


Коротко (TL;DR)
GLM — лінійка відкритих моделей китайської лабораторії Zhipu AI (бренд Z.ai), і до 2026 року це один із найсильніших відкритих проєктів для кодингу й агентних задач. За якістю програмування GLM підбирається до закритих моделей рівня Claude, за вільної ліцензії MIT. Але з локальним запуском усе непросто, і далі розберемо, що реально підняти вдома, а що ні.
- Коротко (TL;DR)
- Що таке GLM і чому за ним складно угнатися
- Архітектура MoE: чому 355 млрд не значить 355 млрд обчислень
- Чи можна запустити GLM удома: розбір за варіантами
- GLM-4.7-Flash: реальний домашній варіант
- Запуск великої моделі: MoE-offloading та обов’язковий –jinja
- Кванти GGUF: що качати для GLM
- Багатокартковий сервер: vLLM і SGLang
- Агентний кодинг: GLM Coding Plan як дешева альтернатива Claude
- Скільки це коштує: три шляхи до GLM
- Reasoning і thinking-режим
- Що нового в GLM-5.2: контекст на мільйон токенів
- Бенчмарки: близько до Claude в коді
- Українська і російська: слабке місце
- GLM проти DeepSeek, Qwen3 і GPT-OSS
- Ризики й граблі
- FAQ
- Шалений темп. За рік вийшло ціле покоління: GLM-4.5 (липень 2025) → 4.6 → 4.7 → GLM-5 → GLM-5.2 з контекстом на мільйон токенів (червень 2026). Угнатися за оновленнями складно навіть фахівцям.
- Повна модель — не для дому. Старші GLM — це MoE-гіганти на 355 млрд параметрів і більше; щоб запустити їх без компромісів, потрібен сервер із кількома картами H100. На звичайному ПК повну версію «в лоб» не підняти.
- Але вдома дещо реально. Для домашнього заліза є компактна GLM-4.7-Flash (близько 30 млрд параметрів), яка заходить на одну RTX 3090/4090, а велику модель можна запустити через хитрий прийом із вивантаженням в оперативну пам’ять — повільно, але працює.
Висновок для нашої аудиторії: GLM — вибір для розробників, яким потрібен потужний агентний кодер, і хто готовий або до серйозного заліза, або до компромісів за швидкістю. Українська і російська — слабке місце (це визнає й сама Z.ai). Дані актуальні на 16 червня 2026 року.
Що таке GLM і чому за ним складно угнатися
GLM (General Language Model) — сімейство моделей лабораторії Zhipu AI, одного з провідних китайських ШІ-розробників, що виступає під брендом Z.ai. Головний фокус лінійки — програмування й агентні задачі: GLM добре пише код, викликає інструменти й працює в режимі автономного агента.
Відрізняє GLM неймовірний темп випуску. Ось хронологія менш ніж за рік:

- GLM-4.5 (липень 2025) — 355 млрд параметрів, заявка на найкращий відкритий кодер.
- GLM-4.6 (вересень 2025) — зростання якості, контекст до 200K токенів.
- GLM-4.7 (грудень 2025) — 358 млрд (32 млрд активних), рекордні результати в агентних тестах.
- GLM-4.7-Flash (січень 2026) — компактна версія (30 млрд параметрів, контекст 131K) для скромного заліза.
- GLM-5 / 5.1 / 5.2 (2026) — нове покоління; версія 5.2 (13 червня 2026) принесла робочий контекст на 1 млн токенів.
Уся лінійка виходить під ліцензією MIT — однією з найвільніших: модель можна використовувати комерційно, модифікувати й вбудовувати без обмежень. Для бізнесу це великий плюс. Мінус інший — за таким темпом складно угнатися, і до моменту, коли ви освоїте одну версію, виходить наступна.

Для користувача в цього є і плюс, і мінус. Плюс — ви отримуєте дуже свіжу технологію: відкриті моделі GLM регулярно опиняються серед найсильніших у світі на момент виходу. Мінус — екосистема не встигає: готові кванти, гайди та інтеграції відстають від релізів, і іноді найновішу версію простіше спробувати через хмару Z.ai, ніж чекати, поки її зручно загорнуть для локального запуску.
Архітектура MoE: чому 355 млрд не значить 355 млрд обчислень
GLM побудована на архітектурі «суміші експертів» (MoE), і це важливо для розуміння вимог до заліза. У GLM-4.6, наприклад, 355 млрд параметрів усього, але лише близько 32 млрд активні на кожен токен. Тобто модель «думає» зі швидкістю 32-мільярдної, хоча зберігає знання 355-мільярдної.
Звучить так, ніби й пам’яті потрібно під 32 млрд — але ні. У пам’ять доводиться завантажувати всі 355 млрд ваг, бо заздалегідь невідомо, який «експерт» знадобиться на наступному кроці. MoE економить швидкість обчислень, а не обсяг пам’яті. Саме тому навіть стиснута GLM-4.6 не вміщується на домашню відеокарту: її ваги в пристойному кванті займають сотні гігабайтів.
У компактної GLM-4.7-Flash параметрів куди менше — близько 30 млрд усього і 3,6 млрд активних, і ось вона вже реалістична для дому. А в нового покоління GLM-5 розміри знову виросли (старша версія — порядку 745 млрд, з них 44 млрд активних). Запам’ятайте правило: для домашнього запуску дивіться на розмір моделі цілком, а «активні параметри» — це про швидкість, не про пам’ять. У цього підходу є й приємний бік: за тієї самої швидкості MoE-модель «знає» більше, ніж щільна того самого бистродіяння, бо зберігає знання всіх експертів. Саме тому GLM за своїх 32 активних мільярдів конкурує за якістю з куди важчими щільними моделями — але платить за це вимогами до пам’яті.
Чи можна запустити GLM удома: розбір за варіантами
Головне питання — що реально з лінійки GLM піднімається на домашньому залізі. Розберемо за варіантами.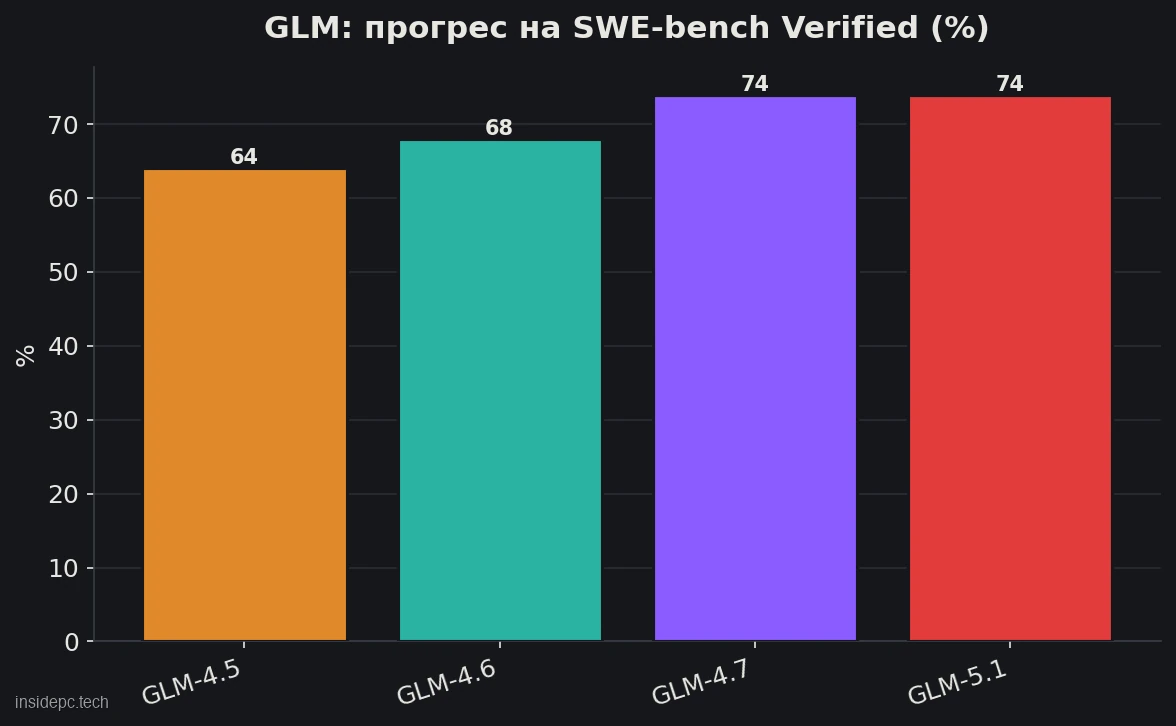
Варіант Що потрібно Реалістично вдома? GLM-4.7-Flash (30B) RTX 3090/4090 (24 ГБ), Q4 Так — основний домашній шлях GLM-4.5-Air (106B) ~64–128 ГБ unified memory (Mac) або мультикарта З застереженнями Повна GLM-4.6/4.7 (355B+) через offloading 24 ГБ VRAM + 128 ГБ ОЗП, низька швидкість Технічно так, ~5 tok/s Повна GLM у BF16 Сервер 16×H100 Ні, тільки дата-центр
Висновок простий: для більшості домашніх користувачів реальний шлях — GLM-4.7-Flash. Вона запускається на одній топовій відеокарті й дає більшу частину користі старших версій в агентному кодингу. Якщо ж хочеться саме повну модель і є багато оперативної пам’яті — її можна підняти через вивантаження в ОЗП (про це нижче), але готуйтеся до швидкості в одиниці токенів за секунду. Повноцінно велику GLM тягне тільки серверне залізо.

Окремий домашній шлях до середніх версій — техніка Apple з великою єдиною пам’яттю: Mac Studio зі 128–512 ГБ unified memory здатний підняти GLM-4.5-Air і навіть підступитися до великих версій, чого не зробити на звичайній відеокарті. Це недешево, але тихіше й компактніше, ніж багатокартковий сервер, — і для тих, хто вже в екосистемі Apple, часто найпростіший шлях до великих локальних моделей.
Якщо придивляєтеся до платформи з великим обсягом єдиної пам’яті під такі моделі, зазирніть у наші огляди збірок для локального ШІ.
GLM-4.7-Flash: реальний домашній варіант
Flash — це та версія GLM, заради якої варто читати далі, якщо у вас звичайний потужний ПК. За розміру близько 30 млрд параметрів вона в кванті Q4_K_M займає порядку 23 ГБ і заходить на відеокарту 24 ГБ (RTX 3090, 4090). За замірами спільноти швидкість декодування на RTX 3090 — близько 93 токенів/с при короткому контексті (4K) і порядку 43 токенів/с при 32K (квант Q4_K_M), що для агентної роботи більш ніж достатньо.
Запуск найпростіше через Ollama або LM Studio — вони самі розбираються з форматом промптів. В Ollama це одна команда (звіряйтеся з актуальним каталогом — модель свіжа):
ollama run glm-4.7-flash
Flash хороша тим, що за скромних вимог зберігає фірмову сильну сторону GLM — агентний кодинг і роботу з інструментами. Для локального помічника розробника на одній карті це зараз один із найкращих відкритих варіантів; повноцінні старші версії додадуть якості, але потребують незрівнянно більше заліза.
Запуск великої моделі: MoE-offloading та обов’язковий –jinja
Якщо ви все-таки хочете запустити повну GLM-4.6/4.7 на домашньому залізі, є прийом, який змінює правила гри, — вивантаження MoE-експертів в оперативну пам’ять. Ідея в тому, щоб тримати на відеокарті лише «легкі» частини моделі (увагу, ембеддинги), а важких «експертів» лишити у звичайній ОЗП. У llama.cpp це робиться прапором:
llama-server -m glm-4.6-Q2_K_XL.gguf -ot ".ffn_.*_exps.=CPU" --jinja
Тоді замість сотень гігабайтів відеопам’яті достатньо 24 ГБ VRAM плюс багато (від 128 ГБ) системної ОЗП. Платою стає швидкість — близько 5 токенів за секунду на важкій моделі, але сам факт, що фронтир-модель працює на домашньому ПК, дорого вартий.
І окреме попередження, на якому спотикаються майже всі: прапор --jinja обов’язковий. Без нього ламаються виклики інструментів і режим міркувань — модель поводитиметься дивно або зовсім не працюватиме в агентному режимі. Це найчастіша «невидима» помилка при ручному запуску GLM; якщо щось пішло не так — насамперед перевірте, що --jinja на місці.
Кванти GGUF: що качати для GLM
Для запуску GLM у llama.cpp потрібен файл GGUF у відповідному кванті — і тут у великих моделей свої крайнощі. Команда Unsloth викладає «динамічні» кванти GLM-4.6 з дуже широким розкидом за розміром:
- TQ1_0 — екстремальне стиснення, близько 84 ГБ. Влазить на скромне за мірками гігантів залізо, але якість помітно падає.
- Q2_K_XL — близько 135 ГБ, оптимальний компроміс для домашнього запуску через вивантаження в ОЗП (24 ГБ VRAM + 128 ГБ RAM, швидкість ~5 токенів/с).
- Q4_K_XL — близько 210 ГБ, близько до повної якості, але вимагає вже дуже багато пам’яті.
Практичний вибір для дому: якщо зважилися на повну модель через offloading, беріть Q2_K_XL — це розумний баланс. Для Flash-версії все простіше: звичайний Q4_K_M близько 23 ГБ, і жодних хитрощів не потрібно. Загальне правило з великими MoE: що агресивніший квант, то сильніше падає саме якість міркувань і коду, тому економити на кванті кодерської моделі варто обережно.
Багатокартковий сервер: vLLM і SGLang
Якщо GLM потрібна не одній людині, а команді чи сервісу, домашні бекенди поступаються місцем серверним рушіям — vLLM і SGLang. Вони заточені під високу пропускну здатність: обробляють багато запитів паралельно, ефективно використовують кілька відеокарт і дають максимальний tok/s на дорогому залізі.
Для повної GLM-4.6/4.7 у форматі BF16 потрібен серйозний стенд — порядку 16 карт H100 на 80 ГБ (або 8×H200 на 141 ГБ) при повному контексті. Це вже інфраструктура дата-центру, а не домашня збірка. Зате на такому залізі GLM розкривається повністю: на спеціалізованих прискорювачах (наприклад, Cerebras) швидкість сягає сотень токенів за секунду. Для абсолютної більшості читачів це надмірно — але знати про цей шлях корисно, якщо плануєте розгортати GLM як сервіс для команди.
Агентний кодинг: GLM Coding Plan як дешева альтернатива Claude
Тут — наш information gain для розробників. Окрім локального запуску, у Z.ai є GLM Coding Plan — підписка, яка дозволяє використовувати GLM як бекенд у популярних агентних інструментах: Claude Code, Cline, Roo Code. По суті це дешева заміна дорогим планам Anthropic: тарифи починаються приблизно від 30 доларів за квартал (за даними Z.ai на 2026 рік), тоді як співставний доступ до Claude коштує кратно дорожче.
Підключення просте: у конфігурації Claude Code або Cline вказуєте адресу API Z.ai (https://api.z.ai/...) замість хмари Anthropic — і агент починає працювати на GLM. Виходить гібрид: ви користуєтеся звичним агентним інструментом, але «рушій» під ним — відкрита GLM, і платите помітно менше.
Це зручний компроміс між повністю локальним запуском (приватно, але потребує заліза) і дорогою хмарою: дані все ж ідуть на сервери Z.ai, зате не потрібно тримати GPU, а ціна символічна. Для тих, кому важлива саме приватність, лишається локальна Flash-версія; для тих, кому важливіший дешевий потужний кодер, — Coding Plan.
Окремо варто згадати зв’язку з Cline: спільний тариф Z.ai і Cline зробив доступ до фронтир-кодера буквально за кілька доларів на місяць, і це сколихнуло спільноту розробників — уперше потужний агентний кодинг став по кишені ентузіасту, а не лише компанії. Підключається все через стандартний OpenAI-сумісний інтерфейс, тож будь-який інструмент, що вміє працювати з таким API, у принципі можна подружити з GLM.
Скільки це коштує: три шляхи до GLM
У GLM є три способи використання, і в кожного своя економіка — корисно порівняти.
- Локально (Flash або offloading). Платите один раз за залізо: відеокарта 24 ГБ для Flash або багато ОЗП для великої моделі. Далі — безкоштовно і приватно, дані не йдуть нікуди. Мінус — стеля за якістю (Flash) або за швидкістю (offloading).
- GLM Coding Plan. Підписка від ~30 доларів за квартал дає потужну GLM як бекенд у Claude Code і Cline. Дешево відносно Claude, не потрібне своє залізо, але дані йдуть на сервери Z.ai.
- API з оплатою за токени. Для епізодичних задач: GLM-4.7 коштує порядку 0,6 долара за мільйон вхідних токенів і 2,2 за мільйон вихідних (за цінами Z.ai на червень 2026), а Flash в API і зовсім безкоштовна. Зручно для інтеграції у свої скрипти без підписки.
Як обрати. Потрібна приватність — локальна Flash. Потрібен дешевий потужний кодер щодня — Coding Plan. Потрібні разові виклики з коду — API. Багато хто поєднує: Flash локально для чутливого коду і Coding Plan для важких задач.
Reasoning і thinking-режим
Як і інші сучасні моделі, GLM уміє «думати вголос» (chain-of-thought) перед відповіддю. Режим міркувань вмикається параметром у запиті (thinking.type: enabled/disabled): для складних задач — вмикаєте, для простих і швидких — вимикаєте заради швидкості.
У свіжих версій є цікава особливість — Preserved Thinking (збережене міркування): ланцюжок думок не скидається після кожної відповіді, а переноситься в наступний хід. У довгих агентних сесіях це допомагає моделі «пам’ятати» хід своїх міркувань — але вмикається окремим налаштуванням.
І важлива практична грабля: GLM за замовчуванням нерідко міркує китайською (за спостереженнями користувачів в обговореннях на Hugging Face і Reddit), навіть якщо ви пишете українською чи англійською. На підсумкову відповідь це впливає не завжди, але якщо хочете бачити міркування зрозумілою мовою, додайте в системний промпт явну інструкцію на кшталт «міркуй і відповідай українською мовою».
Керування «зусиллям» міркувань — окрема сильна сторона свіжих версій: можна задавати, наскільки глибоко модель думає над задачею, балансуючи між швидкістю і якістю. Для рутинного автодоповнення коду міркування краще тримати мінімальними або вимикати зовсім, а для складного налагодження чи проєктування архітектури — вмикати на повну. Це перетворює одну модель на гнучкий інструмент під різну складність задач.
Що нового в GLM-5.2: контекст на мільйон токенів
Найсвіжіше на момент написання — GLM-5.2, що вийшла 13 червня 2026 року. Її головна новина — робочий контекст на мільйон токенів. Це не просто велика цифра: модель справді здатна втримати в «пам’яті» цілий великий проєкт — сотні файлів коду або товсту документацію — і міркувати по ньому цілком, не втрачаючи нитки. Для агентного кодингу, де важливо бачити весь репозиторій, а не окремий файл, це серйозний крок.
Є нюанс: на момент випуску Z.ai не опублікувала бенчмарки GLM-5.2, а відкриті ваги під MIT очікувалися приблизно до 20 червня 2026 — тобто на момент підготовки цієї статті (16 червня) їх ще не було; актуальний статус перевіряйте на сторінці проєкту в Hugging Face. Це типова для Zhipu схема — спершу доступ через Coding Plan і API, потім викладка ваг. Якщо плануєте локальний запуск найновіших версій, перевіряйте, чи з’явилися вже відкриті ваги конкретної моделі: розрив між хмарним релізом і публікацією ваг може складати тижні. І пам’ятайте про залізо — що новіша й більша модель, то менш реалістичний її домашній запуск без серйозних компромісів.
Бенчмарки: близько до Claude в коді
Сила GLM — програмування й агентні задачі, і цифри це підтверджують. На головному тесті реального кодингу SWE-bench Verified лінійка швидко росла: GLM-4.5 показала 64,2% (OpenLM.ai SWE-bench, липень 2025), GLM-4.7 — уже 73,8% (грудень 2025), а GLM-5.1 — 74,4% (OpenLM.ai, квітень 2026, агент mini-SWE-agent). Старша GLM-5 за незалежними оглядами піднімала планку ще вище — близько 77,8%. Це рівень, що впритул наближається до закритих флагманів на кшталт Claude.
Ще показовіший результат на τ²-Bench — тесті, який вимірює не правку коду, а виклик інструментів в агентних циклах (те, що реально потрібно для автономних агентів). Тут GLM-4.7 на старті показала близько 87,4 бала — рекорд серед відкритих моделей на той момент. Для тих, хто будує агентів, а не просто ганяє чат, це важливіше за класичний SWE-bench.
Стандартне застереження: бенчмарки відображають вузькі задачі, частина цифр — з окремих оглядів, а не офіційних лідербордів (це відзначено в джерелах). Рекордні результати перевіряйте на своїх задачах, особливо якщо працюєте не англійською.
Для орієнтиру: за сукупністю кодових і агентних тестів GLM-4.7 і GLM-5.x встають поряд із DeepSeek останніх версій і помітно вище, ніж універсальні моделі на кшталт Llama, у задачах автономного програмування. Від закритого Claude Sonnet старші GLM відстають уже трохи — і це, мабуть, головне досягнення відкритого сегмента до 2026 року: фронтир-кодинг перестав бути монополією закритих лабораторій.
Що це означає на практиці для розробника: задачі, які ще рік тому вимагали платного хмарного агента, сьогодні виконує відкрита модель на вашому залізі або за символічну підписку. Повністю замінити топовий закритий ШІ на найскладніших задачах GLM поки не може, але в рутині — рефакторинг, генерація типових модулів, налагодження, робота з інструментами — розрив майже стерся. Для команд, яким важливі приватність коду або економія на підписках, це змінює весь розрахунок.
Українська і російська: слабке місце
GLM навчена з фокусом на англійську та китайську, а підтримка української й російської — обмежена. Це не наше припущення: сама Z.ai в обговореннях моделей визнає, що російська «ще не повністю оптимізована». На практиці GLM зрозуміє запит українською і відповість, але якість тексту, нюанси й грамотність будуть помітно нижчими, ніж в англійській або в моделей, заточених під багатомовність.
Висновок для нашої аудиторії: якщо задача — генерація й редактура україно- чи російськомовного тексту, GLM не перший вибір; беріть Qwen3, у якого обидві мови офіційно підтримані. А ось для коду й агентних задач (де спілкування частіше англійською, а «мова» — це Python чи JavaScript) слабкість GLM у кирилиці майже не заважає — тут вона лишається сильним інструментом.
GLM проти DeepSeek, Qwen3 і GPT-OSS
«Найкращої моделі взагалі» не існує. Ось порівняння GLM із трьома суперниками у відкритому сегменті (станом на червень 2026).Критерій GLM DeepSeek Qwen3 GPT-OSS Агентний кодинг Дуже сильний Сильний Сильний Сильний Українська/російська Слабко Середньо Найкращий Неясно Розмір (для дому) Flash 30B / гігант 355B Дистиляти / 671B 8–32B 20B / 120B Ліцензія MIT MIT Apache 2.0 Apache 2.0 Контекст до 1M (5.2) 128K 128K 128K Готовність до дому Тільки Flash Дистиляти Відмінна 20B легко
Де GLM об’єктивно попереду: агентний кодинг і виклик інструментів, свіжий контекст до мільйона токенів і MIT-ліцензія. Де варто обрати інакше: для української сильніший Qwen3, а для легкого домашнього запуску без компромісів — Qwen3 або GPT-OSS-20B помітно дружелюбніші до заліза, ніж гігантські старші GLM.
Ризики й граблі
- Дуже вимоглива до заліза. Повні GLM (355 млрд і більше) — серверна історія; вдома реальна тільки Flash або повільний запуск через вивантаження в ОЗП. Не розраховуйте підняти старшу версію «в лоб» на ігровій відеокарті.
- Забутий
--jinjaламає агента. Найчастіша помилка при ручному запуску в llama.cpp: без цього прапора не працюють виклики інструментів і міркування. - Міркування китайською. За замовчуванням модель може «думати» китайською — задавайте мову явно через системний промпт.
- Слабка українська і російська. Офіційно не оптимізована під наші мови — для тексту беріть конкурентів.
- Китайська цензура. Як і в інших моделей, навчених у Китаї, можливі відмови й спотворення на політично чутливих темах — типовий для сегмента ризик, враховуйте для відповідних задач.
- Темп оновлень. Версії змінюються так швидко, що готові гайди й кванти застарівають за місяці; перед запуском перевіряйте, яка версія актуальна і чи є в неї відкриті ваги.
- Перегрів за довгих сесій. Важкі моделі й агентні цикли надовго навантажують і відеокарту, і оперативну пам’ять — стежте за температурами й стабільністю, особливо на компактних збірках і при запуску через вивантаження в ОЗП.
FAQ
Чи можна запустити повну GLM-4.6 на домашньому комп’ютері? Без компромісів — ні: це MoE-модель на 355 млрд параметрів, її ваги навіть у стиснутому вигляді займають сотні гігабайтів і вимагають серверного заліза. Вдома її можна підняти тільки через вивантаження «експертів» в оперативну пам’ять (потрібно 24 ГБ відеопам’яті плюс від 128 ГБ ОЗП) і зі швидкістю близько 5 токенів/с. Для нормальної роботи вдома беріть GLM-4.7-Flash.
Що таке GLM Coding Plan і чим він відрізняється від локального запуску? Це хмарна підписка Z.ai (від ~30 доларів за квартал), яка дає потужну GLM як рушій для агентних інструментів на кшталт Claude Code і Cline. На відміну від локального запуску, своє залізо не потрібне, але дані йдуть на сервери Z.ai. Це компроміс: дешевше і простіше, ніж тримати GPU, але без повної приватності локального варіанта.
Що таке GLM-4.7-Flash і чим вона відрізняється від звичайної GLM? Flash — компактна версія (близько 30 млрд параметрів проти 355 у старших), спеціально для скромного заліза. Вона запускається на одній відеокарті 24 ГБ (RTX 3090/4090) і зберігає сильну сторону GLM — агентний кодинг, — але поступається гігантським версіям у найскладніших задачах. Для домашнього запуску це основний варіант.
Чи хороший GLM для української мови? Слабко. Z.ai офіційно визнає, що російська «ще не повністю оптимізована» — модель заточена під англійську й китайську. Запит вона зрозуміє, але якість тексту українською й російською буде нижчою, ніж у Qwen3 чи Gemma. Для коду це майже не заважає, для текстів — беріть конкурентів.
Чому при запуску в llama.cpp GLM поводиться дивно?
Найімовірніше, забуто прапор --jinja. Він обов’язковий для GLM: без нього ламаються виклики інструментів і режим міркувань. Додайте --jinja в команду запуску — це розв’язує більшість «дивацтв» з агентною поведінкою моделі.
Чи варто чекати відкритих ваг нових версій GLM-5? Якщо вам потрібен максимум якості і ви готові до серверного заліза — так, старші версії сильніші. Але для домашнього запуску розмір GLM-5 (сотні мільярдів параметрів) — проблема: навіть із вивантаженням в ОЗП це повільно. Практичніше стежити за виходом компактних Flash-версій нового покоління, ніж гнатися за гігантськими вагами, які все одно не запустити вдома без серйозних компромісів.
GLM чи DeepSeek для локального кодингу — що обрати? Обидві сильні в коді й під ліцензією MIT. GLM трохи попереду в агентних задачах і виклику інструментів, у DeepSeek — зручні дистиляти, які легко запустити на скромній карті. Якщо у вас 24 ГБ відеопам’яті і потрібен агент — пробуйте GLM-4.7-Flash; якщо залізо зовсім скромне — дистилят DeepSeek буде дружелюбнішим.









