
Коротко (TL;DR)
Gemma — сімейство відкритих моделей від Google DeepMind, побудоване на тій самій технології, що й хмарний Gemini. Для локального запуску в Gemma репутація «найкращої моделі, що вміщується на одну споживчу відеокарту», і у 2026 році до цього додався ще один вагомий аргумент.
- Коротко (TL;DR)
- Дві генерації Gemma: 3 і 4
- Скільки потрібно заліза: VRAM, кванти і швидкість
- QAT-кванти Google: чому вони кращі за звичайні
- MoE 26B-A4B: швидка, але пам’ять не економить
- Мультимодальність: зображення, OCR та аудіо
- Ліцензія: головна історія Gemma
- Запуск: Ollama, LM Studio, llama.cpp
- Налаштування під себе: контекст, температура і API
- Українська і російська: 140+ мов
- Бенчмарки й арена: де стоїть Gemma 4
- Gemma проти Qwen3, Llama і Mistral
- Ризики й граблі
- FAQ
- Дві генерації. Актуальні обидві: Gemma 3 (розміри 1B, 4B, 12B, 27B) — перевірена база з морем готових квантів, і Gemma 4 (від компактних E2B/E4B до 31B і MoE-варіанта 26B-A4B) — нове покоління квітня 2026 з режимом міркувань і вищими бенчмарками.
- Головна зміна — ліцензія. Gemma 3 ішла під власними умовами Google з правом обмежити використання, а Gemma 4 випущена під вільною Apache 2.0. Це знімає юридичний ризик і робить її безпечною для комерційних продуктів.
- Сильні сторони: мультимодальність (моделі бачать зображення і добре розпізнають текст із фото), офіційні QAT-кванти з економією пам’яті та підтримка 140+ мов, включно з упевненою українською й російською.
Мінімальне залізо: компактні Gemma 4 E2B/E4B запускаються на 6 ГБ відеопам’яті, флагманська 31B у кванті Q4 заходить у 24 ГБ, а з офіційним QAT-квантом — ще економніше. Дані актуальні на 16 червня 2026 року.
Дві генерації Gemma: 3 і 4
На середину 2026 року в ходу обидві лінійки. Розуміти різницю важливо, бо від покоління залежать і можливості, і — що критично — ліцензія.Лінійка Розміри Контекст Мультимодальність Ліцензія Дата Gemma 3 1B, 4B, 12B, 27B 32K (1B) / 128K Зображення (4B+) Gemma Terms of Use березень 2025 Gemma 4 E2B, E4B, 12B, 26B-A4B (MoE), 31B 128K / 256K (12B/26B/31B) Зображення, відео; аудіо — E2B/E4B/12B Apache 2.0 квітень 2026
Gemma 3 лишається відмінним вибором, якщо вам потрібна стабільна модель з величезним числом готових збірок — її 27B-версія свого часу увійшла в топ відкритих моделей під одну карту 24 ГБ. Gemma 4 — це крок уперед: додався режим міркувань (chain-of-thought), зросли бенчмарки, розширилася мультимодальність (тепер і аудіо), а контекст у старших моделей доріс до 256K. Але головний практичний зсув — ліцензія, про яку окрема розмова нижче.
Скільки потрібно заліза: VRAM, кванти і швидкість
Як і інші локальні моделі, Gemma запускають у квантованому вигляді (формат GGUF, ходовий квант Q4). Ось офіційні вимоги Gemma 4 за відеопам’яттю (значення Google з урахуванням ~20% накладних витрат, квант Q4; дані docs на червень 2026):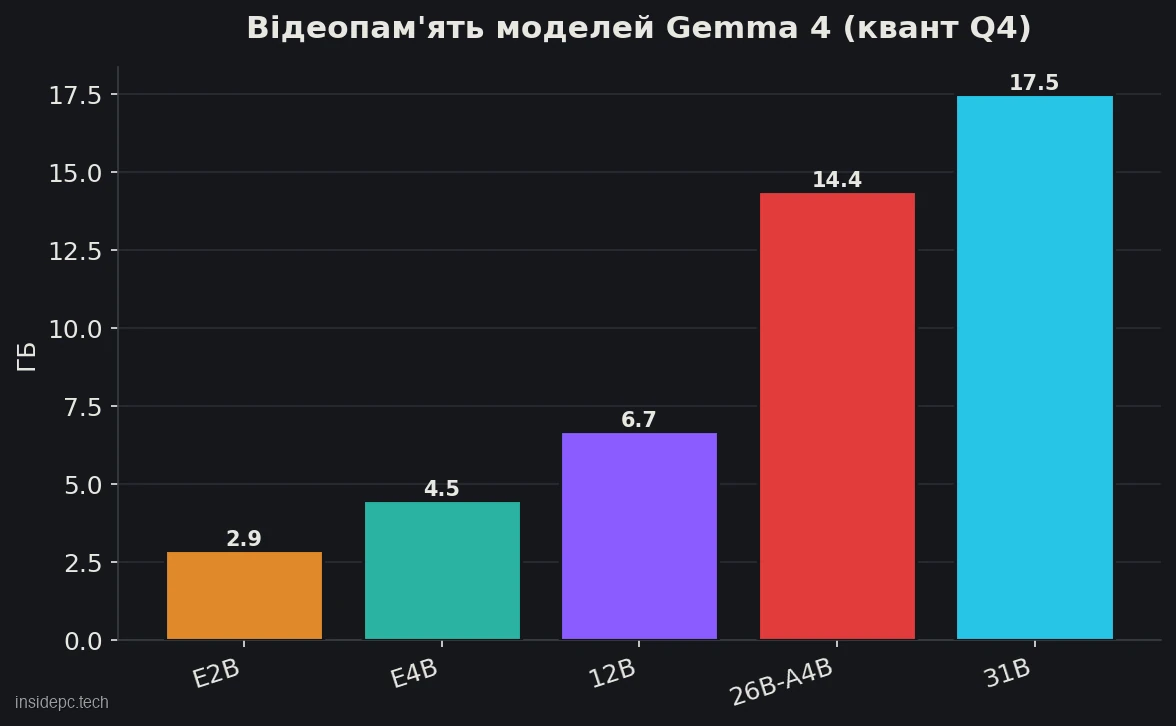
Модель Gemma 4 (Q4) VRAM Комфортне залізо Швидкість (орієнтир) E2B (~2B) ~2,9 ГБ будь-яка карта від 4 ГБ ~15+ tok/s E4B (~4B) ~4,5 ГБ 6–8 ГБ (RTX 3050/3060) ~10+ tok/s і вище 12B ~6,7 ГБ 8–12 ГБ висока 26B-A4B (MoE) ~14,4 ГБ 16 ГБ і вище ~30+ tok/s 31B ~17,5 ГБ 24 ГБ (RTX 3090/4090) до ~140 tok/s (RTX 5090)

Для Gemma 3 орієнтири близькі за розміром: 4B живе на 8 ГБ, 12B — на 12–16 ГБ, а 27B комфортно заходить у 24 ГБ. Важлива поправка, спільна для всіх моделей: до розміру ваг додається пам’ять під контекст (KV-кеш), а в Gemma 4 у режимі міркувань він розростається особливо швидко — про це в розділі про ризики. Цифри швидкості — орієнтир і залежать від заліза, кванта й контексту; свіжі заміри звіряйте на сторінці моделі в каталозі Ollama.
Якщо обираєте відеокарту під локальний ШІ, відштовхуйтеся від обсягу VRAM — докладний розбір у гіді з вибору GPU для ШІ.
QAT-кванти Google: чому вони кращі за звичайні
Це наш information gain — деталь, яку майже не пояснюють українською. Зазвичай модель стискають «постфактум» (квантизація після навчання), і частина якості при цьому втрачається. Google пішла далі й випустила офіційні QAT-кванти (quantization-aware training) — моделі, навчені з урахуванням майбутнього стиснення.
Результат: int4-версія Gemma займає приблизно втричі менше пам’яті, ніж вихідна, але зберігає якість, близьку до повного формату bfloat16. На практиці це означає, що QAT-варіант моделі працює помітно точніше, ніж такий же за розміром звичайний GGUF-квант.
Де взяти: офіційні колекції на Hugging Face — google/gemma-3-qat і google/gemma-4-qat-q4-0. Для llama.cpp шукайте файли із суфіксом -qat-q4_0-gguf. Якщо для вас важливо вичавити максимум якості з обмеженої відеопам’яті — беріть саме QAT-версію, а не перший-ліпший квант.
MoE 26B-A4B: швидка, але пам’ять не економить
У Gemma 4 є модель на архітектурі «суміші експертів» — 26B-A4B. У назві «A4B» означає, що на кожен токен активні лише близько 4 млрд параметрів із 26 млрд. Це робить її швидкою (порядку 30+ токенів/с) і за якістю близькою до флагманської 31B — приблизно 97% від неї.
Але тут криється типова пастка для новачка. «Активних 4B» не значить «потрібно 4 ГБ». У пам’ять вантажаться всі 26 млрд ваг — це близько 14,4 ГБ у кванті Q4. MoE економить обчислення й тим самим швидкість, але не відеопам’ять: щоб запустити 26B-A4B, потрібна карта від 16 ГБ, а не 8. Якщо читали «4B active» і розраховували на свою 8-гігабайтну карту — на жаль, не поміститься.
Мультимодальність: зображення, OCR та аудіо
Одна з найсильніших сторін Gemma — робота не лише з текстом. Моделі Gemma 3 від 4B і вище, а також Gemma 4, уміють бачити зображення: опишуть картинку, розберуть діаграму, витягнуть текст із фотографії документа. Gemma 4 додала роботу з відео, а компактні E2B/E4B (і 12B) — ще й з аудіо.
Особливо цінний для практики сценарій — локальний OCR: розпізнавання тексту з фото й сканів. У спільноті r/LocalLLaMA Gemma регулярно називають однією з найкращих відкритих моделей для цієї задачі. Головний плюс перед хмарними сервісами — приватність: скани паспортів, договорів і медичних документів не покидають ваш комп’ютер.
Запустити мультимодальну модель просто: в Ollama і LM Studio достатньо прикріпити зображення до запиту — модель сама зрозуміє, що з ним працювати. Урахуйте тільки, що обробка картинки вимагає додаткової відеопам’яті понад розмір самої моделі.
Ліцензія: головна історія Gemma
Тут — ключовий сюжет, який більшість оглядів проминає, а для нашої аудиторії він найпрактичніший.
Gemma 3 поширювалася під власними умовами Google — Gemma Terms of Use. Це не відкрита ліцензія в повному сенсі: Google лишала за собою право дистанційно обмежувати використання моделі й накладала низку заборон на сценарії застосування. Для пет-проєкту неважливо, але для бізнесу це був юридичний ризик — на нього прямо звертали увагу профільні видання при виході Gemma 3.
Gemma 4 випущена під Apache 2.0 — однією з найвільніших ліцензій. Жодних порогів, права на дистанційне обмеження й заборон на комерцію: модель можна вбудовувати в продукти, модифікувати й поширювати вільно.Модель Ліцензія Комерція Особливості Gemma 3 Gemma Terms of Use З обмеженнями Google вправі обмежити використання Gemma 4 Apache 2.0 Вільно Без порогів і обмежень Llama 4 Llama Community До 700 млн MAU Заборона вчити інші моделі
Висновок простий: якщо будуєте комерційний продукт, беріть Gemma 4 — з її Apache 2.0 ви юридично чисті. На тлі Gemma 3 і Llama це серйозна перевага.
Запуск: Ollama, LM Studio, llama.cpp
Найпростіший шлях — Ollama. Команди (перевірено за каталогом Ollama, червень 2026):
ollama run gemma3:4b # легка, 8 ГБ, мультимодальна
ollama run gemma3:12b # середній клас
ollama run gemma3:27b # флагман Gemma 3 на 24 ГБ
ollama run gemma4:e4b # компактна Gemma 4, 6 ГБ
ollama run gemma4:12b # Gemma 4 середній клас
ollama run gemma4 # флагман 31B (~17,5 ГБ, карта 24 ГБ); для 8 ГБ беріть gemma4:e4b
Ollama одразу піднімає локальний API, сумісний із форматом OpenAI, — зручно для підключення до редакторів коду й ботів.
LM Studio — графічний інтерфейс із каталогом моделей і зручним переглядом, зокрема для мультимодальних запитів. Хороший вибір, якщо не любите термінал.
llama.cpp напряму — для максимальної продуктивності й тонкого налаштування; саме тут найзручніше підключати офіційні QAT-кванти.
Важливе налаштування для Gemma 4: режим міркувань (thinking mode) увімкнений за замовчуванням і для простих задач лише сповільнює відповідь та витрачає відеопам’ять. Якщо вам потрібен швидкий чат або сумаризація, вимкніть його — в Ollama це робиться параметром think=false. Для складних логічних задач, навпаки, залиште ввімкненим.
Налаштування під себе: контекст, температура і API
Кілька параметрів, які варто підлаштувати під свої задачі.
- Довжина контексту (num_ctx). Старші Gemma 4 тримають до 256K токенів, але Ollama за замовчуванням виділяє менше. Для довгих документів піднімайте
num_ctxвручну — пам’ятаючи, що контекст витрачає відеопам’ять (KV-кеш), особливо при ввімкнених міркуваннях. - Температура. Загальноприйняті орієнтири спільноти: для коду та фактичних задач — 0.1–0.3, для вільного тексту — близько 0.7.
- Системний промпт. Допомагає закріпити мову й стиль відповіді, що особливо корисно для української та російської. Із заувагою: Gemma 4 іноді слабко реагує на системні інструкції (див. розділ ризиків).
- Режим міркувань — головний перемикач швидкості в Gemma 4; як ним керувати, описано в розділі про запуск вище.
Режим API. Ollama піднімає сервер на localhost:11434, сумісний із форматом OpenAI: підключайте редактори коду, ботів і власні скрипти, а для мультимодальних задач передавайте зображення прямо в запиті. Усі дані лишаються на вашому комп’ютері — у цьому й сенс локального запуску: приватність плюс відсутність плати за токени.
Українська і російська: 140+ мов
Gemma з самого початку багатомовна: і третє, і четверте покоління офіційно підтримують понад 140 мов, а під капотом використовують той самий токенізатор на 262 тисячі токенів, що й хмарний Gemini. Це виводить Gemma в число сильних відкритих моделей для української та російської — вона грамотно пише, перекладає й розуміє контекст цими мовами.
У прямому порівнянні найкращим відкритим вибором для слов’янських мов частіше називають Qwen3, але Gemma йде слідом і нерідко виграє там, де потрібна мультимодальність (наприклад, розібрати україномовний документ по фото). Практична порада та сама, що й для інших моделей: задавайте системний промпт із явним указанням мови — це стабілізує відповіді.
Бенчмарки й арена: де стоїть Gemma 4
За незалежними замірами Gemma 4 помітно додала. На відкритій арені LMArena, де моделі порівнюють наосліп живі користувачі, флагманська Gemma 4 31B трималася в районі 40–45-го місця з рейтингом близько 1451 (за даними LMArena на середину червня 2026 року) — високий результат для моделі, яку можна запустити на домашній карті 24 ГБ.
За профільними бенчмарками (за даними вторинних оглядів, квітень 2026): близько 89% на математичному AIME 2026, рейтинг Codeforces ELO порядку 2150 з програмування і 84% на науковому GPQA. Цифри варто сприймати як орієнтир — офіційні результати звіряйте в картці моделі, а арена швидко змінюється, тож перед важливим вибором перевірте поточну позицію.
Практичний висновок із бенчмарків: Gemma 4 особливо сильна в коді та математиці, що робить її хорошим локальним помічником розробника.
Gemma проти Qwen3, Llama і Mistral
«Найкращої моделі взагалі» не буває. Ось чесне порівняння Gemma з трьома головними суперниками в локальному сегменті (станом на червень 2026).Критерій Gemma 4 Qwen3 Llama Mistral Small Українська/російська Добре Найкращий Середньо Середньо Мультимодальність Сильна (фото, відео, аудіо) Є варіанти Vision Обмежена Ліцензія Apache 2.0 Apache 2.0 Community Apache 2.0 Під одну карту 24 ГБ Відмінно (31B/27B) Добре (32B) 70B лише з offload Добре Код і математика Дуже добре Дуже добре Добре Добре QAT-кванти Офіційні Немає Немає Немає
Де Gemma об’єктивно попереду: мультимодальність, офіційні QAT-кванти і якість на одній споживчій карті. Де варто обрати інакше: для суто текстових задач слов’янськими мовами Qwen3 трохи сильніший, а для агентних сценаріїв (виклик інструментів) користувачі нерідко віддають перевагу Qwen.
Ризики й граблі
- MoE не економить відеопам’ять. 26B-A4B швидка, але вантажить усі 26 млрд ваг (~14,4 ГБ) — на 8 ГБ не запуститься, попри «4B active».
- Режим міркувань їсть пам’ять і час. У Gemma 4 thinking mode за замовчуванням увімкнений; на довгому контексті KV-кеш здатен зайняти всю відеопам’ять — на це скаржаться користувачі r/LocalLLaMA. Для простих задач вимикайте його параметром
think=false. - Слабка реакція на системний промпт. За повідомленнями спільноти (r/LocalLLaMA, червень 2026), Gemma 4 26B-A4B іноді ігнорує системні промпти й неохоче викликає інструменти — враховуйте при побудові агентів.
- Ліцензія Gemma 3. Якщо берете саме третє покоління для комерції, пам’ятайте про Gemma Terms of Use з правом Google обмежити використання. Для бізнесу безпечніша Gemma 4 на Apache 2.0.
- Vision вимагає запасу пам’яті. Обробка зображень додає навантаження понад розмір моделі — закладайте відеопам’ять із запасом.
- Перегрів за довгих сесій. Важкі моделі надовго навантажують відеокарту — стежте за температурами на компактних збірках.
FAQ
Яку Gemma обрати для відеокарти на 8 ГБ? Gemma 4 E4B (~4,5 ГБ) або 12B (~6,7 ГБ у Q4), або Gemma 3 4B — усі вміщуються у 8 ГБ і підтримують зображення. Якщо важлива максимальна якість у цій пам’яті, беріть офіційний QAT-квант. Моделі 26B-A4B і 31B на 8 ГБ не помістяться.
Чим Gemma 4 краща за Gemma 3? Головне — ліцензія Apache 2.0 замість обмежувальних умов Gemma 3, що знімає ризики для комерції. Плюс режим міркувань, вищі бенчмарки в коді та математиці, розширена мультимодальність (додалося аудіо) і контекст до 256K у старших моделей.
Що таке QAT-кванти і навіщо вони потрібні? Це офіційні стиснені версії Gemma, навчені з урахуванням квантизації. Вони займають приблизно втричі менше пам’яті, ніж вихідна модель, але зберігають якість, близьку до повного формату. Простіше кажучи — кращий результат за тієї самої відеопам’яті, ніж у звичайного GGUF-кванта.
Чи може Gemma розпізнавати текст на фото локально? Так. Мультимодальні версії Gemma 3 (від 4B) і Gemma 4 добре справляються з OCR — розпізнають текст зі сканів і фотографій документів прямо на вашому комп’ютері, без надсилання даних у хмару. Це один із найпопулярніших локальних сценаріїв Gemma.
Як вимкнути «міркування» Gemma 4, щоб вона відповідала швидше?
В Ollama додайте параметр think=false — модель перестане витрачати час і пам’ять на покрокові міркування й відповідатиме одразу. Для простого чату й сумаризації це помітно прискорює роботу; для складних логічних задач режим краще повернути.
Gemma чи Qwen3 — що брати для української мови? Для суто текстових задач слов’янськими мовами Qwen3 зазвичай трохи сильніший, але Gemma йде слідом і виграє, коли потрібна мультимодальність — наприклад, розібрати україномовний документ по фотографії. Обидві підтримують українську й російську офіційно. Для агентних сценаріїв (виклик інструментів) користувачі нерідко віддають перевагу Qwen3 — Gemma 4 іноді примхлива із системними промптами.













