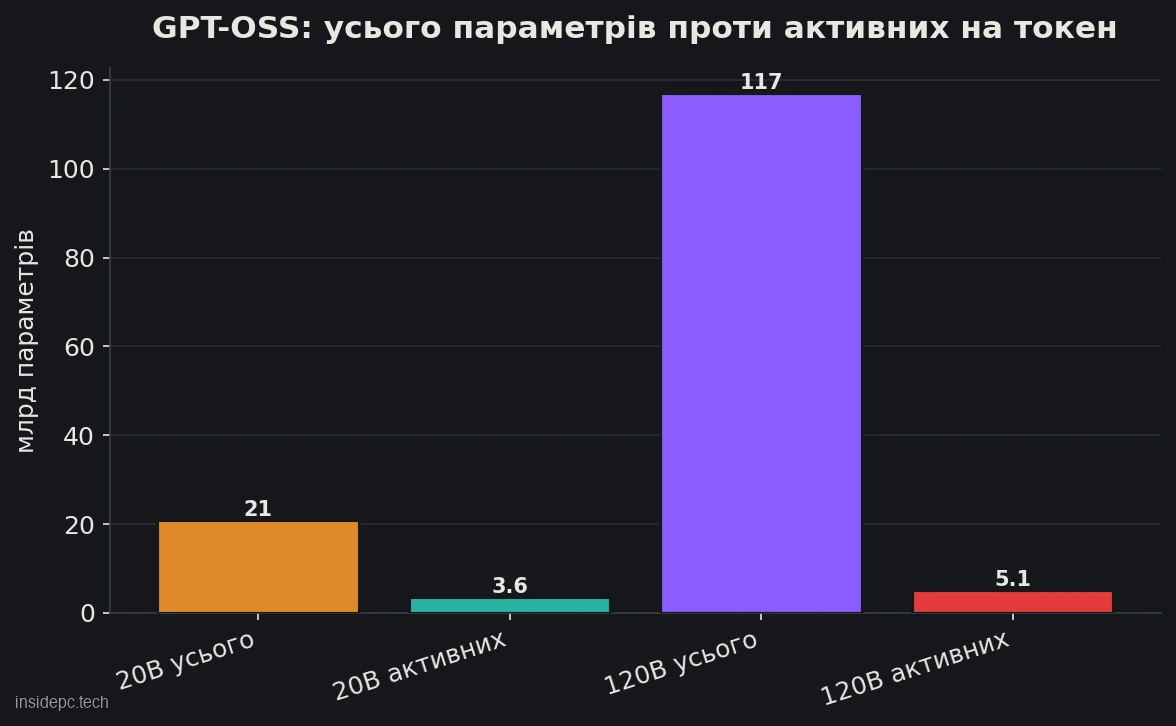
Ось у чому «парадокс»: gpt-oss-120B містить майже 117 млрд параметрів, але на кожен токен задіює лише близько 5 млрд. За рахунок цього модель «думає» швидко, як невелика. Але — і це ключовий нюанс для вибору заліза — у пам’ять потрібно завантажити всі ваги, а не лише активні. Тому 120B вимагає близько 80 ГБ відеопам’яті (це рівень серверної карти H100), а 20B — близько 16 ГБ. MoE економить швидкість обчислень, але не обсяг пам’яті.
Практичний висновок: для домашнього ПК реалістична gpt-oss-20B. Версія 120B — для тих, у кого є професійна карта на 80 ГБ або система з великою єдиною пам’яттю (наприклад, Mac або міні-ПК з unified memory).
Скільки потрібно заліза: VRAM, кванти і швидкість
У GPT-OSS є приємна особливість: моделі постачаються в рідному кванті MXFP4 — тобто OpenAI одразу навчила й виклала їх у стиснутому 4-бітному форматі, без втрати якості від стороннього квантування. Це означає, що «офіційні» вимоги вже враховують стиснення.Версія (MXFP4) VRAM Залізо Швидкість* gpt-oss-20B ~16 ГБ RTX 4090 ~180–220 tok/s gpt-oss-20B ~16 ГБ RTX 3090 ~144–160 tok/s gpt-oss-20B (offload) 8 ГБ + ОЗП RTX 3060/3070 + RAM ~40 tok/s gpt-oss-120B ~80 ГБ H100 (серверна) висока gpt-oss-120B unified ~96 ГБ+ Mac Studio / міні-ПК скромніше, залежить від чипа
*Швидкість — за замірами спільноти (червень 2026); залежить від кванта, контексту й бекенда.
Що звідси випливає:

- 16 ГБ VRAM (RTX 4090, 3090) — комфортний дім для gpt-oss-20B: швидкість на RTX 4090 сягає 180–220 токенів/с (за замірами спільноти), на RTX 3090 — близько 144–160.
- 8 ГБ VRAM — 20B усе ще можна запустити, вивантаживши частину шарів-«експертів» в оперативну пам’ять. Швидкість впаде приблизно до 40 токенів/с, але модель запрацює навіть на скромній карті. Це корисний прийом для старого заліза.
- 80 ГБ — територія 120B: професійна карта H100 або платформа з великою єдиною пам’яттю.
Окремо про 120B на «домашньому» залізі: завдяки MoE її реально запустити не лише на серверній H100, а й на системах із великою єдиною пам’яттю — Mac Studio або міні-ПК на чипах з unified memory (близько 96 ГБ і більше). Швидкість там скромніша, ніж на H100, але сам факт, що модель майже на 117 млрд параметрів крутиться на компактному пристрої, — заслуга саме архітектури «суміші експертів». Докладніше про такі платформи — у наших оглядах збірок для локального ШІ.
Важлива технічна заувага: рідний формат MXFP4 нативно прискорюється лише на нових архітектурах (Hopper і Blackwell). На відеокартах до них — це споживчі RTX 30xx і 40xx — формат емулюється програмно: модель запуститься, але без апаратного виграшу у швидкості від самого MXFP4. Нативне прискорення є на RTX 50xx і серверних картах.
Якщо обираєте відеокарту під локальний ШІ, відштовхуйтеся від обсягу VRAM — докладний розбір у гіді з вибору GPU для ШІ.
reasoning_effort: налаштування глибини мислення
Як і деякі сучасні моделі, GPT-OSS уміє «думати вголос» (chain-of-thought) перед відповіддю. Але в неї є зручний регулятор — параметр reasoning_effort з трьома рівнями: low, medium, high.
Задається він прямо в системному промпті рядком на кшталт Reasoning: low. Логіка проста:
- low — швидка відповідь з мінімумом міркувань, для простих задач і чату;
- medium — баланс, підходить для більшості задач;
- high — максимум роздумів, для складної математики, логіки й коду.
Це зручно: не потрібно тримати дві моделі — «швидку» й «розумну». Для рутини ставите low, для важкої задачі перемикаєте на high прямо в запиті. Що вищий рівень, то довша відповідь і більша витрата контексту на міркування — про це варто пам’ятати на довгих діалогах.
На практиці це виглядає так: додаєте в системний промпт рядок Reasoning: high — і на питання за складним алгоритмом модель розгорне докладний ланцюжок міркувань, перш ніж дати відповідь. Поставите Reasoning: low — і простий запит вона закриє миттєво, не витрачаючи час на роздуми. Одна модель перетворюється на гнучкий інструмент: від швидкого асистента до вдумливого «розв’язувача» задач — перемиканням одного рядка.
Формат Harmony: важлива грабля
Це нюанс, на якому спотикаються при ручному запуску. GPT-OSS навчена працювати в особливому форматі промптів під назвою Harmony — зі спеціальними роздільниками на кшталт <|channel|>analysis (міркування) і final (підсумкова відповідь). Якщо подати моделі запит «не в тому форматі», вона поводиться дивно: плутає міркування з відповіддю або видає сміття.
Хороша новина: при запуску через Ollama або LM Studio про це думати не потрібно — вони застосовують формат Harmony автоматично. Граблі виникають, якщо ви використовуєте llama.cpp або власний код напряму й неправильно налаштували шаблон промпта (відомі несумісності з jinja-шаблонами). Висновок практичний: для простого локального запуску беріть Ollama — вона позбавляє від мороки з форматом. Ручне налаштування Harmony потрібне лише просунутим користувачам при інтеграції у свій код.
Бенчмарки: близько до o3-mini і o4-mini
Головне досягнення GPT-OSS — високий рівень міркувань для відкритих моделей. За офіційними даними OpenAI (серпень 2025):
- gpt-oss-120B на максимальному reasoning бере 92,5% на складному математичному AIME 2025, 80,1% на науковому GPQA Diamond і 62,4% на тесті програмування SWE-Bench — це майже рівень закритої o4-mini.
- gpt-oss-20B показує 91,7% на AIME 2025 і 71,5% на GPQA — на рівні або вище o3-mini.
Що це означає на практиці: для задач на математику, логіку й код GPT-OSS дає результат, співставний із закритими «mini»-моделями OpenAI, але локально й безкоштовно. Застереження стандартне: бенчмарки відображають вузькі задачі; на реальній роботі багато що залежить від ваших сценаріїв, і рекордні цифри варто перевіряти самому.
Ще важлива деталь: ці рекордні цифри досягаються на максимальному рівні міркувань (high). На low модель відповідає швидше, але простіше — і результат на складних бенчмарках падає. Це не обман, а та сама гнучкість: ви самі вирішуєте, витрачати чи ні обчислення на глибоке міркування. Для повсякденних задач вистачає medium, а high прибережіть для дійсно важких питань.
Якщо порівнювати з іншими відкритими «думаючими» моделями, GPT-OSS грає в одній лізі з DeepSeek-R1 і reasoning-режимом Qwen3, але з двома застереженнями. Плюс GPT-OSS — настроюване зусилля міркувань і сумісність з екосистемою OpenAI «з коробки». Мінус — ті самі надмірні відмови й відсутність даних щодо української. Для суто математичних і логічних задач англійською GPT-OSS — один із найсильніших відкритих варіантів; для україномовної роботи й стабільної чуйності конкуренти виглядають надійніше.
Запуск: Ollama, LM Studio, llama.cpp
Найпростіший шлях — Ollama, який сам розбирається з форматом Harmony (перевірено за каталогом Ollama, червень 2026):
ollama run gpt-oss:20b # домашня версія, 16 ГБ
ollama run gpt-oss:120b # серверна версія, 80 ГБ
Ollama одразу піднімає локальний API, сумісний із форматом OpenAI, — зручно для підключення до редакторів коду й ботів.
LM Studio — графічний інтерфейс із каталогом моделей і зручним переглядом міркувань окремо від відповіді; теж коректно працює з Harmony.
llama.cpp і vLLM — для тонкого налаштування й серверних сценаріїв. Тут будьте уважні до формату Harmony і шаблонів промптів (див. розділ вище). Наприклад, запуск 120B через сервер llama.cpp виглядає так:
llama-server -hf ggml-org/gpt-oss-120b-GGUF -c 0 -fa --jinja --reasoning-format none
Прапор --jinja підключає шаблон Harmony — без нього відповіді будуть «сирими».
Типові помилки й рішення:
- Модель «не вміщується» — для 20B потрібно 16 ГБ; на 8 ГБ запускайте з вивантаженням шарів в оперативну пам’ять, на 120B знадобиться 80 ГБ.
- Дивні відповіді (міркування впереміш із відповіддю) — порушено формат Harmony; використовуйте Ollama або LM Studio, які застосовують його самі.
- Повільно на старій карті — формат MXFP4 не прискорюється апаратно до Hopper; це очікувано, модель усе одно працює.
Налаштування під себе: контекст, міркування і API
Кілька параметрів під свої задачі.
- Рівень міркувань. Головний регулятор GPT-OSS —
reasoning_effortу системному промпті (low/medium/high). Тримайте low для рутини й перемикайте на high для складних задач; це прямо впливає на швидкість і витрату контексту. - Довжина контексту (num_ctx). Модель підтримує 128K токенів, але Ollama за замовчуванням виділяє менше. Для довгих документів піднімайте
num_ctxвручну, пам’ятаючи про витрату відеопам’яті на контекст — з увімкненими міркуваннями він росте швидше. - Температура. Для математики, коду й точних задач ставте низьку (0.1–0.3). Це загальноприйняті орієнтири спільноти.
- Вбудовані інструменти. GPT-OSS з коробки вміє викликати інструменти (пошук, виконання коду) — це допомагає обійти обмеження «знань до червня 2024», підключивши моделі актуальне джерело даних. Налаштування залежить від бекенда.
Режим API. Ollama піднімає сервер на localhost:11434 у форматі OpenAI: підключайте GPT-OSS до редакторів коду, агентів і скриптів. Оскільки формат API збігається з хмарним OpenAI, перевести наявний проєкт із хмарного GPT на локальний gpt-oss часто можна зміною адреси сервера — дані при цьому лишаються на вашому комп’ютері.
Українська і російська: чесно неясно
Тут доведеться бути відвертими. OpenAI не публікувала окремих даних щодо якості української та російської в GPT-OSS. Модель багатомовна, але в офіційному багатомовному тесті (MMMLU, 14 мов) української та російської немає — тому судити про якість напряму за цифрами не можна.
За непрямими ознаками (загальний рівень багатомовності 81,3% у 120B і 75,7% у 20B на підтримуваних мовах, за даними model card) можна очікувати пристойного, але не топового результату українською. Є й тривожний сигнал: незалежне red-teaming-дослідження (arXiv, жовтень 2025) щодо «мов із малим ресурсом» виявило в GPT-OSS підвищену схильність до вигадування фактів рідкісними мовами. Українська до рідкісних не належить, але обережність не завадить.
Практичний висновок: якщо українська чи російська — головне у вашій задачі, надійніше взяти Qwen3, у якого обидві мови офіційно підтримані й перевірені. GPT-OSS беріть заради reasoning та екосистеми OpenAI, а якість українською перевіряйте на своїх прикладах.
GPT-OSS проти Qwen3, DeepSeek і Llama
«Найкращої моделі взагалі» не буває. Ось чесне порівняння з трьома суперниками в локальному сегменті (станом на червень 2026).Критерій GPT-OSS Qwen3 DeepSeek-R1 Llama Міркування Сильне (настроюване) Сильне (гібрид) Сильне Середнє Українська/російська Неясно (немає даних) Найкращий Середньо Середньо Ліцензія Apache 2.0 Apache 2.0 MIT Community Мультимодальність Ні (тільки текст) Є варіанти Ні Vision (окр. версії) Відмови (цензура) Високі Середні (політика) У вагах (Китай) Низькі Оновлення Немає (з серп. 2025) Регулярні Регулярні Регулярні
Де GPT-OSS сильна: reasoning рівня o-mini локально, вільна ліцензія і «характер» OpenAI. Де варто обрати інакше: для української сильніший Qwen3, для роботи з картинками — Gemma або Qwen-Vision, а якщо важливі регулярні оновлення — у конкурентів із ними краще.
Коли брати GPT-OSS, а коли ні
Зведемо вибір до простих сценаріїв.
Беріть GPT-OSS, якщо:
- вам потрібен сильний reasoning локально рівня o3-mini/o4-mini для математики, логіки й коду;
- важливий суверенітет даних і вільна ліцензія Apache 2.0 для бізнесу;
- ви хочете «характер» та екосистему OpenAI на своєму залізі, зі звичним API;
- задачі переважно англійською, а формат запитів — структурований.
Оберіть альтернативу, якщо:
- головне — українська чи російська: беріть Qwen3;
- потрібна мультимодальність (картинки, звук) — GPT-OSS тільки текст, дивіться Gemma або Qwen-Vision;
- вас дратують надмірні відмови — Qwen3 і DeepSeek дають менше «не можу допомогти»;
- важливі регулярні оновлення — GPT-OSS не розвивається з серпня 2025.
Універсальної відповіді немає: GPT-OSS — це про reasoning і контроль над даними в екосистемі OpenAI, а не про найкращу українську чи свіжість ваг.
Ризики й граблі
- Надмірні відмови (головний мінус). GPT-OSS успадкувала суворі налаштування безпеки OpenAI і часто відмовляється відповідати навіть на безневинні запити, заповнюючи «міркування» посиланнями на політику. Це відома претензія спільноти; частина користувачів іде на «розцензуровані» (abliterated) версії від сторонніх авторів — урахуйте, що це вже не офіційна модель.
- Не оновлювалася з релізу. На червень 2026 — це понад 10 місяців без нових ваг. Спільнота розчарована: модель хороша, але OpenAI не розвиває її, тоді як Qwen і DeepSeek випускають версії регулярно.
- Тільки текст. GPT-OSS не працює із зображеннями і звуком — для мультимодальних задач потрібна інша модель.
- Знання до червня 2024. Модель не знає подій після цієї дати; для актуальної інформації підключайте пошук або базу знань (RAG).
- Формат Harmony. При ручній інтеграції легко помилитися з форматом промпта — для простого запуску використовуйте Ollama.
- MXFP4 без прискорення на старих картах. На відеокартах до Hopper рідний формат емулюється програмно — без приросту швидкості.
- Перегрів за довгих сесій. Тривале навантаження гріє відеокарту — стежте за температурами на компактних збірках.
FAQ
Чи потягне GPT-OSS моя відеокарта на 8 ГБ? Версію gpt-oss-20B — так, але із заувагою: 16 ГБ для неї штатний обсяг, а на 8 ГБ її запускають із вивантаженням частини «експертів» в оперативну пам’ять. Швидкість впаде приблизно до 40 токенів/с, але модель запрацює. Версія 120B на 8 ГБ неможлива — їй потрібно близько 80 ГБ.
Чи потрібен сервер H100 для gpt-oss-120B? Практично так: 120B вимагає близько 80 ГБ відеопам’яті, і це рівень професійної карти H100. Альтернатива — система з великою єдиною пам’яттю (наприклад, Mac або міні-ПК з unified memory від 96 ГБ). На звичайній ігровій відеокарті 120B не запуститься; для дому беріть 20B.
Що таке формат Harmony і чи потрібно з ним возитися? Це особливий формат промптів, під який навчена GPT-OSS (з роздільниками міркувань і відповіді). При запуску через Ollama або LM Studio він застосовується автоматично — возитися не потрібно. Ручне налаштування потрібне лише при інтеграції через llama.cpp або власний код.
Чи хороший GPT-OSS для української мови? Точних даних немає — української та російської немає в офіційних багатомовних тестах моделі. Очікувано результат пристойний, але не найкращий серед відкритих моделей. Для україномовних задач надійніший Qwen3; GPT-OSS перевіряйте на своїх прикладах.
Чому GPT-OSS часто відмовляється відповідати? Це наслідок суворих налаштувань безпеки OpenAI: модель перестраховується і відхиляє навіть безневинні запити. Відома претензія до неї. Частина користувачів переходить на сторонні «розцензуровані» версії, але це вже неофіційні моделі — застосовуйте на свій ризик.
Чим gpt-oss-20B відрізняється від 120B, окрім розміру? Здебільшого потужністю міркувань і вимогами до заліза. 20B запускається на домашній карті 16 ГБ і за бенчмарками співставна з o3-mini; 120B сильніша (рівень o4-mini), але вимагає близько 80 ГБ відеопам’яті. Архітектура в обох однакова (MoE), ліцензія і формат теж — вибір зводиться до того, яке залізо у вас є.
Чи можна використовувати GPT-OSS у комерційному продукті? Так. Ліцензія Apache 2.0 дозволяє комерційне використання без порогів і роялті; є лише мінімальна політика використання (дотримуватися застосовного законодавства). Це робить GPT-OSS зручним вибором для вбудовування в продукти й розгортання на власних серверах.
Чи оновлюється GPT-OSS? На червень 2026 — ні. З моменту релізу в серпні 2025 OpenAI не випустила нових ваг, і спільнота відзначає це як розчарування: модель хороша, але «застигла». Конкуренти на кшталт Qwen і DeepSeek за цей час випустили кілька оновлень. Якщо для вас важлива свіжість моделі, враховуйте це при виборі.














