



Коротко (TL;DR)
Mac Studio с чипом M3 Ultra — это король памяти и пропускной способности среди компактных машин для локального ИИ. До 512 ГБ единой памяти и 819 ГБ/с делают его единственным потребительским десктопом, который держит frontier-модель целиком: полный DeepSeek R1 на 671 млрд параметров (в 4-битном кванте, ~350–400 ГБ) грузится и идёт примерно 16–20 токенов/с. Ни одна потребительская видеокарта, ни DGX Spark, ни мини-ПК на Strix Halo так не умеют.
Пропускная способность 819 ГБ/с — это втрое больше, чем у DGX Spark (273) и Strix Halo (256), поэтому на моделях, которые уже влезли, Mac генерирует заметно быстрее: на gpt-oss-120B — около 60–71 ток/с против ~38 у DGX Spark.
Но «512 ГБ» — обманчивый аргумент. У M3 Ultra три честных слабых места: медленный prefill (обработка длинного промпта — на контексте 40–50k он становится почти в 10 раз медленнее), обрыв на параллельных запросах (−70% при многопользовательской или агентной нагрузке) и стена CUDA (тюнинг и продакшн-сервинг почти безальтернативно идут на NVIDIA). Цена топ-конфигурации тоже кусается: от $3 999 за базу до ~$9 499 за 512 ГБ и до $14 099 за максимум. Ниже — что именно он тянет с цифрами и кому реально подходит.
(Данные актуальны на 15 июня 2026; цены и бенчмарки — с датами в тексте.)

Задача и бюджет
Mac Studio M3 Ultra — готовое устройство под локальный инференс открытых LLM одним пользователем: приватный чат-ассистент, кодовый помощник, эксперименты с очень большими открытыми моделями. Его сильная сторона — ёмкость и скорость генерации в тихом компактном корпусе; не его цель — продакшн-сервинг на много пользователей, дообучение моделей и максимальный prompt-throughput (для этого нужен NVIDIA).

Бюджет — это цена одного устройства. База M3 Ultra Mac Studio (96 ГБ) — $3 999; конфигурация с 512 ГБ, которая и нужна для самых больших моделей, — около $9 499; полностью укомплектованный (512 ГБ + 16 ТБ) доходит до $14 099 (по данным на июнь 2026). Память распаяна в чип — выбирать объём нужно сразу при покупке, нарастить потом нельзя.
Если 512 ГБ избыточны, а frontier-модели не нужны, разумная альтернатива внутри линейки — Mac Studio M4 Max (до 128 ГБ, 546 ГБ/с, от ~$3 699): пропускная способность вдвое ниже, чем у M3 Ultra, зато и цена заметно ниже, а для моделей до 70B в Q4 этого достаточно. Учтите нюанс биннинга: базовая версия M4 Max с 32-ядерным GPU теряет ещё около 25% пропускной способности — под локальный ИИ берите старший, 40-ядерный.
Оговорка по ожиданиям: локально вы запускаете открытые модели (Llama, Qwen, DeepSeek, gpt-oss), а не облачные Gemini или Claude. Зато — без облака, без оплаты за токены и без утечки данных.
Что такое M3 Ultra и при чём тут 819 ГБ/с
M3 Ultra — старший чип Apple: до 32-ядерного CPU, до 80-ядерного GPU, 32-ядерный Neural Engine и, главное, единая память до 512 ГБ с пропускной способностью 819 ГБ/с, общая для CPU и GPU. На июнь 2026 это самый высокопропускной десктопный чип Apple — M4 Ultra не существует, так что M3 Ultra остаётся вершиной линейки.
Почему пропускная способность важнее ёмкости. Инференс LLM на каждом шаге стримит веса модели из памяти, поэтому скорость генерации определяется не объёмом памяти, а её пропускной способностью. Рабочая формула: токенов/с ≈ пропускная способность ÷ размер модели, с поправкой на реальную эффективность ~65%. Память — это парковка (сколько модель влезет), а пропускная способность — число полос на шоссе (как быстро бегут токены). То, что инференс упирается именно в bandwidth, подтверждено и академически (статья «LLM Inference Unveiled», arXiv 2402.16363).
Отсюда роль M3 Ultra: его 512 ГБ позволяют загрузить то, что не загрузит никто, а 819 ГБ/с — отдавать токены втрое быстрее боксов с 256–273 ГБ/с. Но как только модель влезла в 32 ГБ видеокарты, дискретный GPU с его 1 792 ГБ/с обгоняет Mac в разы. Это и есть главный компромисс.
Что реально потянет
Ниже — скорость генерации (decode) на M3 Ultra по моделям в кванте Q4. Цифры — расчёт по формуле «пропускная способность ÷ размер × 65%» (методология BIZON, май 2026), сверенный с реальными замерами (Alex Ziskind, Dave2D).Модель Параметры / тип Размер Q4 Decode, ток/с Llama 3.1 8B 8B плотная ~4,9 ГБ ~109 Gemma 3 27B 27B плотная ~16,5 ГБ ~32–41 Qwen3 30B-A3B 30B MoE ~18,6 ГБ ~29 Llama 3.3 70B 70B плотная ~42,5 ГБ ~13 gpt-oss-120B 120B MoE ~60 ГБ ~60–71 Qwen3 235B-A22B 235B MoE ~142 ГБ ~4 Llama 3.1 405B 405B плотная ~245 ГБ ~2 DeepSeek R1 671B 671B MoE ~350–400 ГБ ~16–20
Два вывода. Первый: компактные и MoE-модели бегут отлично (8B — больше сотни ток/с, 27–30B — комфортные 30–40), плотная 70B — терпимые ~13 ток/с. Второй и главный: только M3 Ultra с 512 ГБ запускает frontier-модели. DeepSeek R1 671B (это MoE, поэтому активируется лишь часть весов — отсюда ~16–20 ток/с, а не «медленнее 405B») реально работает на максимально укомплектованном Mac. Dave2D намерил на нём 16,08 ток/с в Q4; на Hacker News сообщают про ~20 ток/с на 512-ГБ конфигурации.
Важная оговорка «влезает ≠ удобно». В hands-on тесте MacStories (май 2026) полный DeepSeek R1 685B в 4-битном кванте загрузился, но большое контекстное окно не поместилось: 163 840 токенов не вышло вовсе, 32k загрузилось с 363 ГБ занятой памяти и вылетало при первом же запросе, рабочим оказалось скромное окно ~8 192 токена. То есть запустить frontier-модель можно, но с тесным контекстом.
Сколько стоит и что с доступностью
Ценовая лестница M3 Ultra Mac Studio (на июнь 2026): база 96 ГБ — $3 999, конфигурация с 512 ГБ — около $9 499, полный максимум (512 ГБ + 16 ТБ) — $14 099. Для локального ИИ объём памяти — единственное, на чём нельзя экономить: именно он определяет, какие модели вы вообще загрузите.
Отдельно стоит знать про рынок. Дефицит памяти разогрел и вторичку: по сводке из Кореи (X, 8 мая 2026) б/у M3 Ultra на 512 ГБ ушёл с ~$11k до $15,7k (+43%), а версия на 256 ГБ — с $6,2k до $11k (+77%). Любопытно, что DGX Spark за тот же период на вторичке, наоборот, подешевел (−22%): рынок локального ИИ голосует за пропускную способность. В сообществе встречается мнение, что Mac Studio сворачивают перед обновлением линейки — это заявление сообщества, а не официальные данные, но доступность топовых конфигураций сейчас напряжённая.
M3 Ultra против альтернатив
Сравним по той же модели (gpt-oss-120B, decode) и ключевым параметрам (данные на апрель 2026).Решение Память / ПС Цена 120B decode, ток/с Что уникального Mac Studio M3 Ultra до 512 ГБ / 819 ГБ/с $3 999–9 499+ ~70 держит 671B целиком NVIDIA DGX Spark 128 ГБ / 273 ГБ/с $4 699 ~38 стек CUDA/датацентр Strix Halo (Framework) 128 ГБ / 256 ГБ/с $2 348 ~34 дешевле всех на 128 ГБ Сборка на RTX 5090 32 ГБ / 1 792 ГБ/с ~$2 500+ (карта) не влезает в 32 ГБ максимум скорости ≤32 ГБ 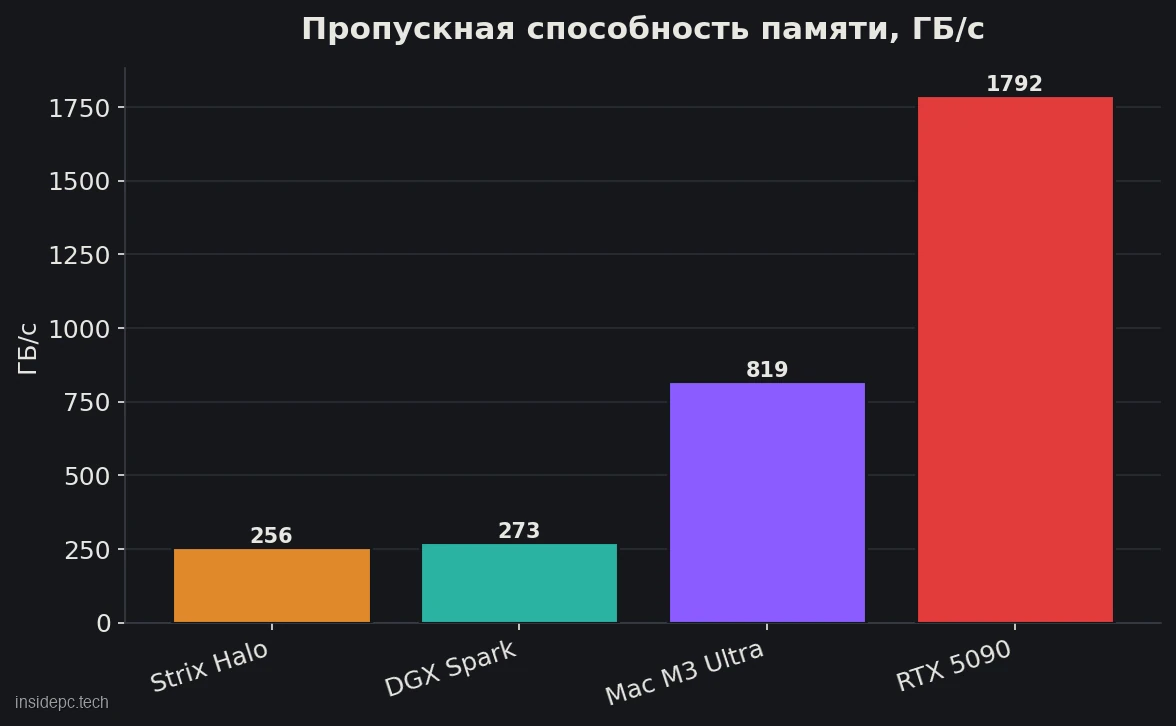
Картина честная:
- Против DGX Spark и Strix Halo. Mac быстрее на токенах: пропускная способность 819 ГБ/с против 256–273 у боксов — втрое выше, и на gpt-oss-120B это ~70 ток/с против ~38 у DGX Spark (почти вдвое на этой модели). Плюс держит вдвое-вчетверо больше памяти. Но есть зеркальный нюанс: DGX Spark силён в prefill (обработке промпта), а Mac — в decode (генерации). Поэтому энтузиасты объединяют их через EXO: DGX Spark читает промпт, Mac генерирует ответ — гибрид даёт до 2,8× ускорения. Подробный разбор DGX Spark — в нашем обзоре NVIDIA DGX Spark, а Strix Halo — в обзоре Ryzen AI Max+ 395.
- Против видеокарты. RTX 5090 с 1 792 ГБ/с (вдвое выше, чем у M3 Ultra) генерирует примерно вдвое быстрее Mac — но на моделях, которые влезают в её 32 ГБ. 70B Q4 в неё уже не помещается, а 671B — тем более. Mac выигрывает ровно там, где ёмкость важнее скорости: загрузить модель, которую дискретный GPU не загрузит в принципе.
Короткий итог: Mac Studio — лучший выбор, когда узкое место — поместить модель целиком; видеокарта — когда модель уже влезла и нужна максимальная скорость.
Софт, настройка и масштабирование
Экосистема Apple для локального ИИ за 2025–2026 заметно подтянулась. Базовый набор: MLX (фреймворк Apple под Apple Silicon), LM Studio (со встроенным MLX-интерпретатором — самый простой путь), Ollama и llama.cpp на Metal. Для одиночного чат-инференса на готовых моделях это зрелый и комфортный стек.
Дальше — два сценария роста. Первый — кластер: несколько Mac Studio соединяют по Thunderbolt 5 и через EXO распределяют одну модель на несколько машин (полезно для моделей крупнее, чем держит один бокс). Второй, упомянутый выше, — гибрид с DGX Spark, закрывающий слабый prefill Mac сильным prefill NVIDIA.
Чего на Mac делать не стоит: рассчитывать на продакшн-сервинг под нагрузкой и на дообучение. vLLM и TensorRT-LLM — CUDA-first (порт под Metal появился в начале 2026, но сырой и только для текста), а инструменты тюнинга (LoRA, QLoRA, DeepSpeed, FSDP) — почти полностью CUDA-нативные. Пошаговый разбор локального инференса (Ollama, кванты, бэкенды) — в нашем разделе локальные нейросети.
Риски и слабые места
Честный список того, о чём молчат соло-демки на YouTube (с датами):
- Медленный prefill и длинный контекст. Apple Silicon силён в генерации, но слаб в обработке промпта (упор в compute, а не в память). На контексте 40–50k токенов модель становится почти в 10 раз медленнее, чем без контекста (Billy Newport, 2025; практики на Threads, 2026). Для тяжёлого RAG и длинных агентных промптов это ощутимо.
- Обрыв на параллельных запросах. Второй пользователь или агент роняет пропускную способность M3 Ultra на ~70% (с ~84 до ~25 ток/с), тогда как NVIDIA на vLLM теряет ~48% (бенчмарки Olares, ноябрь 2025). Единая шина памяти общая для CPU, GPU и всех процессов — агентный стек на 5–10 параллельных запросов насыщает её в одиночку.
- Стена CUDA. Тюнинг и продакшн-сервинг идут на NVIDIA; Metal/MLX хороши для одиночного чата, но не для этих задач (BIZON, май 2026).
- Цена и перегретая вторичка. 512 ГБ ~$9 499, максимум $14 099; на б/у топовые конфиги взлетели на 43–77% из-за дефицита памяти (Корея, май 2026).
- «Влезает ≠ удобно». Даже на 512 ГБ большое контекстное окно frontier-модели не помещается: 685B грузится, но рабочий контекст — около 8k токенов, не 163k (MacStories, 2025).
Справедливости ради — плюсы весомы: это единственный десктоп, держащий 671B/405B целиком; самый быстрый на токенах среди unified-memory машин (3× ПС DGX Spark/Strix Halo); тихий компактный корпус без GPU-вентиляторов и с минимальным энергопотреблением (против ~1 050 Вт у сборки из трёх RTX 3090); зрелый MLX-стек для одиночного инференса.
Кому подходит, а кому нет
- Берите Mac Studio M3 Ultra, если вы один пользователь, которому нужно запускать очень большие открытые модели (235B–671B) дома, важны тишина, компактность и приватность, а тяжёлый длинный контекст и дообучение не в приоритете.
- Берите DGX Spark, если нужен паритет со стеком NVIDIA/CUDA и перенос наработок в дата-центр, и вы готовы к более медленной генерации.
- Берите Strix Halo (Ryzen AI Max+ 395), если хватает 128 ГБ и важна минимальная цена за гигабайт.
- Соберите систему на видеокартах, если ваши модели влезают в 24–48 ГБ и нужны максимальная скорость, multi-user и дообучение.
FAQ
Какие модели реально запустит Mac Studio M3 Ultra? В 512 ГБ единой памяти влезает практически любая открытая модель, включая DeepSeek R1 671B (MoE) — это единственный потребительский десктоп с такой возможностью. Скорость: компактные и MoE-модели идут бодро (8B — ~109 ток/с, gpt-oss-120B — ~60–71), плотная 70B — ~13, а 671B — ~16–20 ток/с. Для удобной работы выбирайте конфигурацию под размер ваших моделей.
Mac Studio M3 Ultra или DGX Spark для локального LLM? Mac быстрее генерирует (819 против 273 ГБ/с — почти вдвое больше токенов/с) и держит больше памяти. DGX Spark берёт стеком CUDA, паритетом с дата-центром и более сильным prefill. Идеально — гибрид: DGX Spark обрабатывает промпт, Mac генерирует ответ (до 2,8× через EXO).
Почему видеокарта быстрее Mac, если у Mac больше памяти? Скорость генерации определяется пропускной способностью памяти, а не её объёмом. У RTX 5090 это 1 792 ГБ/с против 819 у M3 Ultra — отсюда примерно вдвое больше токенов/с. Но видеокарта на 32 ГБ не загрузит 70B и тем более 671B — там, где нужна ёмкость, выигрывает Mac.
Сколько стоит Mac Studio M3 Ultra для ИИ? База 96 ГБ — $3 999, конфигурация с 512 ГБ (для самых больших моделей) — около $9 499, полный максимум с 16 ТБ — $14 099 (июнь 2026). Память распаяна, выбирайте объём сразу. На вторичке топовые конфиги сейчас перегреты дефицитом памяти.
Можно ли на Mac Studio дообучать модели и держать многопользовательский сервис? Это слабые места платформы. Дообучение (LoRA/QLoRA) и продакшн-сервинг (vLLM/TensorRT-LLM) — CUDA-first, на Mac они либо невозможны, либо сырые. При втором-восьмом пользователе скорость падает на ~70%. Для таких задач берут NVIDIA; Mac — для одиночного инференса.
Как собрать конфигурацию под свою модель и бюджет — в гиде по железу для локального ИИ.











