



Коротко (TL;DR)
Локальный ИИ — это нейросеть (как ChatGPT), которая работает на вашем компьютере, а не в облаке. Никакой подписки, ваши данные никуда не уходят. Главный вопрос не «какую видеокарту купить помощнее», а «что я буду на ней делать».
- Коротко (TL;DR)
- Что такое локальный ИИ и зачем он нужен
- Короткий словарь (без него дальше будет сложно)
- Под какие задачи берут локальный ИИ
- Почему лучше отдельный сервер, а не рабочий ноутбук
- Сколько видеопамяти нужно под модель
- Сборки по бюджету: четыре варианта
- Какие видеокарты NVIDIA брать: не только 3090
- Для продвинутых: сервер на 2–4 видеокарты
- AMD дешевле NVIDIA — но есть нюанс
- Когда лучше Mac или мини-ПК, а не сборка
- Цены на украинском рынке
- Безопасность и риски
- Итог: что собрать под ваш случай
- FAQ
Запомните одно правило: сначала задача, потом железо. От задачи зависит, какая нужна модель. От размера модели зависит, сколько нужно видеопамяти. А видеопамять — это и есть главная характеристика, на которую смотрят при выборе.
Если очень коротко:
- Хотите просто попробовать (чат, лёгкий помощник) — хватит видеокарты на 8–12 ГБ или даже обычного ноутбука.
- Серьёзная работа (кодинг, документы, агенты) — одна видеокарта на 24 ГБ. Лучший выбор по цене — б/у RTX 3090 (около 42 000–48 000 ₴ в Украине). Закрывает почти всё.
- Большие модели или несколько пользователей — две видеокарты или Mac с большой памятью. Это уже отдельный, более сложный разговор.
Ниже всё по порядку и простыми словами: что такое локальный ИИ, короткий словарь терминов, под какие задачи что нужно, сборки по бюджету с ценами в гривнах и долларах, и отдельно — для тех, кто хочет собрать мощный сервер. Если же хотите просто сравнить готовые устройства между собой, это в нашем гиде по выбору железа для локального ИИ.

(Данные актуальны на 23 июня 2026. Цены и скорости — с датами прямо в тексте. Курс для пересчёта — 44,90 ₴/$ по НБУ на 23 июня 2026.)

Что такое локальный ИИ и зачем он нужен
Локальный ИИ — это та же нейросеть, что и ChatGPT или Claude, но запущенная на вашем железе. Вы скачиваете модель (файл с «мозгами» нейросети) и запускаете её у себя. Интернет для работы не нужен.
Зачем это людям:
- Приватность. Ваши документы, код и переписка не уходят на чужие серверы. Для юриста, врача или разработчика это часто решающий аргумент.
- Нет подписки. Заплатили за железо один раз — пользуетесь сколько угодно. При больших объёмах это дешевле, чем платить за облачный ИИ помесячно.
- Контроль и свобода. Никаких лимитов, цензуры и «модель обновили, и она стала хуже». Вы выбираете модель сами.
Минусы тоже честные. Топовые облачные модели пока умнее любой, что влезет в домашний компьютер. И железо нужно купить и настроить. Поэтому локальный ИИ берут не «вместо» облака, а под конкретные задачи, где важны приватность, объём или независимость.
Короткий словарь (без него дальше будет сложно)
Эти термины встретятся по всей статье — разберём их сразу, чтобы дальше не спотыкаться.
- Модель — сама нейросеть. Её «размер» меряют в миллиардах параметров и пишут как 8B, 32B, 70B (B — billion, миллиард). Грубо: чем больше число, тем модель умнее, но тем больше памяти ей нужно.
- VRAM (видеопамять) — память на видеокарте. Модель должна целиком поместиться в неё, чтобы работать быстро. Это главная цифра при выборе железа.
- Токены в секунду (ток/с) — скорость ответа. Токен — это кусочек слова. Ориентир: 10 ток/с — это комфортный темп чтения, 40+ ток/с — быстрее, чем вы успеваете читать.
- Квантование (Q4_K_M и т. п.) — сжатие модели, чтобы она занимала меньше памяти. Похоже на сжатие фото в JPEG: чуть теряем в качестве, сильно выигрываем в размере. Обозначается от Q2 до Q8 — чем больше число, тем точнее и тяжелее. Q4_K_M — рабочий компромисс, его и берут по умолчанию.
- Контекст — сколько текста модель «помнит» в одном диалоге. Чем длиннее контекст, тем больше нужно дополнительной памяти (её называют KV-кэш).
- MoE (Mixture of Experts) — особый тип модели, где на каждый запрос работает только часть «мозга». Поэтому большая MoE-модель работает быстро даже на скромном железе.
- Ollama — бесплатная программа, которая запускает модель на вашем компьютере одной командой. Что-то вроде «плеера» для нейросетей. Поверх неё ставят Open WebUI — это привычное окно чата в браузере, как у ChatGPT, только локально. А vLLM — это движок помощнее: он обрабатывает много запросов параллельно и нужен, когда сервером пользуются несколько человек.
Теперь к делу.
Под какие задачи берут локальный ИИ
Прежде чем смотреть на железо, найдите свою задачу. Мы собрали самые частые сценарии, под которые люди ставят локальный ИИ дома и для работы — по обсуждениям на r/LocalLLaMA и свежим гайдам 2026 года (Medium, на 19 июня 2026). Скорее всего, ваш случай тут есть.
| Задача | Что это на практике | Модель | Нужно VRAM |
|---|---|---|---|
| Приватный чат-помощник | Замена ChatGPT для личных и рабочих данных | 8–14B (Qwen3, Gemma 3) | 8–16 ГБ |
| Кодинг | Подсказки и рефакторинг прямо в редакторе кода | Qwen2.5-Coder-32B | 24 ГБ |
| Автономные агенты | ИИ сам выполняет цепочку действий, вызывает инструменты | Qwen3-Coder 30B-A3B (MoE) | 24 ГБ |
| Тексты, копирайтинг | Черновики, редактура, переводы | 14–32B | 12–24 ГБ |
| Работа с документами (RAG) | Вопросы к своим файлам, заметкам, базе знаний | 8–32B + поиск | 16–24 ГБ |
| Аналитика, data science | Обработка данных, разметка, эксперименты | 8–32B | 16–24 ГБ |
| Расшифровка речи (Whisper) | Голос и видео в текст, субтитры | Whisper | 6–12 ГБ |
| Генерация картинок | Stable Diffusion, Flux (это уже не текст, но та же видеопамять) | SDXL / Flux | 8–16 ГБ |
Что из этого видно сразу. Большинство популярных задач закрывает видеокарта на 24 ГБ — это «золотая середина» 2026 года (willitrunai, на 22 апреля 2026). Лёгкий чат, расшифровка речи и картинки живут и на 8–16 ГБ. А вот по-настоящему большие модели (70B) и несколько одновременных пользователей — это уже две карты, об этом ниже.
Отдельно про две частые пары задач. Для агентов (когда ИИ сам ходит по шагам и дёргает инструменты) важнее не скорость, а длинный контекст и стабильность — тут хороши MoE-модели вроде Qwen3-Coder 30B-A3B (около 75 ток/с на хорошей карте). А для кодинга есть жёсткое правило по качеству сжатия: ниже Q4_K_M опускаться нельзя. На сильно сжатых Q2–Q3 модель начинает выдумывать несуществующие команды — для кода это не «чуть хуже», а просто нерабочий вариант (craftrigs, на 27 марта 2026).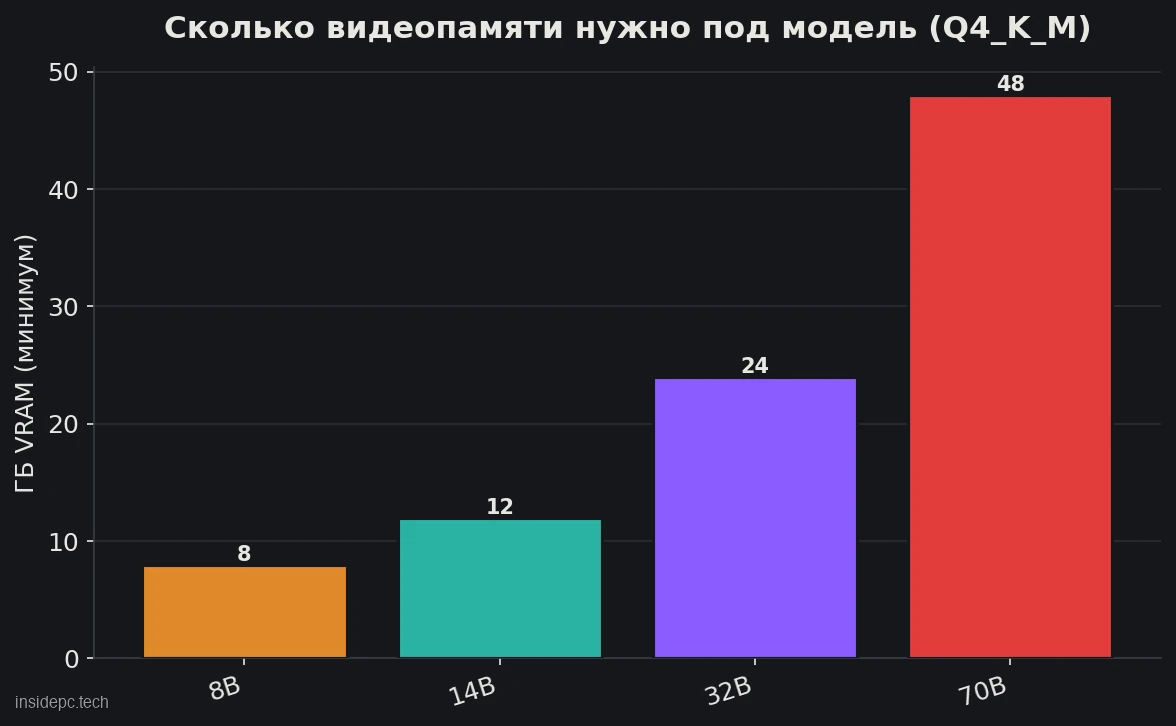
Почему лучше отдельный сервер, а не рабочий ноутбук
Самая частая ошибка новичка — поставить ИИ на свой основной ноутбук. Для маленьких моделей это работает. Но ноутбук начинает греться, шуметь и быстро садить батарею ровно тогда, когда вы работаете. А добавить ему видеопамяти нельзя.
Решение проще, чем кажется: отдельная машина-сервер плюс лёгкий ноутбук как «пульт». Мощный компьютер с видеокартой стоит где-нибудь в углу или в кладовке. Вы к нему подключаетесь по домашней сети с любого устройства — ноутбука, телефона, второго ПК.
Как это работает:
- На сервере запускаете модель через Ollama (одна команда).
- Поверх ставите Open WebUI — чтобы был привычный чат в браузере. Получается ваш личный «ChatGPT», доступный всем устройствам в доме.
- Чтобы пользоваться им и вне дома, подключаете Tailscale — это бесплатная программа, которая создаёт защищённую личную сеть между вашими устройствами. Не нужно ничего «прокидывать» в интернет и разбираться с настройками роутера.
Что это даёт:
- Ноутбук остаётся лёгким и тихим. Считает сервер, а на ноутбуке просто открыт чат. Батарея и кулеры не страдают.
- Доступ откуда угодно. Один сервер обслуживает рабочий ноут, домашний ПК и телефон.
- Апгрейд не трогает рабочее место. Добавить память или вторую карту можно на сервере, ноутбук при этом не меняется.
Минусы честные. Нужно один раз настроить сеть. И сервер тратит электричество, пока включён. Но для регулярной работы это окупается удобством.
Сколько видеопамяти нужно под модель
Главное число при выборе — сколько видеопамяти займёт ваша модель. Считается просто. Берём вес модели в сжатии Q4_K_M и прибавляем немного на контекст. Вот ориентир:Размер модели Сколько весит (Q4_K_M) Запас на контекст Итого нужно VRAM 7–8B ~5 ГБ +1 ГБ 8 ГБ 13–14B ~8 ГБ +1,5 ГБ 12 ГБ 32–34B ~20 ГБ +3–4 ГБ 24 ГБ 70B ~40 ГБ +6–8 ГБ 48 ГБ (или 2 карты по 24 ГБ)
Почему так важно, чтобы модель влезла целиком. Если памяти не хватает, компьютер начинает использовать обычную системную память вместо видеопамяти. Она в разы медленнее. Скорость падает с комфортных 50–100 ток/с до 2–5 ток/с — это медленнее, чем печатает человек (computingforgeeks, на 20 июня 2026). Поэтому брать память надо с запасом, а не впритык.
Маленький, но важный совет про обычную оперативную память (RAM): её ставьте не меньше, чем видеопамяти, а лучше вдвое больше. Под одну карту на 24 ГБ — 64 ГБ RAM (computingforgeeks, на 20 июня 2026).
Сборки по бюджету: четыре варианта
Ниже четыре уровня — от «попробовать» до «домашний сервер». Цены на видеокарты реальные, с датами. Цены на остальные детали — примерный ориентир розницы на июнь 2026 (считайте вилкой ±15%). Гривны посчитаны по курсу 44,90 ₴/$.
1. Попробовать — до $500 (до ~22 000 ₴)
Если у вас уже есть игровой ПК или ноутбук с видеокартой на 8–12 ГБ — вы уже готовы. Запускайте Ollama и пробуйте модели 7–14B: чат, лёгкий кодинг, расшифровку речи. Покупать ничего не нужно. Это лучший способ понять, нужен ли вам локальный ИИ вообще, прежде чем вкладываться.
2. Рабочая лошадка — одна RTX 3090 ($1 600–2 100 / 72 000–94 000 ₴)
Самый разумный выбор для серьёзной работы одного человека. Одна б/у RTX 3090 на 24 ГБ закрывает почти всё из таблицы задач: кодинг, агентов, документы, аналитику. Скорость: лёгкая 8B — около 119 ток/с, рабочая 32B — около 37–38 ток/с (computingforgeeks, на 20 июня 2026). Если ПК уже есть и в нём хороший блок питания — нужна только сама карта (~$1 000).Что Выбор Цена ($) Цена (₴) Видеокарта б/у RTX 3090 24 ГБ 900–1 250 41 500–48 000 Процессор Ryzen 5 7600 ~180 ~8 100 Плата B650 (AM5) ~150 ~6 700 Оперативная память 64 ГБ DDR5 (2×32) ~160 ~7 200 Блок питания 850 Вт, 80+ Gold ~110 ~4 900 Накопитель SSD 1 ТБ NVMe ~70 ~3 100 Корпус + охлаждение ATX с хорошим продувом ~120 ~5 400 Итого ~1 690–2 040 ~76 000–92 000
3. Помощнее — две RTX 3090 или одна RTX 5090 ($2 500–4 500 / 112 000–202 000 ₴)
Тут развилка. Нужна большая модель 70B — берёте вторую б/у 3090, получаете 48 ГБ и тянете её целиком. Нужна максимальная скорость на средних моделях — одна новая RTX 5090 (32 ГБ): 8B около 250 ток/с, 32B около 71 ток/с. У неё два нюанса: цена кусается из-за дефицита памяти ($2 900–4 300 за карту), и под неё нужен новый блок питания — 575 Вт с разъёмом 12V-2×6 (computingforgeeks, на 20 июня 2026).
4. Домашний сервер — 4 карты или большой Mac ($5 000+ / от 225 000 ₴)
Для нескольких пользователей сразу или очень больших моделей. Это четыре видеокарты на серверной платформе, профессиональная карта на 96 ГБ или Mac Studio с большой памятью. Сборка из нескольких карт — отдельная тема, она ниже (и большинству читателей она не понадобится).
Какие видеокарты NVIDIA брать: не только 3090
RTX 3090 звучит чаще всего, потому что у неё лучшая цена за 24 ГБ. Но это не единственный вариант — у NVIDIA есть карты под каждый бюджет. Вот лестница по объёму памяти, чтобы было куда манёврировать (цены — ориентир на 2026 год, перед покупкой проверяйте розницу).Карта VRAM Под что Ориентир цены RTX 4060 Ti 16 ГБ 16 ГБ дешёвый вход, модели 7–14B ~$400 RTX 5070 Ti 16 ГБ быстрый 16 ГБ нового поколения ~$750 RTX 5080 16 ГБ 16 ГБ + скорость, дешевле 4090 ~$1 000 RTX 3090 (б/у) 24 ГБ лучшая цена за 24 ГБ, есть NVLink ~$900–1 250 RTX 4090 24 ГБ те же 24 ГБ, но заметно быстрее; без NVLink ~$1 400–1 800 RTX 5090 32 ГБ максимум скорости, 32 ГБ ~$2 900–4 300 NVIDIA RTX A6000 48 ГБ модель 70B на одной карте, память с защитой ECC ~$2 500–3 500 RTX PRO 6000 96 ГБ 70B с большим запасом, профи-уровень $8 500+
(цены: bestgpuforllm и craftrigs, 2026)
Что из этого выбрать:
- Для входа (7–14B) необязательно искать б/у 3090 — подойдёт новая RTX 4060 Ti 16 ГБ или 5070 Ti. Карта с гарантией и без истории майнинга.
- В классе 24 ГБ выбор между 3090 (дешевле, есть мост NVLink) и 4090 (дороже, но быстрее). Если важна цена за гигабайт — 3090, если скорость — 4090.
- Для модели 70B на одной карте есть отдельный приём: RTX A6000 с 48 ГБ держит её целиком, да ещё и с памятью ECC (память с коррекцией ошибок — полезна для долгих вычислений без сбоев). Это альтернатива сборке из двух 3090 — дороже, зато без возни с двумя картами и их охлаждением.
Для продвинутых: сервер на 2–4 видеокарты
Этот раздел можно смело пропустить, если вам хватает одной карты. Он для тех, кто хочет собрать мощный сервер. Здесь же — главная ошибка, на которой теряют деньги.
Главное: вторая карта добавляет память, а не скорость
Звучит логично: «поставлю четыре карты — будет в четыре раза быстрее». На самом деле нет. В обычном режиме (через llama.cpp — это движок запуска моделей, на котором работает в том числе Ollama) модель просто делится между картами, и они работают по очереди, а не вместе. Замеры это подтверждают: большая модель 70B выдаёт одни и те же 16–17 ток/с хоть на двух, хоть на четырёх, хоть на шести картах (craftrigs, на 29 марта 2026).
То есть лишние карты дают больше памяти (можно загрузить модель крупнее), но не ускоряют ответ для одного человека. Реальный смысл в нескольких картах есть только в двух случаях:
- Несколько пользователей одновременно. Если сервером пользуется команда, движок vLLM раздаёт запросы по картам параллельно. На четырёх пользователях он выдаёт 28 ток/с против 12 у обычной Ollama — почти в 2,3 раза больше (craftrigs, на 19 апреля 2026).
- Очень большая модель, которая не влезает в одну карту. Тогда несколько карт нужны просто чтобы её вместить.
Вывод: берите вторую карту ради памяти под 70B или ради команды. Но не ждите, что лично ваш чат станет вдвое быстрее.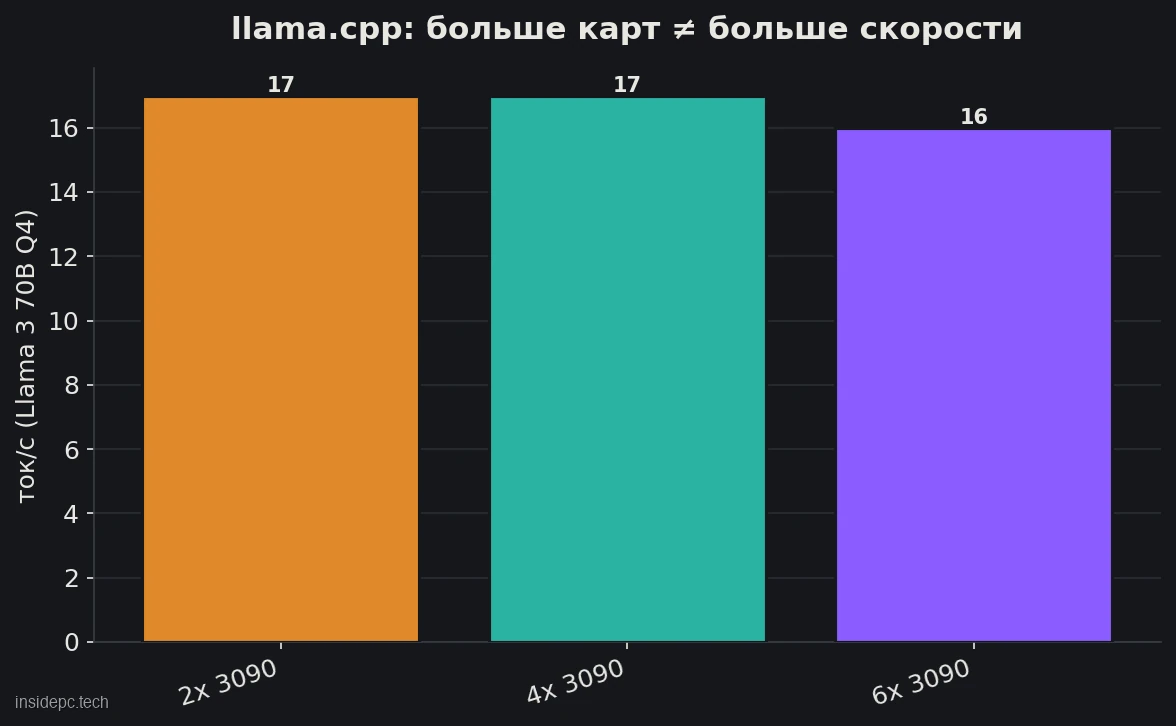
Питание и электричество
Видеокарта RTX 3090 на бумаге потребляет 350 Вт, но в реальности под нагрузкой берёт 380–420 Вт. Отсюда требования к блоку питания:Сколько карт Реальное потребление Нужен блок питания 1× RTX 3090 ~750–850 Вт 850 Вт 2× RTX 3090 ~1 100–1 300 Вт 1 200–1 500 Вт 4× RTX 3090 ~1 750–2 100 Вт 2 000 Вт
(craftrigs + computingforgeeks, на 20–29 июня 2026)
Есть отличный приём — андервольт, то есть мягкое снижение напряжения и потребления карты. Если ограничить каждую 3090 до 220 Вт, четыре карты вместе будут есть около 880 Вт вместо 1 750, а скорость почти не упадёт (craftrigs, на 29 марта 2026). Это сразу решает три проблемы: меньше счёт за электричество, меньше жара в комнате, и хватает одного блока питания. Андервольт под несколько карт делают сразу, это нормальная практика.
Корпус и охлаждение
Граница проходит между тремя и четырьмя картами. Три RTX 3090 ещё помещаются в большой обычный корпус при хорошем продуве (как минимум три вентилятора на вдув). Четыре — это уже либо открытая рама (как у майнеров), либо обязательный андервольт, иначе карты перегреваются (craftrigs, на 29 марта 2026).
Отдельная проблема — толщина карт. Современные 3090 занимают по 2,5–3 слота и, поставленные вплотную, «варят» друг друга. Поэтому карты разносят на удлинителях PCIe (райзерах) или ставят в открытую раму. Важное отличие от майнинга: для ИИ нельзя экономить на скорости разъёма. Майнерские райзеры на одну линию тут не годятся — картам нужна полная скорость линии PCIe (x8 или x16), иначе обмен данными между ними станет узким местом.
Подробный разбор именно пары карт с мостом NVLink — в нашем обзоре сборки на 2× RTX 3090.
AMD дешевле NVIDIA — но есть нюанс
Карты AMD дают столько же видеопамяти заметно дешевле. Но вы платите за это временем на настройку. У NVIDIA весь софт для ИИ работает сразу «из коробки» (технология называется CUDA). У AMD аналог (ROCm) тоже работает, но настраивается дольше и в основном на Linux.
Два варианта:
- RX 7900 XTX — 24 ГБ, дешевле новой NVIDIA того же класса. По скорости на небольших моделях держится в одном классе с б/у 3090. Минус — возня с настройкой под Linux. Подробно этот путь мы разобрали в обзоре RX 7900 XTX для локального ИИ.
- AMD Instinct MI50 на 32 ГБ — самый дешёвый способ получить аж 32 ГБ видеопамяти, около $210 за карту (eBay, на 22 октября 2025; цену стоит перепроверить — данные старые). Но это серверная карта без нормального охлаждения для домашнего ПК. Без самодельного обдува она перегревается. Вариант для энтузиаста, который любит повозиться.
Простое правило: дорого время — берите NVIDIA, дорог бюджет и не пугает вечер настройки — смотрите на AMD.
Когда лучше Mac или мини-ПК, а не сборка
Иногда собирать ПК вообще не нужно. Есть готовые компактные устройства с большой общей памятью (её называют unified memory — это память, которую делят процессор и графика).
Mac с чипом M4 Max и 128 ГБ памяти (MacBook Pro или Mac Studio) вмещает даже модель 70B. Скорость на ней скромная (около 10 ток/с), зато на средних моделях всё бойко: 30B — около 28 ток/с. Но главный козырь — потребление: 30–50 Вт против 600–900 Вт у сборки на видеокартах (astrolexis, на 21 мая 2026). Для фрилансера, у которого машина работает целыми днями, это серьёзная экономия на электричестве. Минус — Mac дорогой, и на одинаковой модели сборка на NVIDIA всё же быстрее.
Strix Halo (мини-ПК на чипе Ryzen AI Max+ 395, 128 ГБ) — тихая компактная коробка. На лёгких MoE-моделях быстрая, памяти хватает на большой контекст. На плотной 70B медленная — это покупка ради объёма, а не скорости. Важно про цену. Флагманские боксы Strix Halo стоили около $2 000 на старте в 2025-м, но к маю 2026 подорожали примерно до $3 300 из-за дефицита памяти. Если бюджет ограничен, самый дешёвый вход в платформу — Framework Desktop от ~$2 000. Подробно, с цифрами скорости — в нашем обзоре Ryzen AI Max+ 395.
Простое правило: большая общая память (Mac, Strix Halo) — это про объём и тишину, отдельная видеокарта — про скорость.
Цены на украинском рынке
Раз героиня большинства сборок — б/у RTX 3090, на неё и посмотрим. По данным на июнь 2026:
- В магазине с гарантией (serverparts.com.ua) б/у RTX 3090 на 24 ГБ стоит 41 500–48 000 ₴ (на 6–11 июня 2026). Это примерно $925–1 070.
- С рук на OLX можно найти от 26 500 ₴ — дешевле магазина на 40% и больше. Но и риск другой: нет гарантии, неизвестна история карты.
- Для сравнения, в США такая карта стоит $900–1 250. То есть украинский магазинный ценник примерно совпадает с американским.
Курс для пересчёта — 44,90 ₴/$ (НБУ, на 23 июня 2026). Цены на б/у видеокарты скачут: весной 2026 был дефицит памяти, и 3090 заметно подорожали. Поэтому всегда проверяйте ценник на день покупки.
Безопасность и риски
Короткий, но важный раздел — про деньги и про чужой доступ к вашей машине.
- Не открывайте Ollama в интернет без защиты. Если выставить сервер наружу без пароля, любой сможет бесплатно гонять на вашей видеокарте свои запросы. Звучит как редкость, но это массово: исследователи насчитали 175 108 открытых Ollama-серверов по всему миру (SentinelLABS и Censys, на 29 января 2026). Решение простое — не «пробрасывать» порт в интернет, а пользоваться Tailscale (см. раздел про сервер выше).
- Не берите память впритык. Если модель не влезла, скорость падает в десятки раз. Всегда оставляйте запас.
- Не ждите от нескольких карт ускорения. Лишние карты дают память, а не скорость одного запроса. Это главная ошибка при дорогих сборках.
- Проверяйте б/у видеокарту. Многие 3090 прошли годы майнинга. Смотрите температуры под нагрузкой, состояние термопрокладок, отсутствие следов ремонта. Магазинная гарантия на три месяца тут не лишняя.
- Для кода не берите слишком сжатые модели. Ниже Q4_K_M качество кода рушится — модель начинает выдумывать команды.
Итог: что собрать под ваш случай
Чтобы не ломать голову — вот готовые рецепты. Логика всегда одна: задача → размер модели → видеопамять → железо. Найдите свой случай и берите.
- «Хочу просто попробовать, без затрат». Поставьте Ollama на тот ПК или ноутбук, что уже есть. Если видеокарта на 8 ГБ и больше — запускайте модель 7–14B (чат, лёгкий кодинг). Так вы поймёте, нужен ли вам локальный ИИ, прежде чем вкладывать деньги. Бесплатно.
- «Кодинг или тексты, один пользователь». Одна б/у RTX 3090 на 24 ГБ (~$1 000 / 42 000–48 000 ₴). Запускаете Qwen2.5-Coder-32B через Ollama — этого хватает на кодинг, тексты и документы. Хотите карту с гарантией и без майнинг-истории — возьмите новую RTX 5070 Ti или 4060 Ti на 16 ГБ под модели поменьше.
- «Автономные агенты, длинные задачи». Та же RTX 3090 на 24 ГБ, но модель берите MoE — например, Qwen3-Coder 30B-A3B, и поднимайте сервер на vLLM (он лучше держит цепочки и несколько запросов).
- «Нужна большая модель 70B». Два пути. Проще — одна RTX A6000 на 48 ГБ: держит 70B целиком, без возни с двумя картами (~$2 500–3 500). Дешевле — две б/у RTX 3090 (48 ГБ), но настройка сложнее. Детали пары карт — в обзоре сборки на 2× 3090 выше.
- «Несколько человек или небольшая команда». Несколько карт плюс сервер на vLLM — он раздаёт запросы параллельно. Вот здесь лишние карты реально работают (в отличие от одиночного чата). Не забудьте про андервольт и питание.
- «Важна тишина, мало места или дорогая электроэнергия». Mac с M4 Max и 128 ГБ или мини-ПК Strix Halo. Дороже сборки, зато 30–50 Вт вместо 600–900 и никакого шума. Для того, кто работает целыми днями, экономия на электричестве ощутимая.
- «Минимум денег, готов повозиться». AMD: RX 7900 XTX (24 ГБ) или MI50 (32 ГБ). Та же память дешевле, но заложите вечер на настройку под Linux.
И один общий совет для всех. Поднимайте ИИ как отдельный сервер (Ollama + Open WebUI + Tailscale), а не на рабочем ноутбуке. Тогда машина считает где-нибудь в углу, а вы подключаетесь к ней с любого лёгкого устройства. И сразу настройте доступ через Tailscale — не открывайте сервер в интернет напрямую.
Если же выбор между готовыми устройствами всё ещё не очевиден, сравните их по памяти и скорости в отдельном гиде (ссылка в начале статьи), а потом возвращайтесь к сборке.
FAQ
Можно ли запустить локальный ИИ на игровом ноутбуке? Да. Ноутбук с видеокартой на 8–16 ГБ потянет модели 7–14B — этого хватает для чата и лёгкого кодинга. Проблема не в том, что «не запустится», а в удобстве: под нагрузкой ноутбук греется, шумит и садит батарею. Для регулярной работы лучше вынести модель на отдельный сервер и подключаться к нему с того же ноутбука.
Какой минимальный бюджет, чтобы кодить локально почти как в облаке? Одна б/у RTX 3090 на 24 ГБ (около $1 000, или 41 500–48 000 ₴ в Украине на июнь 2026) запускает сильную модель для кода Qwen2.5-Coder-32B со скоростью около 37–38 ток/с (Ollama, на март 2026). По качеству она близка к облачным помощникам для большинства повседневных задач. Если ПК уже есть, нужна только карта.
Чем локальный ИИ лучше ChatGPT? Главное — приватность и отсутствие подписки. Данные не уходят на чужие серверы, и нет помесячной платы. Минус — топовые облачные модели пока умнее. Поэтому локальный ИИ берут там, где важны конфиденциальность, большой объём работы или независимость от сервиса, а не ради «обогнать ChatGPT по уму».
Сколько электричества съест сборка на 4 видеокарты? Без оптимизации — около 1 750–2 100 Вт под нагрузкой, это заметный счёт при работе целыми днями. Если применить андервольт (ограничить каждую карту до 220 Вт), потребление падает примерно до 880 Вт, а скорость почти не страдает. Поэтому андервольт на многокарточных сборках делают сразу.
Хватит ли 12 ГБ видеопамяти? Для старта — да. На 12 ГБ работают модели 7–14B: чат, лёгкий кодинг, расшифровка речи, картинки. Но рабочие модели для кода (32B) уже не влезут — им нужна карта на 24 ГБ. Если планируете серьёзный кодинг или агентов, 12 ГБ станут тесными быстро.










