



Коротко (TL;DR)
GLM — линейка открытых моделей китайской лаборатории Zhipu AI (бренд Z.ai), и к 2026 году это один из самых сильных открытых проектов для кодинга и агентных задач. По качеству программирования GLM подбирается к закрытым моделям уровня Claude, при свободной лицензии MIT. Но с локальным запуском всё непросто, и дальше разберём, что реально поднять дома, а что нет.
- Коротко (TL;DR)
- Что такое GLM и почему за ним сложно угнаться
- Архитектура MoE: почему 355 млрд не значит 355 млрд вычислений
- Можно ли запустить GLM дома: разбор по вариантам
- GLM-4.7-Flash: реальный домашний вариант
- Запуск большой модели: MoE-offloading и обязательный —jinja
- Кванты GGUF: что качать для GLM
- Многокарточный сервер: vLLM и SGLang
- Агентный кодинг: GLM Coding Plan как дешёвая альтернатива Claude
- Сколько это стоит: три пути к GLM
- Reasoning и thinking-режим
- Что нового в GLM-5.2: контекст на миллион токенов
- Бенчмарки: близко к Claude в коде
- Русский и украинский: слабое место
- GLM против DeepSeek, Qwen3 и GPT-OSS
- Риски и грабли
- FAQ
- Бешеный темп. За год вышло целое поколение: GLM-4.5 (июль 2025) → 4.6 → 4.7 → GLM-5 → GLM-5.2 с контекстом на миллион токенов (июнь 2026). Угнаться за обновлениями сложно даже специалистам.
- Полная модель — не для дома. Старшие GLM — это MoE-гиганты на 355 млрд параметров и больше; чтобы запустить их без компромиссов, нужен сервер с несколькими картами H100. На обычном ПК полную версию «в лоб» не поднять.
- Но дома кое-что реально. Для домашнего железа есть компактная GLM-4.7-Flash (около 30 млрд параметров), которая заходит на одну RTX 3090/4090, а большую модель можно запустить через хитрый приём с выгрузкой в оперативную память — медленно, но работает.
Вывод для нашей аудитории: GLM — выбор для разработчиков, которым нужен мощный агентный кодер, и кто готов либо к серьёзному железу, либо к компромиссам по скорости. Русский и украинский — слабое место (это признаёт и сама Z.ai). Данные актуальны на 16 июня 2026 года.
Что такое GLM и почему за ним сложно угнаться
GLM (General Language Model) — семейство моделей лаборатории Zhipu AI, одного из ведущих китайских ИИ-разработчиков, выступающего под брендом Z.ai. Главный фокус линейки — программирование и агентные задачи: GLM хорошо пишет код, вызывает инструменты и работает в режиме автономного агента.
Отличает GLM невероятный темп выпуска. Вот хронология меньше чем за год:

- GLM-4.5 (июль 2025) — 355 млрд параметров, заявка на лучший открытый кодер.
- GLM-4.6 (сентябрь 2025) — рост качества, контекст до 200K токенов.
- GLM-4.7 (декабрь 2025) — 358 млрд (32 млрд активных), рекордные результаты в агентных тестах.
- GLM-4.7-Flash (январь 2026) — компактная версия (30 млрд параметров, контекст 131K) для скромного железа.
- GLM-5 / 5.1 / 5.2 (2026) — новое поколение; версия 5.2 (13 июня 2026) принесла рабочий контекст на 1 млн токенов.
Вся линейка выходит под лицензией MIT — одной из самых свободных: модель можно использовать коммерчески, модифицировать и встраивать без ограничений. Для бизнеса это большой плюс. Минус другой — за таким темпом сложно угнаться, и к моменту, когда вы освоите одну версию, выходит следующая.

Для пользователя у этого есть и плюс, и минус. Плюс — вы получаете очень свежую технологию: открытые модели GLM регулярно оказываются среди сильнейших в мире на момент выхода. Минус — экосистема не успевает: готовые кванты, гайды и интеграции отстают от релизов, и иногда новейшую версию проще попробовать через облако Z.ai, чем ждать, пока её удобно завернут для локального запуска.
Архитектура MoE: почему 355 млрд не значит 355 млрд вычислений
GLM построена на архитектуре «смеси экспертов» (MoE), и это важно для понимания требований к железу. У GLM-4.6, например, 355 млрд параметров всего, но лишь около 32 млрд активны на каждый токен. То есть модель «думает» со скоростью 32-миллиардной, хотя хранит знания 355-миллиардной.
Звучит так, будто и памяти нужно под 32 млрд — но нет. В память приходится загружать все 355 млрд весов, потому что заранее неизвестно, какой «эксперт» понадобится на следующем шаге. MoE экономит скорость вычислений, а не объём памяти. Именно поэтому даже сжатая GLM-4.6 не помещается на домашнюю видеокарту: её веса в приличном кванте занимают сотни гигабайт.
У компактной GLM-4.7-Flash параметров куда меньше — около 30 млрд всего и 3,6 млрд активных, и вот она уже реалистична для дома. А у нового поколения GLM-5 размеры снова выросли (старшая версия — порядка 745 млрд, из них 44 млрд активных). Запомните правило: для домашнего запуска смотрите на размер модели целиком, а «активные параметры» — это про скорость, не про память. У этого подхода есть и приятная сторона: при той же скорости MoE-модель «знает» больше, чем плотная того же быстродействия, потому что хранит знания всех экспертов. Именно поэтому GLM при своих 32 активных миллиардах конкурирует по качеству с куда более тяжёлыми плотными моделями — но платит за это требованиями к памяти.
Можно ли запустить GLM дома: разбор по вариантам
Главный вопрос — что реально из линейки GLM поднимается на домашнем железе. Разберём по вариантам.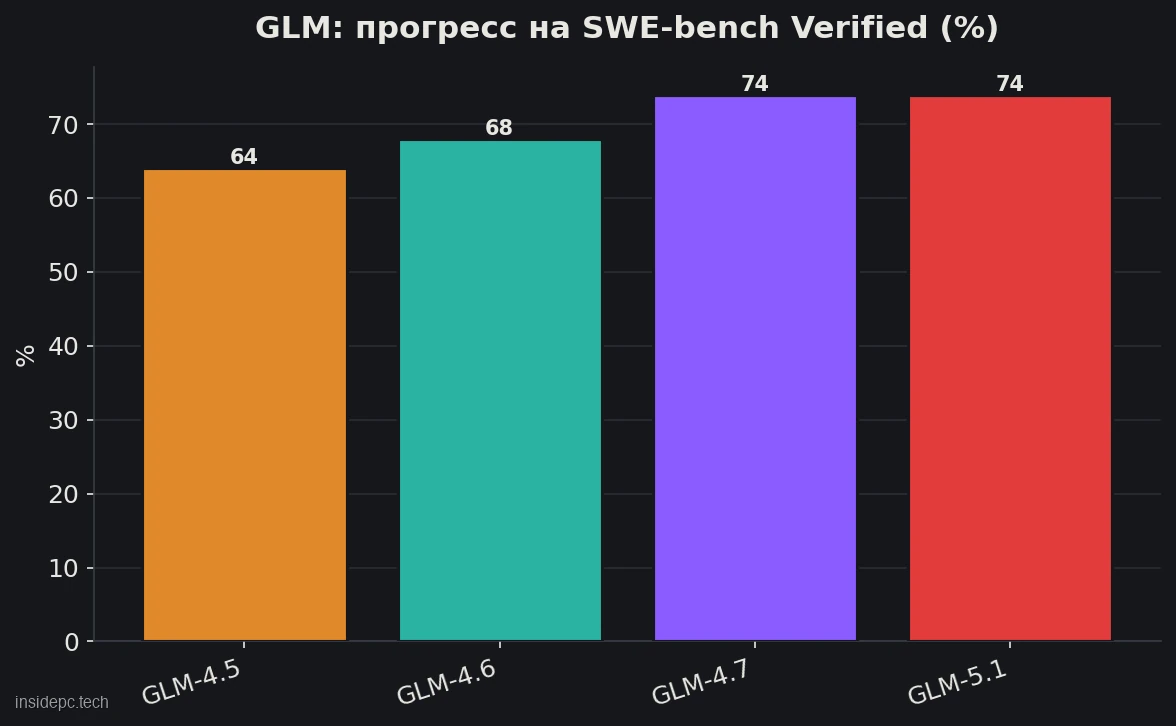
Вариант Что нужно Реалистично дома? GLM-4.7-Flash (30B) RTX 3090/4090 (24 ГБ), Q4 Да — основной домашний путь GLM-4.5-Air (106B) ~64–128 ГБ unified memory (Mac) или мультикарта С оговорками Полная GLM-4.6/4.7 (355B+) через offloading 24 ГБ VRAM + 128 ГБ ОЗУ, низкая скорость Технически да, ~5 tok/s Полная GLM в BF16 Сервер 16×H100 Нет, только дата-центр
Вывод простой: для большинства домашних пользователей реальный путь — GLM-4.7-Flash. Она запускается на одной топовой видеокарте и даёт большую часть пользы старших версий в агентном кодинге. Если же хочется именно полную модель и есть много оперативной памяти — её можно поднять через выгрузку в ОЗУ (об этом ниже), но готовьтесь к скорости в единицы токенов в секунду. Полноценно большую GLM тянет только серверное железо.
Отдельный домашний путь к средним версиям — техника Apple с большой единой памятью: Mac Studio со 128–512 ГБ unified memory способен поднять GLM-4.5-Air и даже подступиться к большим версиям, чего не сделать на обычной видеокарте. Это недёшево, но тише и компактнее, чем многокарточный сервер, — и для тех, кто уже в экосистеме Apple, часто самый простой путь к крупным локальным моделям.
Если присматриваетесь к платформе с большим объёмом единой памяти под такие модели, загляните в наши обзоры сборок для локального ИИ.
GLM-4.7-Flash: реальный домашний вариант
Flash — это та версия GLM, ради которой стоит читать дальше, если у вас обычный мощный ПК. При размере около 30 млрд параметров она в кванте Q4_K_M занимает порядка 23 ГБ и заходит на видеокарту 24 ГБ (RTX 3090, 4090). По замерам сообщества скорость декодирования на RTX 3090 — около 93 токенов/с при коротком контексте (4K) и порядка 43 токенов/с при 32K (квант Q4_K_M), что для агентной работы более чем достаточно.
Запуск проще всего через Ollama или LM Studio — они сами разбираются с форматом промптов. В Ollama это одна команда (сверяйтесь с актуальным каталогом — модель свежая):
ollama run glm-4.7-flash
Flash хороша тем, что при скромных требованиях сохраняет фирменную сильную сторону GLM — агентный кодинг и работу с инструментами. Для локального помощника разработчика на одной карте это сейчас один из лучших открытых вариантов; полноценные старшие версии добавят качества, но потребуют несопоставимо больше железа.
Запуск большой модели: MoE-offloading и обязательный —jinja
Если вы всё-таки хотите запустить полную GLM-4.6/4.7 на домашнем железе, есть приём, который меняет правила игры, — выгрузка MoE-экспертов в оперативную память. Идея в том, чтобы держать на видеокарте только «лёгкие» части модели (внимание, эмбеддинги), а тяжёлых «экспертов» оставить в обычной ОЗУ. В llama.cpp это делается флагом:
llama-server -m glm-4.6-Q2_K_XL.gguf -ot ".ffn_.*_exps.=CPU" --jinja
Тогда вместо сотен гигабайт видеопамяти достаточно 24 ГБ VRAM плюс много (от 128 ГБ) системной ОЗУ. Платой становится скорость — около 5 токенов в секунду на тяжёлой модели, но сам факт, что фронтир-модель работает на домашнем ПК, дорогого стоит.
И отдельное предупреждение, на котором спотыкаются почти все: флаг --jinja обязателен. Без него ломаются вызовы инструментов и режим рассуждений — модель будет вести себя странно или вовсе не работать в агентном режиме. Это самая частая «невидимая» ошибка при ручном запуске GLM; если что-то пошло не так — первым делом проверьте, что --jinja на месте.
Кванты GGUF: что качать для GLM
Для запуска GLM в llama.cpp нужен файл GGUF в подходящем кванте — и здесь у больших моделей свои крайности. Команда Unsloth выкладывает «динамические» кванты GLM-4.6 с очень широким разбросом по размеру:
- TQ1_0 — экстремальное сжатие, около 84 ГБ. Влезает на скромное по меркам гигантов железо, но качество заметно падает.
- Q2_K_XL — около 135 ГБ, оптимальный компромисс для домашнего запуска через выгрузку в ОЗУ (24 ГБ VRAM + 128 ГБ RAM, скорость ~5 токенов/с).
- Q4_K_XL — около 210 ГБ, близко к полному качеству, но требует уже очень много памяти.
Практический выбор для дома: если решились на полную модель через offloading, берите Q2_K_XL — это разумный баланс. Для Flash-версии всё проще: обычный Q4_K_M около 23 ГБ, и никаких ухищрений не нужно. Общее правило с большими MoE: чем агрессивнее квант, тем сильнее падает именно качество рассуждений и кода, поэтому экономить на кванте кодерской модели стоит осторожно.
Многокарточный сервер: vLLM и SGLang
Если GLM нужна не одному человеку, а команде или сервису, домашние бэкенды уступают место серверным движкам — vLLM и SGLang. Они заточены под высокую пропускную способность: обрабатывают много запросов параллельно, эффективно используют несколько видеокарт и дают максимальный tok/s на дорогом железе.
Для полной GLM-4.6/4.7 в формате BF16 нужен серьёзный стенд — порядка 16 карт H100 на 80 ГБ (или 8×H200 на 141 ГБ) при полном контексте. Это уже инфраструктура дата-центра, а не домашняя сборка. Зато на таком железе GLM раскрывается полностью: на специализированных ускорителях (например, Cerebras) скорость достигает сотен токенов в секунду. Для абсолютного большинства читателей это избыточно — но знать про этот путь полезно, если планируете разворачивать GLM как сервис для команды.
Агентный кодинг: GLM Coding Plan как дешёвая альтернатива Claude
Здесь — наш information gain для разработчиков. Помимо локального запуска, у Z.ai есть GLM Coding Plan — подписка, которая позволяет использовать GLM как бекенд в популярных агентных инструментах: Claude Code, Cline, Roo Code. По сути это дешёвая замена дорогим планам Anthropic: тарифы начинаются примерно от 30 долларов в квартал (по данным Z.ai на 2026 год), тогда как сопоставимый доступ к Claude стоит кратно дороже.
Подключение простое: в конфигурации Claude Code или Cline указываете адрес API Z.ai (https://api.z.ai/...) вместо облака Anthropic — и агент начинает работать на GLM. Получается гибрид: вы пользуетесь привычным агентным инструментом, но «движок» под ним — открытая GLM, и платите заметно меньше.
Это удобный компромисс между полностью локальным запуском (приватно, но требует железа) и дорогим облаком: данные всё же уходят на серверы Z.ai, зато не нужно держать GPU, а цена символическая. Для тех, кому важна именно приватность, остаётся локальная Flash-версия; для тех, кому важнее дешёвый мощный кодер, — Coding Plan.
Отдельно стоит упомянуть связку с Cline: совместный тариф Z.ai и Cline сделал доступ к фронтир-кодеру буквально за несколько долларов в месяц, и это всколыхнуло сообщество разработчиков — впервые мощный агентный кодинг стал по карману энтузиасту, а не только компании. Подключается всё через стандартный OpenAI-совместимый интерфейс, так что любой инструмент, умеющий работать с таким API, в принципе можно подружить с GLM.
Сколько это стоит: три пути к GLM
У GLM есть три способа использования, и у каждого своя экономика — полезно сравнить.
- Локально (Flash или offloading). Платите один раз за железо: видеокарта 24 ГБ для Flash или много ОЗУ для большой модели. Дальше — бесплатно и приватно, данные не уходят никуда. Минус — потолок по качеству (Flash) или по скорости (offloading).
- GLM Coding Plan. Подписка от ~30 долларов в квартал даёт мощную GLM как бекенд в Claude Code и Cline. Дёшево относительно Claude, не нужно своё железо, но данные идут на серверы Z.ai.
- API с оплатой по токенам. Для эпизодических задач: GLM-4.7 стоит порядка 0,6 доллара за миллион входных токенов и 2,2 за миллион выходных (по ценам Z.ai на июнь 2026), а Flash в API и вовсе бесплатна. Удобно для интеграции в свои скрипты без подписки.
Как выбрать. Нужна приватность — локальная Flash. Нужен дешёвый мощный кодер каждый день — Coding Plan. Нужны разовые вызовы из кода — API. Многие совмещают: Flash локально для чувствительного кода и Coding Plan для тяжёлых задач.
Reasoning и thinking-режим
Как и другие современные модели, GLM умеет «думать вслух» (chain-of-thought) перед ответом. Режим рассуждений включается параметром в запросе (thinking.type: enabled/disabled): для сложных задач — включаете, для простых и быстрых — выключаете ради скорости.
У свежих версий есть любопытная особенность — Preserved Thinking (сохранённое рассуждение): цепочка мыслей не сбрасывается после каждого ответа, а переносится в следующий ход. В длинных агентных сессиях это помогает модели «помнить» ход своих рассуждений — но включается отдельной настройкой.
И важная практическая грабля: GLM по умолчанию нередко рассуждает на китайском (по наблюдениям пользователей в обсуждениях на Hugging Face и Reddit), даже если вы пишете по-русски или по-английски. На итоговый ответ это влияет не всегда, но если хотите видеть рассуждения на понятном языке, добавьте в системный промпт явную инструкцию вроде «рассуждай и отвечай на русском языке».
Управление «усилием» рассуждений — отдельная сильная сторона свежих версий: можно задавать, насколько глубоко модель думает над задачей, балансируя между скоростью и качеством. Для рутинного автодополнения кода рассуждения лучше держать минимальными или выключать совсем, а для сложной отладки или проектирования архитектуры — включать на полную. Это превращает одну модель в гибкий инструмент под разную сложность задач.
Что нового в GLM-5.2: контекст на миллион токенов
Самое свежее на момент написания — GLM-5.2, вышедшая 13 июня 2026 года. Её главная новость — рабочий контекст на миллион токенов. Это не просто большая цифра: модель действительно способна удержать в «памяти» целый крупный проект — сотни файлов кода или толстую документацию — и рассуждать по нему целиком, не теряя нити. Для агентного кодинга, где важно видеть весь репозиторий, а не отдельный файл, это серьёзный шаг.
Есть нюанс: на момент выпуска Z.ai не опубликовала бенчмарки GLM-5.2, а открытые веса под MIT ожидались примерно к 20 июня 2026 — то есть на момент подготовки этой статьи (16 июня) их ещё не было; актуальный статус проверяйте на странице проекта в Hugging Face. Это типичная для Zhipu схема — сначала доступ через Coding Plan и API, затем выкладка весов. Если планируете локальный запуск новейших версий, проверяйте, появились ли уже открытые веса конкретной модели: разрыв между облачным релизом и публикацией весов может составлять недели. И помните про железо — чем новее и больше модель, тем менее реалистичен её домашний запуск без серьёзных компромиссов.
Бенчмарки: близко к Claude в коде
Сила GLM — программирование и агентные задачи, и цифры это подтверждают. На главном тесте реального кодинга SWE-bench Verified линейка быстро росла: GLM-4.5 показала 64,2% (OpenLM.ai SWE-bench, июль 2025), GLM-4.7 — уже 73,8% (декабрь 2025), а GLM-5.1 — 74,4% (OpenLM.ai, апрель 2026, агент mini-SWE-agent). Старшая GLM-5 по независимым обзорам поднимала планку ещё выше — около 77,8%. Это уровень, вплотную приближающийся к закрытым флагманам вроде Claude.
Ещё показательнее результат на τ²-Bench — тесте, который измеряет не правку кода, а вызов инструментов в агентных циклах (то, что реально нужно для автономных агентов). Здесь GLM-4.7 на старте показала около 87,4 балла — рекорд среди открытых моделей на тот момент. Для тех, кто строит агентов, а не просто гоняет чат, это важнее классического SWE-bench.
Стандартная оговорка: бенчмарки отражают узкие задачи, часть цифр — из отдельных обзоров, а не официальных лидербордов (это отмечено в источниках). Рекордные результаты проверяйте на своих задачах, особенно если работаете не на английском.
Для ориентира: по совокупности кодовых и агентных тестов GLM-4.7 и GLM-5.x встают рядом с DeepSeek последних версий и заметно выше, чем универсальные модели вроде Llama, в задачах автономного программирования. От закрытого Claude Sonnet старшие GLM отстают уже немного — и это, пожалуй, главное достижение открытого сегмента к 2026 году: фронтир-кодинг перестал быть монополией закрытых лабораторий.
Что это значит на практике для разработчика: задачи, которые ещё год назад требовали платного облачного агента, сегодня выполняет открытая модель на вашем железе или за символическую подписку. Полностью заменить топовый закрытый ИИ на самых сложных задачах GLM пока не может, но в рутине — рефакторинг, генерация типовых модулей, отладка, работа с инструментами — разрыв почти стёрся. Для команд, которым важны приватность кода или экономия на подписках, это меняет весь расчёт.
Русский и украинский: слабое место
GLM обучена с фокусом на английский и китайский, а поддержка русского и украинского — ограниченная. Это не наше предположение: сама Z.ai в обсуждениях моделей признаёт, что русский «ещё не полностью оптимизирован». На практике GLM поймёт запрос на русском и ответит, но качество текста, нюансы и грамотность будут заметно ниже, чем в английском или у моделей, заточенных под мультиязычность.
Вывод для нашей аудитории: если задача — генерация и редактура русско- или украиноязычного текста, GLM не первый выбор; берите Qwen3, у которого оба языка официально поддержаны. А вот для кода и агентных задач (где общение чаще на английском, а «язык» — это Python или JavaScript) слабость GLM в кириллице почти не мешает — здесь она остаётся сильным инструментом.
GLM против DeepSeek, Qwen3 и GPT-OSS
«Лучшей модели вообще» не существует. Вот сравнение GLM с тремя соперниками в открытом сегменте (по состоянию на июнь 2026).Критерий GLM DeepSeek Qwen3 GPT-OSS Агентный кодинг Очень сильный Сильный Сильный Сильный Русский/украинский Слабо Средне Лучший Неясно Размер (для дома) Flash 30B / гигант 355B Дистилляты / 671B 8–32B 20B / 120B Лицензия MIT MIT Apache 2.0 Apache 2.0 Контекст до 1M (5.2) 128K 128K 128K Готовность к дому Только Flash Дистилляты Отличная 20B легко
Где GLM объективно впереди: агентный кодинг и вызов инструментов, свежий контекст до миллиона токенов и MIT-лицензия. Где стоит выбрать иначе: для русского сильнее Qwen3, а для лёгкого домашнего запуска без компромиссов — Qwen3 или GPT-OSS-20B заметно дружелюбнее к железу, чем гигантские старшие GLM.
Риски и грабли
- Очень требовательна к железу. Полные GLM (355 млрд и больше) — серверная история; дома реальна только Flash или медленный запуск через выгрузку в ОЗУ. Не рассчитывайте поднять старшую версию «в лоб» на игровой видеокарте.
- Забытый
--jinjaломает агента. Самая частая ошибка при ручном запуске в llama.cpp: без этого флага не работают вызовы инструментов и рассуждения. - Рассуждения на китайском. По умолчанию модель может «думать» на китайском — задавайте язык явно через системный промпт.
- Слабый русский и украинский. Официально не оптимизирована под наши языки — для текста берите конкурентов.
- Китайская цензура. Как у других моделей, обученных в Китае, возможны отказы и искажения на политически чувствительных темах — типичный для сегмента риск, учитывайте для соответствующих задач.
- Темп обновлений. Версии сменяются так быстро, что готовые гайды и кванты устаревают за месяцы; перед запуском проверяйте, какая версия актуальна и есть ли у неё открытые веса.
- Перегрев при долгих сессиях. Тяжёлые модели и агентные циклы надолго нагружают и видеокарту, и оперативную память — следите за температурами и стабильностью, особенно на компактных сборках и при запуске через выгрузку в ОЗУ.
FAQ
Можно ли запустить полную GLM-4.6 на домашнем компьютере? Без компромиссов — нет: это MoE-модель на 355 млрд параметров, её веса даже в сжатом виде занимают сотни гигабайт и требуют серверного железа. Дома её можно поднять только через выгрузку «экспертов» в оперативную память (нужно 24 ГБ видеопамяти плюс от 128 ГБ ОЗУ) и со скоростью около 5 токенов/с. Для нормальной работы дома берите GLM-4.7-Flash.
Что такое GLM Coding Plan и чем он отличается от локального запуска? Это облачная подписка Z.ai (от ~30 долларов в квартал), которая даёт мощную GLM как движок для агентных инструментов вроде Claude Code и Cline. В отличие от локального запуска, своё железо не нужно, но данные уходят на серверы Z.ai. Это компромисс: дешевле и проще, чем держать GPU, но без полной приватности локального варианта.
Что такое GLM-4.7-Flash и чем она отличается от обычной GLM? Flash — компактная версия (около 30 млрд параметров против 355 у старших), специально для скромного железа. Она запускается на одной видеокарте 24 ГБ (RTX 3090/4090) и сохраняет сильную сторону GLM — агентный кодинг, — но уступает гигантским версиям в самых сложных задачах. Для домашнего запуска это основной вариант.
GLM Coding Plan — это локальный запуск? Нет, это облачная подписка Z.ai, которая позволяет использовать GLM как движок в агентных инструментах (Claude Code, Cline) дешевле, чем Claude. Данные при этом уходят на серверы Z.ai. Если нужна именно приватность, используйте локальную Flash-версию; Coding Plan — это про дешёвый мощный кодер без своего GPU.
Хорош ли GLM для русского языка? Слабо. Z.ai официально признаёт, что русский «ещё не полностью оптимизирован» — модель заточена под английский и китайский. Запрос она поймёт, но качество текста на русском и украинском будет ниже, чем у Qwen3 или Gemma. Для кода это почти не мешает, для текстов — берите конкурентов.
Почему при запуске в llama.cpp GLM ведёт себя странно?
Скорее всего, забыт флаг --jinja. Он обязателен для GLM: без него ломаются вызовы инструментов и режим рассуждений. Добавьте --jinja в команду запуска — это решает большинство «странностей» с агентным поведением модели.
Стоит ли ждать открытых весов новых версий GLM-5? Если вам нужен максимум качества и вы готовы к серверному железу — да, старшие версии сильнее. Но для домашнего запуска размер GLM-5 (сотни миллиардов параметров) — проблема: даже с выгрузкой в ОЗУ это медленно. Практичнее следить за выходом компактных Flash-версий нового поколения, чем гнаться за гигантскими весами, которые всё равно не запустить дома без серьёзных компромиссов.
GLM или DeepSeek для локального кодинга — что выбрать? Обе сильны в коде и под лицензией MIT. GLM чуть впереди в агентных задачах и вызове инструментов, у DeepSeek — удобные дистилляты, которые легко запустить на скромной карте. Если у вас 24 ГБ видеопамяти и нужен агент — пробуйте GLM-4.7-Flash; если железо совсем скромное — дистиллят DeepSeek будет дружелюбнее.










