
Коротко (TL;DR)
Mistral Small — лінійка відкритих моделей від французької Mistral AI, єдиного європейського розробника ШІ світового рівня. У неї репутація «найефективнішої моделі у своєму класі» й сильний бік, який цінують розробники: нативна робота з функціями та інструментами. Але у 2026 році важливо не заплутатися, бо під одним іменем ховаються дві дуже різні моделі.
- Коротко (TL;DR)
- Два Mistral Small: домашній 3.x і серверний 4
- Скільки потрібно заліза: VRAM, кванти і швидкість
- Mistral Small 4: MoE-парадокс і reasoning_effort
- Сильний бік: функції та агенти
- Запуск: Ollama, LM Studio, llama.cpp
- Налаштування під себе: контекст, функції та API
- EU-кут: французька модель і приватність
- Українська і російська: чесна оцінка
- Бенчмарки: де стоїть Mistral Small
- Mistral проти Qwen3, Gemma і Llama
- Коли брати Mistral Small, а коли альтернативу
- Ризики й граблі
- FAQ
- Для дому — Mistral Small 3.x (24 млрд параметрів). Вміщується на одну відеокарту 24 ГБ, швидка, мультимодальна (бачить зображення). Це та модель, яку реально запускають на домашньому ПК.
- Для сервера — Mistral Small 4 (119 млрд, архітектура MoE). Попри слово «Small», для неї потрібні дві серверні карти H100 — на домашній RTX 4090 вона не працює. Це корпоративний інструмент.
- Спільне в обох — свобода і приватність. Ліцензія Apache 2.0 (можна в комерцію без обмежень), європейське походження й локальний запуск — тобто дані нікуди не йдуть.
Мінімальне залізо для домашньої версії: Mistral Small 3.x у кванті Q4 займає близько 14 ГБ і комфортно працює на карті 16–24 ГБ. Чесний нюанс для нашої аудиторії: в українській і російській Mistral пристойний, але поступається Qwen3 і Gemma. Дані актуальні на 16 червня 2026 року.
Два Mistral Small: домашній 3.x і серверний 4
Це перше, у чому потрібно розібратися, бо обрати не ту версію — значить або не запустити модель узагалі, або проґавити актуальну. Ось навігатор по лінійці.Версія Параметри Контекст Залізо Статус Для кого Small 3.1 24 млрд 128K RTX 4090 (24 ГБ) знята з підтримки (листопад 2025) застаріла Small 3.2 24 млрд 128K RTX 4090 (24 ГБ) актуальна до липня 2026 домашній запуск Small 4 119 млрд (MoE, ~6 активних) 256K 2× H100 (сервер) актуальна флагманська сервер, бізнес
Що це означає на практиці. Якщо у вас домашній ПК з однією відеокартою — ваш вибір Mistral Small 3.2 (остання «домашня» версія лінійки). Версію 3.1 уже зняли з офіційної підтримки, але в каталогах вона ще трапляється. А Small 4, попри назву, — це серверна модель: її 119 млрд параметрів не помістяться на жодну споживчу карту. Далі ми докладно розберемо обидві, але фокус — на тій, що реально працює вдома.
Скільки потрібно заліза: VRAM, кванти і швидкість
Для домашньої Mistral Small 3.x вимоги скромні відносно її якості. Як зазвичай, модель запускають у квантованому вигляді (формат GGUF, ходовий квант Q4_K_M).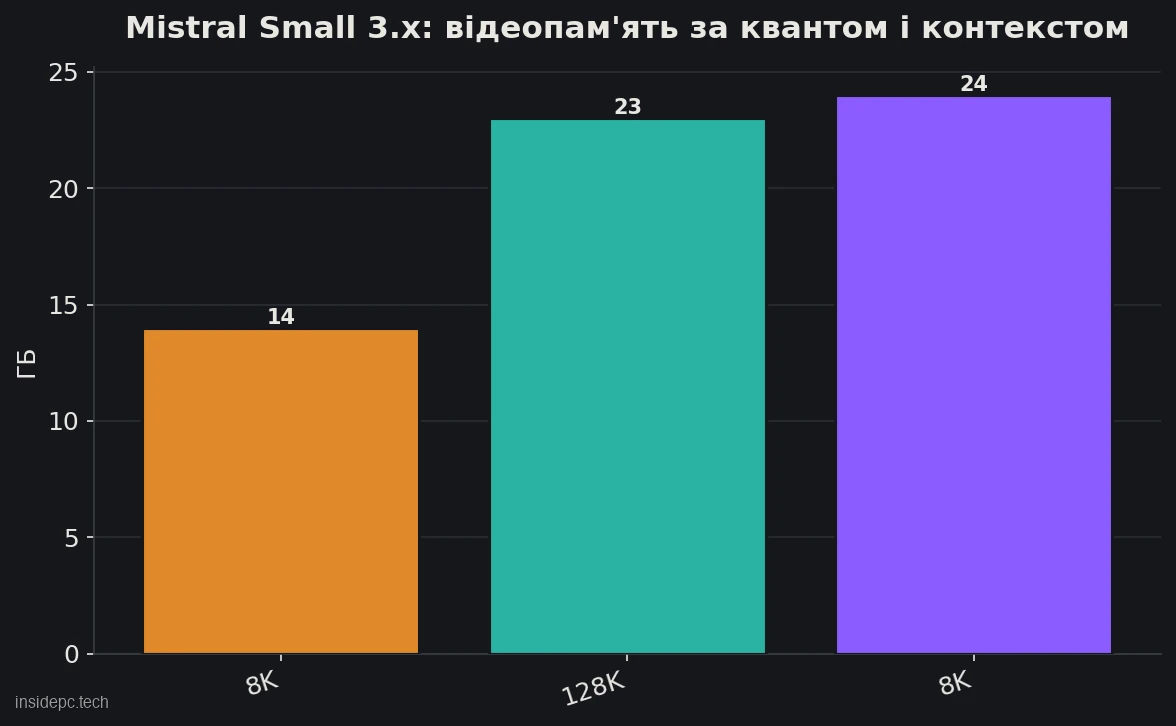
Конфігурація Small 3.x (24B) VRAM Залізо Швидкість Q4_K_M, контекст 8K ~13–14 ГБ RTX 4060 Ti 16 ГБ і вище ~40–70 tok/s (RTX 4090) Q4_K_M, контекст 128K ~22–23 ГБ RTX 3090/4090 (24 ГБ) залежить від завантаження Q8, контекст 8K ~24 ГБ RTX 3090/4090 (24 ГБ) нижче, зате вище якість

Головний практичний висновок: 24-мільярдна Mistral Small цілком влазить на одну карту 24 ГБ — і це її ключова перевага. Важлива поправка: відеопам’ять витрачається не лише на ваги, а й на контекст (KV-кеш), і в Mistral це особливо помітно — за повного вікна 128K потреба зростає з ~14 до ~23 ГБ. Якщо вперлися в нестачу пам’яті, насамперед скорочуйте контекст. Цифри швидкості — орієнтир (за замірами на RTX 4090, Q4, березень 2026) і залежать від заліза та кванта.
Окрім відеокарт, домашня Mistral Small відмінно йде на Apple Silicon: на Mac із чипами M-серії та єдиною пам’яттю 24 ГБ і більше вона запускається через Ollama або LM Studio без окремої відеокарти. Швидкість на ноутбуці буде нижчою, ніж на десктопній RTX 4090, але для чату, роботи з документами та агентних задач її достатньо — а тиша й низьке енергоспоживання йдуть у плюс. Для багатьох власників MacBook це найдоступніший спосіб тримати пристойну локальну модель під рукою, не купуючи окрему відеокарту й не збираючи окремий ПК спеціально під локальний ШІ.
А ось Mistral Small 4 у домашній бюджет не вписується зовсім: для неї потрібні щонайменше дві серверні карти H100 (варіант INT4), а для повноцінної роботи — більше, або станція на кшталт NVIDIA DGX Spark з великим обсягом єдиної пам’яті. На звичайній RTX 4090 запустити її не вийде — про це окремий розділ нижче.
Якщо обираєте відеокарту під локальний ШІ, відштовхуйтеся від обсягу VRAM — докладний розбір у гіді з вибору GPU для ШІ.
Mistral Small 4: MoE-парадокс і reasoning_effort
Раз уже Small 4 — флагман лінійки, варто зрозуміти, чим вона цікава, навіть якщо запускати її ви будете в хмарі, а не вдома.
Small 4 побудована на архітектурі «суміші експертів» (MoE): усього 119 млрд параметрів, але на кожен токен активні лише близько 6 млрд (8 млрд з урахуванням ембеддингів, за даними Mistral). Звідси «парадокс»: модель за якістю грає у вищій лізі, але за швидкістю працює як невелика — Mistral заявляє до 40% приросту і втричі більше запитів за секунду проти Small 3. Платою за це стає пам’ять: щоб активувати будь-кого з експертів, у неї потрібно завантажити всі 119 млрд ваг. MoE економить обчислення, але не відеопам’ять — тому домашня карта й не тягне.
Друга цікава деталь Small 4 — параметр reasoning_effort (зусилля на міркування) з кількома рівнями: від мінімального (швидка відповідь майже без роздумів) до high (модель думає довше й ретельніше). Це не вибір між «швидкою» і «розумною» моделлю, а єдиний регулятор на кожен запит: для простого питання — низьке зусилля, для складної задачі — високе. По суті «газ і гальмо» для глибини міркування.
Сильний бік: функції та агенти
Якщо в Qwen3 головний козир — багатомовність, а в Gemma — мультимодальність, то в Mistral це нативна робота з функціями та інструментами (function calling). Модель навчена видавати структуровану відповідь у форматі JSON і викликати зовнішні інструменти — це саме те, що потрібно для побудови агентів та автоматизацій.
На практиці це означає, що Mistral Small зручно ставити в основу локального асистента, який не просто балакає, а виконує дії: смикає API, заповнює форми, маршрутизує запити, працює за чітким протоколом. Для розробника, що збирає агентний пайплайн на своєму залізі, це вагомий аргумент на користь Mistral — особливо у зв’язці з її низькою затримкою відповіді.
Конкретний приклад: на Mistral Small зручно зібрати домашнього асистента, який за командою шукає у ваших документах, додає події в календар через API і форматує відповідь строго за заданою схемою — і все це локально, без витоку даних назовні. Там, де звичайна чат-модель просто опише, що треба зробити, Mistral поверне готовий виклик функції з параметрами, який ваш код виконає без додаткового розбору тексту.
Запуск: Ollama, LM Studio, llama.cpp
Найпростіший шлях для домашньої Small 3.x — Ollama:
ollama run mistral-small3.2 # актуальна домашня версія, 24B
ollama run mistral-small # тег latest — перевірте, яку версію тягне
Тут криється типова пастка 2026 року: тег mistral-small без номера в різний час може вказувати на різні версії. Щоб отримати саме те, що потрібно, указуйте версію явно (mistral-small3.2), а не покладайтеся на latest. Перед завантаженням звіртеся зі сторінкою моделі в каталозі Ollama.
LM Studio — графічний інтерфейс із каталогом моделей; зручно, якщо не любите термінал і хочете бачити налаштування наочно.
llama.cpp і vLLM — для тонкого налаштування й серверних сценаріїв. Урахуйте: підтримка громіздкої Small 4 у локальних рушіях з’явилася не одразу після релізу, тому якщо плануєте запускати саме її (на придатному залізі), заздалегідь перевірте актуальний статус сумісності.
Як і інші моделі, Ollama одразу піднімає локальний API на localhost:11434 у форматі OpenAI — це особливо цінно для Mistral, з огляду на її сильні сторони у функціях: підключайте її до агентів, ботів і редакторів коду напряму.
Скільки місця на диску займе Mistral Small? Домашня версія 3.x у кванті Q4 — близько 14 ГБ, у Q8 — порядку 24 ГБ. Закладайте запас під кілька моделей і кеш. Ollama зберігає завантажені моделі у своїй папці й підвантажує потрібну при запуску; на серверну Small 4 місце не закладайте — вона в будь-якому разі не для домашньої карти.
Налаштування під себе: контекст, функції та API
Кілька параметрів, які варто підлаштувати під задачу.
- Довжина контексту (num_ctx). Mistral Small тримає до 128K токенів, але Ollama за замовчуванням виділяє менше. Для довгих документів піднімайте
num_ctx— пам’ятаючи, що контекст у Mistral помітно витрачає відеопам’ять (з ~14 до ~23 ГБ на повному вікні). - Температура. Загальноприйняті орієнтири спільноти: для коду, функцій та фактичних задач — низька (0.1–0.3), для вільного тексту — вище (близько 0.7).
- Function calling. Головна фішка Mistral розкривається через API: передавайте опис інструментів у форматі, сумісному з OpenAI, і модель сама вирішить, коли їх викликати, та поверне структурований JSON. Це основа для агентів і автоматизацій.
- Системний промпт. Закріплює роль і мову відповіді; для української та російської явне вказання мови стабілізує вивід.
Усі дані під час роботи з локальною Mistral лишаються на вашому комп’ютері, а за токени платити не потрібно — для приватних агентних сценаріїв це вирішальний плюс.
EU-кут: французька модель і приватність
Це наш information gain, важливий саме для практичного вибору. Mistral AI — французька компанія і єдиний європейський розробник ШІ світового рівня. Для частини аудиторії це не абстракція, а конкретний довід.
- Юрисдикція даних. При роботі з хмарним API Mistral дані обробляються в дата-центрах ЄС, і на компанію не поширюється американський CLOUD Act. Для бізнесу, чутливого до того, де і за чиїми законами зберігаються дані, це вагомо.
- Локальний запуск знімає питання зовсім. Коли модель працює на вашому залізі, дані не йдуть нікуди — ні в США, ні в ЄС. З огляду на повне набуття чинності європейського регламенту EU AI Act у 2026 році локальне розгортання помітно спрощує відповідність вимогам.
- Свобода ліцензії. Apache 2.0 у Mistral Small знімає юридичні обмеження на комерційне використання — на відміну від ліцензії Llama з її порогами.
Іншими словами, Mistral Small — вибір для тих, кому важливі не лише бенчмарки, але й контроль над даними та юридична чистота.
Важлива заувага: «європейська юрисдикція» значуща передусім при роботі з хмарним API Mistral. При локальному запуску країна походження моделі вже не впливає на те, де лежать ваші дані, — вони на вашому диску. Але й тут походження лишається непрямим плюсом: Mistral як EU-компанія будує моделі з огляду на європейські норми щодо даних і прозорості, що знижує ризик неприємних сюрпризів у ліцензії чи поведінці моделі.
Українська і російська: чесна оцінка
Не прикрашатимемо: в українській і російській Mistral Small поступається лідерам. Модель офіційно багатомовна й підтримує обидві мови, але якість тут середня — за незалежними замірами в Mistral помітно нижча середня точність на не-англійських мовах, а ефективність токенізації для української, за даними академічних досліджень, невисока (це означає більше токенів на той самий текст — повільніше й дорожче за контекстом).
Практичний висновок: для задач, де головне — грамотний український або російський текст (переклад, копірайтинг, діалог), краще взяти Qwen3 або Gemma. А ось якщо мова інтерфейсу вторинна, а головне — швидкість, функції та агентні сценарії (де дані й команди частіше англійською), Mistral лишається сильним варіантом незалежно від мови.
Бенчмарки: де стоїть Mistral Small
Цифри — орієнтир, офіційні результати звіряйте в картці моделі. Домашня Small 3.1 свого часу показувала близько 80,6% на тесті загальних знань MMLU і порядку 88% на програмуванні HumanEval — міцний результат для 24B-моделі. Серверна Small 4 помітно сильніша: приблизно 71% на складному науковому GPQA Diamond і 78% на MMLU-Pro, а на окремих бенчмарках коду вона обходить навіть значно більшу GPT-OSS 120B (за даними Mistral, березень 2026).
Головний практичний сенс цих цифр для домашнього користувача: Mistral Small 3.x за своїх скромних 24 млрд параметрів грає на рівні моделей більших, особливо в задачах, що вимагають структурованості й точності, — а це і є її ніша.
Mistral проти Qwen3, Gemma і Llama
«Найкращої моделі взагалі» не буває. Ось чесне порівняння домашньої Mistral Small 3.x з трьома головними суперниками в локальному сегменті (станом на червень 2026).Критерій Mistral Small Qwen3 Gemma 4 Llama Українська/російська Середньо Найкращий Добре Середньо Функції та агенти Дуже сильно Добре Добре Середньо Мультимодальність Vision Є варіанти Сильна Vision Ліцензія Apache 2.0 Apache 2.0 Apache 2.0 Community Розмір під 24 ГБ 24B (із запасом) 32B 31B 70B з offload Юрисдикція ЄС (Франція) Китай США США
Де Mistral об’єктивно попереду: функції та агенти, компактність (24B лишає запас пам’яті під контекст) і європейська юрисдикція. Де варто обрати інакше: для української та російської сильніші Qwen3 і Gemma, а якщо потрібна просунута мультимодальність — у Gemma вона багатша.
Коли брати Mistral Small, а коли альтернативу
Зведемо вибір до простих сценаріїв.
Беріть Mistral Small 3.x, якщо:
- ви будуєте локального агента або автоматизацію з викликом інструментів — тут її function calling один із найкращих;
- важлива компактність і швидкість: 24B лишає на карті 24 ГБ запас під контекст і відповідає з низькою затримкою;
- для вас принципові юрисдикція даних і свобода ліцензії — європейське походження й Apache 2.0;
- мова інтерфейсу й команд переважно англійська.
Оберіть альтернативу, якщо:
- головне — грамотний український або російський текст: беріть Qwen3 або Gemma;
- потрібна багата мультимодальність (фото, відео, аудіо, OCR) — у Gemma вона ширша;
- вам потрібна саме серверна потужність Small 4, але немає двох карт H100 — практичніше хмарний API або інша модель під ваше залізо.
Універсальної відповіді немає: Mistral Small — це про ефективність, функції та контроль над даними, а не про абсолютний максимум якості чи найкращу в класі російську.
Ризики й граблі
- Плутанина версій — головна пастка. «Mistral Small» — це і знята з підтримки 3.1, і домашня 3.2, і серверна 4. Для дому беріть саме 3.2; не намагайтеся запускати Small 4 на споживчій карті — не запрацює.
- Тег
latestнепередбачуваний. В Ollamamistral-smallбез номера може тягнути не ту версію — указуйте її явно. - Слабша за лідерів у кирилиці. Для україно- й російськомовних текстів Mistral — не перший вибір; це її відоме обмеження.
- Контекст їсть пам’ять. Повне вікно 128K піднімає потребу з ~14 до ~23 ГБ — на карті 16 ГБ довгий контекст не вийде.
- Small 4 і локальні рушії. Підтримка великої MoE-моделі в llama.cpp/Ollama з’явилася не одразу; якщо націлилися на Small 4, перевірте актуальний статус.
- Перегрів за довгих сесій. Тривале навантаження гріє відеокарту — стежте за температурами на компактних збірках.
FAQ
Яку версію Mistral Small ставити на домашній ПК? Mistral Small 3.2 — це остання «домашня» версія лінійки (24 млрд параметрів), вона вміщується на карту 24 ГБ і підтримується до липня 2026 року. Версію 3.1 уже знято з підтримки, а Small 4 — серверна й на домашній відеокарті не запуститься.
Чому Mistral Small 4 не працює на моїй RTX 4090? Тому що, попри слово «Small», це модель на 119 млрд параметрів (архітектура MoE). У пам’ять потрібно завантажити всі ваги — це близько 60 ГБ навіть у форматі INT4, що вимагає щонайменше двох серверних карт H100. Для домашнього заліза беріть Small 3.2.
Чи хороший Mistral Small для української мови? Прийнятний, але не найкращий. Mistral офіційно підтримує українську й російську, проте за якістю поступається Qwen3 і Gemma, а токенізація для української менш ефективна. Якщо мова — головне у вашій задачі, обирайте конкурентів; якщо важливіша швидкість і функції — Mistral підійде.
Чим Mistral Small вирізняється серед інших локальних моделей? Трьома речами: нативною роботою з функціями та інструментами (зручно для агентів), компактністю за високої якості (24B із запасом влазить у 24 ГБ) і європейським походженням із ліцензією Apache 2.0 — тобто свободою для комерції й контролем над даними.
Яку команду використати для запуску в Ollama?
Для домашньої версії — ollama run mistral-small3.2 з явним указанням номера. Уникайте тега mistral-small без версії: він може вказувати на різні моделі в різний час. Перед завантаженням звіртеся зі сторінкою моделі в каталозі Ollama.













