
Коротко (TL;DR)
DeepSeek-R1 — модель, яка на початку 2025 року показала, що відкрита нейромережа вміє міркувати вголос: перед відповіддю вона виписує ланцюжок думок у блоці <think>, наче людина на чернетці. За математикою й логікою це вивело її на рівень закритої o1 від OpenAI. Але є нюанс, що ламає більшість очікувань.
- Коротко (TL;DR)
- Що таке DeepSeek-R1 і навіщо вона потрібна
- Повна R1 671B проти дистилятів: чому 671B не для дому
- Лінійка R1-Distill: шість моделей на реальне залізо
- Скільки потрібно заліза: дистилят, квант і швидкість
- Дистилят — це не «маленька R1»
- Ліцензія: вільна MIT і нюанс Llama-base
- Запуск: Ollama, LM Studio, llama.cpp
- Налаштування під себе: контекст, міркування і режим API
- Бенчмарки: що реально вміє
- Українська і російська: Qwen-base проти Llama-base
- Що нового у 2025–2026
- Qwen3, QwQ, Llama: з чим порівнювати
- Ризики й граблі
- FAQ
- Повна R1 — не для дому. Це модель на 671 млрд параметрів; щоб запустити її локально, потрібен сервер із сотнями гігабайтів пам’яті. На звичайному ПК її не підняти.
- Домашній шлях — дистиляти. DeepSeek випустила шість зменшених моделей (від 1,5B до 70B), які «навчили думати» як R1. Дистилят на 7–8B запускається на відеокарті з 8 ГБ, а 32B-версія на карті 24 ГБ за математикою обходить o1-mini.
- Важливо розуміти, що це. Дистилят — не «маленька R1», а звичайна Qwen або Llama, донавчена на міркуваннях R1. Він розумніший за базову модель на логічних задачах, але це не та сама мережа, що повна R1.
Ліцензія — вільна MIT (з однією заувагою для версій на базі Llama). Чесний мінус: DeepSeek — китайська модель, і політична цензура зашита прямо у ваги, тобто працює навіть при локальному запуску без інтернету. Розберемо, який дистилят обрати, чого чекати за швидкістю й де підводні камені.
Дані актуальні на 16 червня 2026 року.
Що таке DeepSeek-R1 і навіщо вона потрібна
Звичайна мовна модель відповідає «з ходу»: отримала запитання — одразу видала текст. Модель, що міркує (reasoning), працює інакше: спершу вона проговорює про себе хід розв’язання — розбиває задачу, перевіряє кроки, відкидає тупикові гілки — і лише потім формулює відповідь. У DeepSeek-R1 ця внутрішня «думка» видна явно: вона заключена в блок <think>...</think>, який модель генерує перед підсумковою відповіддю.
Такий підхід різко піднімає якість на задачах, де важлива логіка: математика, програмування, аналіз, багатокрокові міркування. На простому запитанні «яка столиця Франції» міркування не потрібні й навіть шкодять (модель витрачає час даремно), а ось на олімпіадній задачі або налагодженні коду вони дають помітний приріст.

DeepSeek-R1 вийшла в січні 2025 року і стала першою відкритою моделлю, яка наздогнала закриту o1 від OpenAI за reasoning-бенчмарками — за вільної ліцензії та можливості запуску в себе. Саме це зробило її подією: ШІ, що міркує, перестав бути привілеєм платних хмарних сервісів.
Для домашнього користувача в цьому є конкретний сенс. Модель, що міркує, на своєму ПК — це приватний «розв’язувач» складних задач: розбір коду, перевірка математичних викладок, допомога з логікою та аналізом — без надсилання даних у хмару й без оплати за кожен запит. Ціна — час: за прозорість думки ви платите очікуванням, поки модель «думає». Тому R1-дистиляти тримають не замість швидкої моделі, а поряд із нею — для задач, де якість міркування важливіша за швидкість.
Повна R1 671B проти дистилятів: чому 671B не для дому
Повна DeepSeek-R1 — це модель на архітектурі «суміші експертів» (MoE) з 671 млрд параметрів (з них 37 млрд активні на кожен токен) і контекстом 128K. Навіть у стиснутому вигляді її ваги займають сотні гігабайтів, і для запуску потрібен багатокартковий сервер або робоча станція з величезним обсягом пам’яті. Для домашнього ПК це нереально — жодна споживча відеокарта стільки не вмістить.
Тому разом із R1 команда DeepSeek випустила дистиляти — шість моделей менших. Ідея проста: взяли готові відкриті моделі (Qwen і Llama) і донавчили їх на 800 тисячах прикладів міркувань, згенерованих повною R1. У результаті невелика модель переймає манеру «думати вголос» і помітно додає на логічних задачах, залишаючись при цьому за розміром і вимогами звичайною 7B або 32B.
Ключова думка, яку варто засвоїти одразу: дистилят — це не зменшена копія R1. Це Qwen або Llama, вивчена імітувати міркування R1. Вона краща за свою вихідну версію на математиці й коді, але до якості повної 671B не дотягує. Про це чесно — в окремому розділі нижче.
Лінійка R1-Distill: шість моделей на реальне залізо
Дистиляти побудовані на двох сімействах — Qwen і Llama. Це важливо: від бази залежить і якість мов, і ліцензія.Дистилят База Параметри Контекст R1-Distill-Qwen-1.5B Qwen2.5-Math 1,5 млрд 128K R1-Distill-Qwen-7B Qwen2.5-Math 7 млрд 128K R1-Distill-Llama-8B Llama 3.1 8 млрд 128K R1-Distill-Qwen-14B Qwen2.5 14 млрд 128K R1-Distill-Qwen-32B Qwen2.5 32 млрд 128K R1-Distill-Llama-70B Llama 3.3 70 млрд 128K
Версії на базі Qwen (1.5B, 7B, 14B, 32B) зазвичай краще працюють з українською та російською — про це нижче. Версії на базі Llama (8B, 70B) сильні в англійській, але наслідують ліцензію Llama зі своїми обмеженнями. Найходовіші для дому — 7B/8B (універсал на 8 ГБ) і 32B (максимум якості на 24 ГБ).
Скільки потрібно заліза: дистилят, квант і швидкість
Як і інші локальні моделі, дистиляти запускають у квантованому вигляді (формат GGUF, ходовий квант Q4_K_M). Ось скільки вони займають і якого заліза вимагають.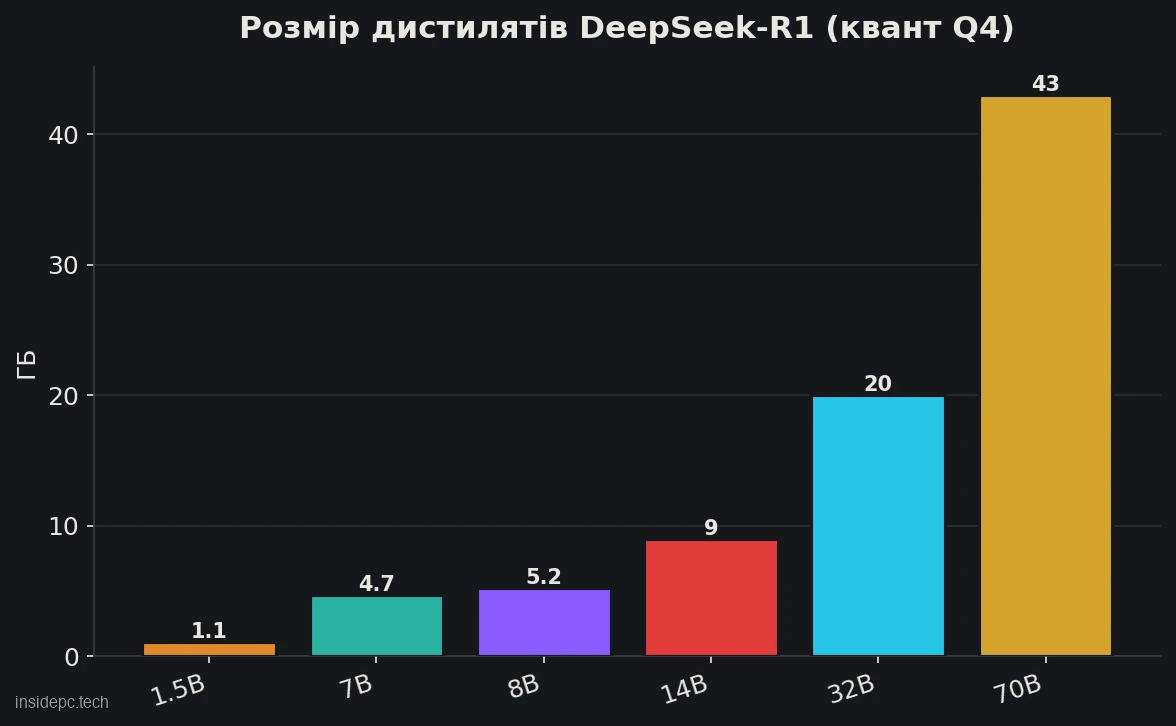
Дистилят (Q4) Розмір файлу VRAM / залізо Швидкість* 1.5B ~1,1 ГБ 4–6 ГБ, навіть CPU ~150+ tok/s 7B ~4,7 ГБ 8 ГБ (RTX 3060, Mac M1) ~90 tok/s 8B ~5,2 ГБ 8 ГБ (RTX 3060, Mac M1) ~90 tok/s 14B ~9 ГБ 12–16 ГБ (RTX 4060 Ti) ~45 tok/s 32B ~20 ГБ 24 ГБ (RTX 3090/4090) ~25–35 tok/s 70B ~43 ГБ 48 ГБ або 2 карти ~5–10 tok/s
*Швидкість — орієнтир на одиночній RTX 4090 (квант Q4): дистилят за швидкістю інференсу близький до своєї базової моделі Qwen/Llama тієї самої розмірності, адже дистиляція не змінює архітектуру. Розміри файлів — за каталогом Ollama на червень 2026 року; точні цифри під вашу конфігурацію дивіться там же на сторінці моделі.
Два важливі уточнення:
- Розмір файлу — це не вся потреба в пам’яті. Понад ваги відеокарті потрібна пам’ять під контекст (KV-кеш), а в моделі, що міркує, контекст розростається швидко: ланцюжок думок сам собою довгий. Тому до розміру файлу додавайте запас — особливо якщо працюєте з довгими задачами.
- Reasoning їсть і час. Перш ніж відповісти, модель генерує міркування — іноді дуже довгі. Оновлена R1-0528 витрачає до 23 тисяч токенів на одну олімпіадну задачу (за даними картки моделі). На слабкому залізі це означає помітне очікування відповіді, тож закладайте терпіння або беріть модель потужнішу.
Головне про швидкість пам’ятати ось що: модель, що міркує, відчувається повільнішою за звичайну тієї самої розмірності не тому, що генерує токени повільніше, а тому, що їх у неї набагато більше — на довгий ланцюжок думок іде час. Самі по собі цифри в таблиці — орієнтир і залежать від заліза, кванта й бекенда; свіжі заміри під конкретну модель звіряйте на її сторінці в каталозі Ollama.
Якщо обираєте відеокарту під локальний ШІ, орієнтуйтеся на обсяг VRAM — докладний розбір у гіді з вибору GPU для ШІ.
Дистилят — це не «маленька R1»
На цьому варто зупинитися, бо багато оглядів створюють хибне враження. Коли ви запускаєте deepseek-r1:7b, ви запускаєте не зменшену R1, а Qwen2.5, донавчену на її міркуваннях.
Що це означає на практиці:
- Плюс: дистилят помітно розумніший за базову модель на математиці, логіці та коді. R1-Distill-Qwen-32B набирає 72,6% на олімпіадному AIME 2024 — це краще, ніж в o1-mini від OpenAI. Для моделі, що вміщується на одну карту 24 ГБ, результат відмінний.
- Мінус: до повної R1 (79,8% на тому ж AIME) і тим паче до оновленої R1-0528 (91,4%) дистиляти не дотягують. Що складніша й нестандартніша задача, то помітніший розрив.
Висновок простий: дистилят — це «апгрейд міркування» звичайної моделі, відмінний для домашніх задач, але не заміна серверній R1. Якщо вам потрібна саме стеля якості — це хмарний API DeepSeek або потужний сервер, а не домашня відеокарта.
Ліцензія: вільна MIT і нюанс Llama-base
Сама DeepSeek-R1 поширюється під ліцензією MIT — однією з найвільніших: дозволено комерційне використання, модифікацію й навіть навчання своїх моделей на виходах R1 (те, що прямо забороняє ліцензія Llama). Для розробників це великий плюс.
Але є тонкість із дистилятами. Вони наслідують ліцензію своєї базової моделі:
- дистиляти на базі Qwen (1.5B, 7B, 14B, 32B) — ліцензія Apache 2.0, така ж вільна;
- дистиляти на базі Llama (8B, 70B) — ліцензія Llama зі своїм порогом у 700 млн користувачів на місяць і обмеженнями (докладніше — в огляді Llama).
Для домашнього використання різниця непомітна. Але якщо будуєте комерційний продукт, обирайте дистилят на базі Qwen — він чистіший за ліцензією.
Запуск: Ollama, LM Studio, llama.cpp
Найпростіший шлях — Ollama. Команди (перевірено за каталогом Ollama, червень 2026):
ollama run deepseek-r1:1.5b # найлегша, навіть на CPU
ollama run deepseek-r1:7b # універсал на 8 ГБ
ollama run deepseek-r1:14b # 12–16 ГБ
ollama run deepseek-r1:32b # максимум якості на 24 ГБ
ollama run deepseek-r1:70b # робоча станція
Важлива деталь: команда ollama run deepseek-r1 без указання розміру тягне версію latest, а це R1-0528-Qwen3-8B — свіжий дистилят на базі Qwen3 (про нього нижче). Якщо вам потрібен конкретний розмір, указуйте тег явно.
LM Studio — графічний інтерфейс із каталогом моделей і зручним переглядом блоку міркувань окремо від відповіді. Хороший вибір, якщо не любите термінал.
llama.cpp напряму — для максимальної продуктивності й тонкого налаштування на потужному залізі.
Порада щодо роботи з моделлю, що міркує: не використовуйте few-shot промптинг (приклади в запиті). За даними аналізу (Nature, 2025) приклади в промпті в R1 навпаки погіршують якість міркувань — модель краще працює, коли ви просто чітко ставите задачу без зразків (zero-shot).
Налаштування під себе: контекст, міркування і режим API
У моделі, що міркує, свої особливості налаштування.
- Температура. DeepSeek рекомендує для R1 не нульову, а помірну температуру — близько 0.5–0.7 (оптимально 0.6). За нуля модель схильна зациклюватися й повторюватися, а надто висока ламає логіку міркувань. Це важлива відмінність від звичайних моделей, де для фактичних задач ставлять майже нуль.
- Довжина контексту (num_ctx). Міркування займають багато місця, тому скупий контекст швидко переповнюється й відповідь обрізається на середині думки. В Ollama піднімайте
num_ctx(наприклад, командою/set parameter num_ctx 8192прямо в чаті) — інакше довгий ланцюжок<think>не вміститься. Пам’ятайте про витрату відеопам’яті на контекст. - Відокремлюйте думки від відповіді. Блок
<think>...</think>— це «чернетка» моделі, а не фінальна відповідь. У чаті його видно, а при роботі через API його зазвичай відрізають програмно, лишаючи користувачеві лише підсумок. У більшості інтерфейсів (LM Studio, веб-обгортки) міркування показуються окремим згортним блоком. - Не нав’язуйте «думай кроками». Модель і так міркує за своєю природою — зайві інструкції в системному промпті можуть тільки збити її. Чітко формулюйте саму задачу.
Режим API. Через Ollama дистилят піднімає сервер на localhost:11434, сумісний із форматом OpenAI, — це зручно для інтеграції в редактори коду, ботів і скрипти. Але із заувагою: відповіді приходять із затримкою на міркування, тому для інтерактивних сценаріїв (автодоповнення коду в реальному часі) модель, що міркує, підходить гірше за звичайну. Її стихія — задачі, де важливіша правильність, ніж миттєвість: розбір складного бага, математика, глибокий аналіз.
Бенчмарки: що реально вміє
Цифри — з першоджерел (картка моделі та репозиторій DeepSeek). Усі reasoning-бенчмарки для повної R1 і дистилятів:Модель AIME 2024 (математика) MATH-500 DeepSeek-R1 (повна) 79,8% 97,3% OpenAI o1-1217 79,2% 96,4% R1-Distill-Qwen-32B 72,6% — R1-Distill-Qwen-7B 55,5% 92,8% OpenAI o1-mini 63,6% —
Що з цього випливає: повна R1 іде врівень з o1 (і навіть трохи вище на MATH-500). Дистилят 32B обходить o1-mini, а маленький 7B за своїх скромних розмірів розв’язує 92,8% задач MATH-500 — для моделі, що влазить на 8 ГБ, це дуже сильно. Але пам’ятайте заувагу з попереднього розділу: бенчмарки дистилятів — це все ще не рівень повної R1.
Українська і російська: Qwen-base проти Llama-base
Це наш information gain. У DeepSeek немає офіційної підтримки української як окремої фічі, але якість тексту українською та російською в дистилятів сильно залежить від базової моделі.
- Дистиляти на Qwen (7B, 14B, 32B) зазвичай дають грамотнішу українську й російську: базові Qwen2.5 навчені на широкому багатомовному корпусі, що включає ці мови.
- Дистиляти на Llama (8B, 70B) в українській помітно слабші — у Llama ці мови не в пріоритеті.
Практичний висновок: якщо для вас важливий україномовний текст, за рівного розміру обирайте Qwen-версію. Перевірити легко — попросіть обидві моделі написати коротке есе українською й порівняйте. І врахуйте: міркування (блок <think>) модель часто веде англійською або китайською навіть при українському запитанні — це нормально, важлива якість підсумкової відповіді.
Що нового у 2025–2026
DeepSeek активно розвиває лінійку, і важливо не заплутатися у версіях.
- R1-0528 (28 травня 2025) — велике оновлення R1: точність на AIME 2025 зросла до 87,5%, додалися виклик функцій і системні промпти. Платою стала «багатослівність» — до 23 тисяч токенів міркувань на складну задачу.
- R1-0528-Qwen3-8B — дистилят нового покоління на базі Qwen3 (а не Qwen2.5). Набирає 86% на AIME 2024 — фактично на рівні гігантської Qwen3-235B, але в розмірі 8B. Саме ця модель тепер ховається за тегом
latestв Ollama, і багато хто цього не помітив. - DeepSeek-V3.2 (грудень 2025) і V4 Preview (квітень 2026) — це вже не reasoning-лінійка R1, а універсальні моделі DeepSeek. Не плутайте: R1 «думає вголос», V3/V4 — звичайні швидкі відповідачі.
Практичний прийом: тримайте під рукою і швидку модель, і ту, що міркує — прості запитання надсилайте швидкій, а складні логічні задачі — R1-дистиляту. Reasoning коштує часу, і витрачати його на «котра година» сенсу немає.
Qwen3, QwQ, Llama: з чим порівнювати
DeepSeek-R1 уже не єдина відкрита модель, що міркує. Ось із чим її порівнюють у 2026 році.Модель Міркування Українська Ліцензія Зауваження DeepSeek-R1 дистиляти Так (сильні) Середньо (Qwen-base краще) MIT / Apache / Llama Цензура у вагах Qwen3 Так (гібрид, перемикається) Найкращий Apache 2.0 Reasoning вмикається командою QwQ-32B Так Добре Apache 2.0 Спеціалізований на міркуваннях Llama 3.x Ні (звичайна) Середньо Llama license Потрібна окрема reasoning-модель
Головний конкурент дистилятів R1 сьогодні — Qwen3: він теж уміє міркувати, але перемикає режим командою і при цьому сильніший в українській, а ліцензія Apache 2.0 чистіша. Для багатьох користувачів Qwen3 став універсальнішим вибором, а R1-дистиляти беруть під конкретні задачі, де важлива саме їхня манера міркувати.
Ризики й граблі
- Цензура зашита у ваги (головний чесний мінус). На відміну від фільтра на сайті, цензура DeepSeek працює на рівні самої моделі: за даними дослідження (arXiv, травень 2025), близько 10 тисяч запитів на політичні теми про Китай викликають відмову або спотворення відповіді навіть при повністю локальному запуску без інтернету. Нюанс щодо дистилятів: версії на базі Qwen наслідують цю цензуру сильніше, а на базі Llama (8B, 70B) — лише частково. Для більшості задач розробки й аналізу фільтр непомітний, але якщо тема для вас важлива — враховуйте.
- Дистилят видають за повну R1. Найчастіша омана.
deepseek-r1:7b— це не R1, а Qwen, вивчена міркувати. Не чекайте від неї рівня серверної моделі. - Reasoning повільний і багатослівний. Довгі ланцюжки думок з’їдають час і контекст. Для простих задач модель, що міркує, надлишкова — використовуйте звичайну.
- Few-shot шкодить. Приклади в промпті погіршують якість R1 — ставте задачу напряму, без зразків.
- Плутанина R1 і V3/V4. R1 — та, що міркує, V3/V4 — звичайні. Це різні лінійки, перевіряйте, що саме завантажуєте.
- Немає контролю довжини міркувань. На відміну від деяких конкурентів, у R1 немає параметра «думай не більше N токенів» — на складній задачі вона може «піти в себе» надовго.
- Перегрів за довгих сесій. Довгі міркування тримають відеокарту під навантаженням довше звичайного — стежте за температурами на компактних збірках.
FAQ
Який дистилят DeepSeek-R1 обрати для відеокарти на 8 ГБ? Версію 7B (на базі Qwen, краще для української) або 8B (на базі Llama, сильніша в англійській) у кванті Q4_K_M — обидві вміщуються у 8 ГБ. Для україномовних задач беріть 7B. Моделі 14B і більші на 8 ГБ цілком не помістяться.
У чому різниця між DeepSeek-R1 і DeepSeek-V3? R1 — модель, що міркує: перед відповіддю вона виписує ланцюжок думок, що допомагає на математиці, коді та логіці, але повільніше. V3 (і новіша V4) — звичайна швидка модель для повсякденних відповідей без видимих міркувань. Для складних логічних задач беріть R1, для швидкості — V3/V4.
Чи працює цензура DeepSeek, якщо запустити модель локально без інтернету? Так. Цензура зашита в самі ваги моделі, а не в сайт DeepSeek, тому вона проявляється і при повністю офлайн-запуску. Стосується вона переважно політичних тем, пов’язаних із Китаєм; на звичайних задачах не заважає.
Дистилят R1 на 32B — це те саме, що повна R1? Ні. 32B-дистилят — це Qwen2.5, донавчена на міркуваннях R1. Вона сильна на логічних задачах (обходить o1-mini), але це не та сама мережа, що повна R1 на 671 млрд параметрів, і на складних задачах поступається їй.
Чому ollama run deepseek-r1 без розміру завантажує 8B-модель?
Тому що тег latest в Ollama зараз указує на R1-0528-Qwen3-8B — свіжий дистилят на базі Qwen3. Якщо потрібен інший розмір, указуйте його явно, наприклад deepseek-r1:32b.
Чи потрібно давати R1 приклади в промпті для кращого результату? Навпаки. За даними досліджень, few-shot (приклади в запиті) погіршує міркування R1. Найкраще вона працює в режимі zero-shot — коли ви просто чітко формулюєте задачу без зразків.
Скільки місця на диску займуть дистиляти DeepSeek-R1? Залежить від розміру: 7–8B у Q4 — близько 5 ГБ, 14B — 9 ГБ, 32B — 20 ГБ, а 70B — порядку 43 ГБ. Найлегша версія 1.5B — усього близько гігабайта. Якщо хочете тримати кілька розмірів під різні задачі, закладайте 50–80 ГБ вільного місця.













