Коротко (TL;DR)
Qwen Coder — специализированная под программирование линейка моделей от Alibaba, и на сегодня это, пожалуй, лучший открытый кодер для локального запуска. Идея простая: получить помощника уровня GitHub Copilot или Cursor, но на своём железе — с полной приватностью кода и без подписки.
- Коротко (TL;DR)
- Линейка Qwen Coder: от 2.5 до Next
- Сколько нужно железа: VRAM, кванты и скорость
- Запуск: команды Ollama
- Fill-in-the-Middle: как работает автодополнение
- Подключение к редактору: Continue, Cline и другие
- Настройка под себя: контекст, температура, режимы
- Контекст для целого репозитория
- Агентный кодинг: Qwen Code CLI
- Бенчмарки: где Qwen Coder силён — и честная оговорка
- Qwen Coder против DeepSeek-Coder, Codestral и Gemma
- Риски и грабли
- FAQ
- Линейка под любое железо. Qwen2.5-Coder идёт в размерах от 0,5B до 32B: маленькие — для мгновенного автодополнения на видеокарте 8 ГБ, старшая 32B — для серьёзных задач на карте 24 ГБ. Есть и более новые Qwen3-Coder (вплоть до MoE-вариантов).
- Уровень близко к топу. Qwen2.5-Coder-32B по практическому тесту Aider набирает около 72,9% — это уровень GPT-4o в коде. Для модели, которую можно запустить дома, результат впечатляющий.
- Реальная замена облаку. Через расширения вроде Continue.dev модель подключается прямо в VS Code и работает как автодополнение и чат-ассистент — но локально, без отправки кода наружу. Лицензия — свободная Apache 2.0.
Но без иллюзий: в независимых тестах Qwen Coder не всегда выигрывает у конкурентов (об этом честно ниже), а режим «размышлений» для автодополнения скорее мешает. Данные актуальны на 16 июня 2026 года.
Линейка Qwen Coder: от 2.5 до Next
За «Qwen Coder» стоит несколько поколений. Разобраться в них важно, чтобы выбрать под своё железо и задачу.Линейка Размеры Контекст Особенность Дата Qwen2.5-Coder 0,5B / 1,5B / 3B / 7B / 14B / 32B 32K (до 128K) Рабочая лошадка, FIM-автодополнение ноябрь 2024 Qwen3-Coder-480B 480B / 35B активных (MoE) 256K (до 1M) Флагман для агентного кодинга, сервер июль 2025 Qwen3-Coder-30B 30B (MoE) 256K Версия для одной карты 24 ГБ 2025–2026 Qwen3-Coder-Next 80B / 3B активных (MoE) большой Эффективный MoE для мощного ПК февраль 2026
Для большинства домашних задач актуальны Qwen2.5-Coder (проверенная база с морем готовых квантов) и Qwen3-Coder-30B (новее, заходит на 24 ГБ). Гигантская 480B — для серверов и агентных пайплайнов, а Qwen3-Coder-Next интересна тем, что при 80 млрд параметров активирует лишь около 3 млрд, то есть «думает» быстро. Если вам нужен не кодер, а универсальная модель Qwen, у нас есть отдельный обзор Qwen3 — здесь же речь только про код.

Сколько нужно железа: VRAM, кванты и скорость
Это ядро статьи. Под кодинг важно различать три сценария: автодополнение (быстрые подсказки прямо при наборе — нужна лёгкая модель), чат-ассистент (вопросы по коду — модель посерьёзнее) и агент (модель сама пишет и правит файлы — нужна самая мощная).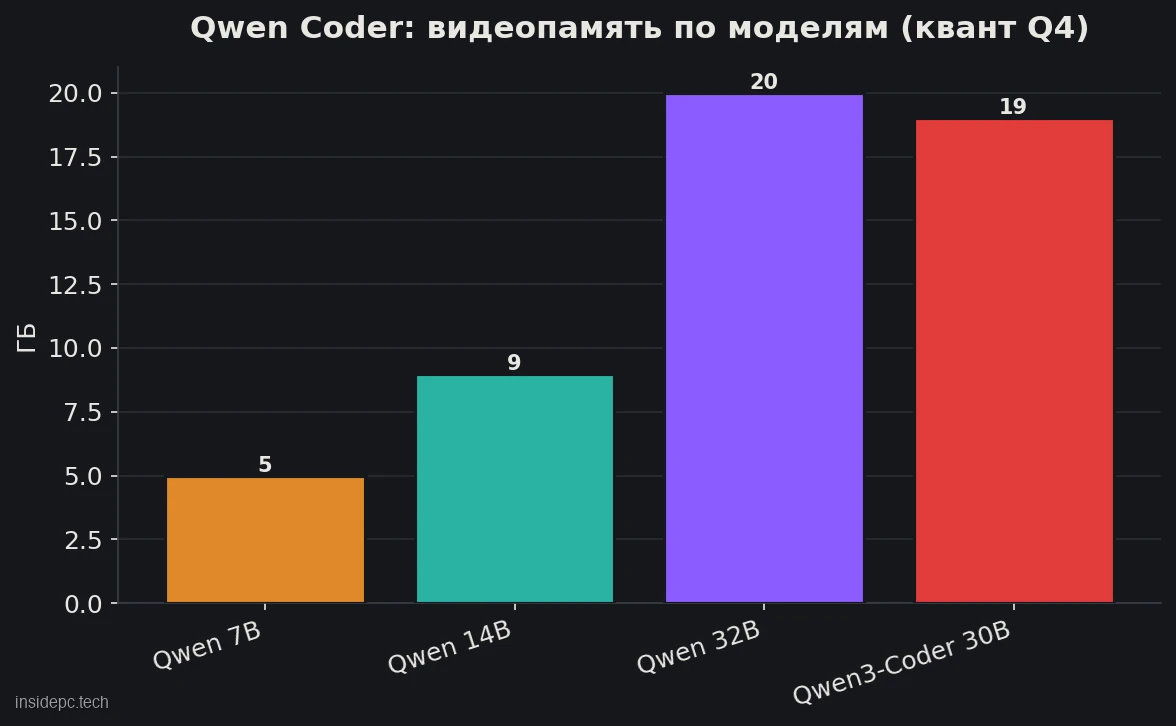
Модель (Q4) VRAM Железо Для чего Qwen2.5-Coder 7B ~5 ГБ RTX 3060 8 ГБ Автодополнение, быстрый чат Qwen2.5-Coder 14B ~8,7 ГБ (Q4) / ~14,7 ГБ (Q8) 12–16 ГБ Чат-ассистент, сложнее задачи Qwen2.5-Coder 32B ~20 ГБ RTX 3090/4090 (24 ГБ) Максимум качества, агент Qwen3-Coder 30B ~19 ГБ RTX 3090/4090 (24 ГБ) Агентный кодинг, 256K контекст

Практический ориентир по скорости: старшая 32B на RTX 4090 выдаёт около 20–40 токенов/с в чате, а 14B на карте RTX 4080 в высоком кванте — порядка 40–55 (по замерам сообщества, конец 2025). Для автодополнения скорость критична — там берут лёгкие 7B, чтобы подсказка появлялась мгновенно; для вдумчивых задач можно потерпеть и более медленную, но умную 32B.
Важная поправка про память: к размеру весов добавляется контекст (KV-кэш), а у кодеров он особенно прожорлив — модели часто скармливают большие куски кода. Если хотите работать с длинным контекстом (целые файлы и репозитории), закладывайте видеопамять с запасом.
Если выбираете видеокарту под локальный ИИ, отталкивайтесь от объёма VRAM — подробный разбор в гиде по выбору GPU для ИИ.
Запуск: команды Ollama
Самый простой путь — Ollama (актуальная версия ≥0.5, проверено по каталогу Ollama, июнь 2026):
ollama run qwen2.5-coder:7b # автодополнение и быстрый чат, 8 ГБ
ollama run qwen2.5-coder:14b # чат-ассистент, 12–16 ГБ
ollama run qwen2.5-coder:32b # максимум качества, 24 ГБ
ollama run qwen3-coder:30b # агентный кодинг, 256K контекст
Для автодополнения в редакторе скачивайте именно базовую версию с поддержкой FIM (теги вида qwen2.5-coder:7b-base), а для чата и агента — instruct-вариант (по умолчанию). Ollama сразу поднимает локальный API на localhost:11434, совместимый с форматом OpenAI, — именно к нему подключаются расширения редакторов.
LM Studio — графическая альтернатива с каталогом моделей; удобно, если не хотите работать в терминале. llama.cpp и vLLM — для серверных сценариев и раздачи модели нескольким разработчикам в команде.
Fill-in-the-Middle: как работает автодополнение
Главная «фишка» кодеров, которой нет у обычных чат-моделей, — Fill-in-the-Middle (FIM), дополнение в середине файла. Когда вы пишете код, курсор стоит посередине: сверху уже написанное, снизу — то, что будет дальше. Обычная модель умеет продолжать текст, а FIM-модель видит и то, что до, и то, что после курсора, и аккуратно вставляет нужное в разрыв.
Технически это работает через специальные маркеры (<|fim_prefix|>, <|fim_suffix|>, <|fim_middle|>), которыми редактор оборачивает код вокруг курсора. Qwen Coder обучен понимать этот формат — именно поэтому он даёт осмысленные подсказки, а не просто дописывает строку «вслепую».
Тонкость, о которой стоит знать: для автодополнения берут базовую (base) версию модели, а не instruct-вариант для чата — base заточена именно под FIM. И отдельный нюанс для свежих Qwen3-Coder: при настройке автодополнения через некоторые расширения FIM-токены приходится оборачивать в чат-формат, иначе подсказки не работают. Если столкнулись — это известная особенность, а не поломка.
Подключение к редактору: Continue, Cline и другие
Локальный кодер бесполезен без интеграции в редактор. Хорошая новость: подключить Qwen Coder к VS Code несложно, и вариантов много.
- Continue.dev — самое популярное расширение для VS Code и JetBrains. Подключается к локальному серверу Ollama, даёт и автодополнение, и чат по коду. Оптимальная точка входа.
- Cline — расширение для агентного кодинга: модель сама читает и правит файлы проекта. Хорошо раскрывает потенциал Qwen3-Coder.
- Cursor и Zed — редакторы со встроенным ИИ, которые можно переключить на локальную модель через OpenAI-совместимый API Ollama.
- Qwen Code CLI — официальный консольный агент от Alibaba (аналог Claude Code и aider), заточенный под Qwen3-Coder; работает и с локальной моделью.
Схема одинаковая: запускаете модель в Ollama, она поднимает локальный сервер на localhost:11434, а расширение указываете на этот адрес. Дальше код-ассистент работает целиком на вашем железе — ни строчки не уходит в облако.
На практике в Continue.dev это пара строк в файле настроек: указываете провайдера ollama и имя модели — например, qwen2.5-coder:7b-base для автодополнения и qwen2.5-coder:32b для чата. После этого подсказки появляются прямо при наборе, а по горячей клавише открывается чат с моделью по выделенному коду. Никаких ключей API и оплаты — всё локально.
Настройка под себя: контекст, температура, режимы
Несколько параметров под код.
- Температура. Для кода ставьте низкую (0.1–0.2): программирование требует точности, а не «творчества». Высокая температура чаще ведёт к выдуманным API и ошибкам.
- Длина контекста (num_ctx). Для автодополнения хватает небольшого окна (несколько тысяч токенов вокруг курсора) — это быстрее и экономит память. Для работы с большими файлами и репозиторием поднимайте
num_ctx, помня про расход видеопамяти. - Две модели под две задачи. Оптимальная схема — лёгкая base-модель (7B) на автодополнение ради скорости и мощная instruct (32B) на чат и сложные правки. Continue.dev позволяет задать их по отдельности.
- Без thinking для рутины. Режим размышлений у новых версий полезен для разбора сложного алгоритма, но для автодополнения и следования инструкциям его лучше выключать.
Локальный запуск даёт и неочевидный плюс: код, над которым работает модель, не покидает компьютер — это важно для коммерческих и закрытых проектов, где отправлять исходники в облачный сервис нельзя по правилам.
Контекст для целого репозитория
Один из аргументов в пользу свежих Qwen3-Coder — большое окно контекста: 256K токенов нативно, а с расширением (extrapolation) — вплоть до миллиона. На практике это значит, что модели можно «показать» не один файл, а существенную часть проекта целиком: она увидит, как устроены соседние модули, какие есть функции и стили, и даст подсказку с учётом всего этого.
Для рутинного автодополнения столько не нужно — там хватает нескольких тысяч токенов вокруг курсора. Но для агентных задач (отрефакторить модуль, найти баг через несколько файлов, добавить фичу по аналогии с существующей) большой контекст — серьёзное преимущество. Платой, как обычно, становится видеопамять: длинный контекст её активно расходует.
Агентный кодинг: Qwen Code CLI
Отдельное направление, под которое заточены Qwen3-Coder, — агентный кодинг, когда модель не просто подсказывает, а сама выполняет задачу: читает файлы, пишет код, запускает команды, исправляет ошибки. Для этого Alibaba выпустила Qwen Code CLI — консольный инструмент в духе Claude Code, который умеет работать в том числе с локальной моделью через Ollama.
Сценарий выглядит так: вы формулируете задачу словами («добавь обработку ошибок в этот модуль»), а агент сам разбирает проект, вносит правки и показывает результат. Для домашнего железа это реалистично с Qwen3-Coder-30B на карте 24 ГБ или с эффективной Qwen3-Coder-Next на мощном ПК. Полноценная 480B-версия (35 млрд активных при MoE-инференсе) для такого режима сильнее, но требует сервера. Важно держать в голове: агент действует автономно, поэтому работайте в системе контроля версий (git) и проверяйте, что он сделал.
Для тех, кто уже знаком с Claude Code или aider, переход на Qwen Code CLI с локальной моделью будет интуитивным: те же принципы (агент видит проект, предлагает изменения, применяет их по подтверждению), но без оплаты за токены и с кодом, который остаётся на вашей машине. Это особенно ценно для пет-проектов и экспериментов, где гонять платный облачный агент по мелочам невыгодно.
Бенчмарки: где Qwen Coder силён — и честная оговорка
По бенчмаркам Qwen Coder выглядит отлично. Самый практичный показатель — тест Aider, который оценивает реальное редактирование кода: Qwen2.5-Coder-32B берёт около 72,9%, что соответствует уровню GPT-4o. Для открытой модели на домашней карте это сильный результат. Для сравнения, на строгом SWE-bench Verified (реальные баги из GitHub) средняя 14B-версия берёт около 27% — это показывает, насколько такие задачи сложнее учебных. А смежная модель той же команды, Qwen3.6 Plus, достигает около 78,8% на SWE-bench Verified (по данным лидербордов, апрель 2026) — планка растёт быстро.
Но здесь — обязательная честная оговорка, которую большинство обзоров опускает. Во-первых, цифры бенчмарков сильно зависят от методики: у одной и той же 32B результат HumanEval базовой версии около 66%, instruct — за 90%, Aider — 73%. Это не противоречие, а разные тесты и разные модели; ориентируйтесь на Aider как на самый «рабочий».
Во-вторых, реальные тесты не всегда подтверждают лидерство. В независимом разборе на Habr (июнь 2026) на видеокарте RTX 5070 Ti с 16 ГБ Gemma 4 обошла Qwen3-Coder-30B в практических задачах программирования. Там же выяснилось, что включённый режим «размышлений» (thinking) ухудшал следование инструкциям. Вывод трезвый: Qwen Coder — один из лучших, но не безусловный чемпион на любом железе; проверяйте на своих задачах и не включайте thinking для автодополнения.
И ещё важный для практики вывод: для большинства повседневных задач — автодополнение, написание функций, объяснение чужого кода, отладка — разрыв между топовыми открытыми кодерами и облачными моделями уже невелик. Платите вы при этом не подпиской, а один раз за железо, и код не покидает машину. Именно поэтому локальный кодер из «игрушки энтузиаста» превратился в реальный рабочий инструмент.
Qwen Coder против DeepSeek-Coder, Codestral и Gemma
«Лучшего кодера вообще» не существует — многое зависит от языка, задачи и железа. Вот ориентир по главным открытым соперникам (по состоянию на июнь 2026).Критерий Qwen Coder DeepSeek-Coder Codestral (Mistral) Gemma 4 Качество кода Очень высокое Высокое Высокое Высокое FIM-автодополнение Да Да Да (заточен) Частично Размеры под дом 0,5B–32B 1,3B–33B 22B 4B–31B Контекст до 256K–1M большой 32K+ до 256K Агентный режим Да (Qwen Code CLI) Ограниченно Ограниченно Ограниченно Лицензия Apache 2.0 MIT/своя своя (Mistral) Apache 2.0
Где Qwen Coder объективно впереди: широта линейки, большой контекст и агентный инструментарий. Где стоит присмотреться к альтернативам: Codestral традиционно силён именно в автодополнении, а универсальная Gemma 4, как показал тест выше, в отдельных задачах способна обойти специализированный кодер.
Риски и грабли
- Режим «размышлений» мешает коду. Для автодополнения и чёткого следования инструкциям thinking лучше выключать — он замедляет ответ и, по тестам, ухудшает результат на coding-задачах.
- MXFP4-кванты на видеокартах Blackwell (RTX 50xx). Сообщество (Habr, 2026) сообщает об аномалиях вычислений в некоторых MXFP4-сборках Qwen — команда Unsloth даже убирала их из своих пакетов. Если у вас RTX 50xx, берите проверенные кванты (Q4_K_M и подобные) и тестируйте стабильность.
- Base или instruct — не перепутайте. Для автодополнения нужна базовая (FIM) версия, для чата — instruct. Неправильный выбор даёт «странные» подсказки.
- Контекст ест память. Большое окно — это удобно, но видеопамять расходуется быстро; на длинных контекстах закладывайте запас VRAM.
- Происхождение и цепочка поставок. Qwen — модель Alibaba; для государственных и особо чувствительных сред это соображение стоит учитывать. И общий совет: скачивайте веса только из официальных репозиториев (на Hugging Face в прошлом находили вредоносные «модели»-подделки).
- Знания ограничены датой обучения. Свежие библиотеки и API модель может не знать — для актуального кода проверяйте подсказки и подключайте документацию.
- Перегрев при долгих сессиях. Кодинг-агенты надолго нагружают видеокарту — следите за температурами на компактных сборках.
FAQ
Какую модель Qwen Coder выбрать для видеокарты на 8 ГБ? Qwen2.5-Coder 7B в кванте Q4 — она занимает около 5 ГБ и отлично подходит для автодополнения и быстрого чата по коду. Модели 14B и 32B на 8 ГБ целиком не поместятся; для них нужны 12–16 и 24 ГБ соответственно.
Может ли Qwen Coder заменить GitHub Copilot? Для автодополнения и чата по коду — во многом да: через Continue.dev в VS Code локальный Qwen Coder даёт похожий опыт, но бесплатно и без отправки кода в облако. Полностью повторить облачные агентные функции сложнее, но для приватной работы это реальная альтернатива.
Чем base-версия отличается от instruct? Базовая (base) версия заточена под Fill-in-the-Middle — автодополнение в середине файла, и именно её используют расширения для подсказок. Instruct-версия обучена вести диалог и выполнять инструкции — её берут для чата и агентных задач. Для автодополнения ставьте base, для общения — instruct.
Qwen Coder лучше DeepSeek-Coder и Gemma? По бенчмаркам Qwen Coder — в числе лидеров, но «безусловно лучший» сказать нельзя. В независимом тесте на 16 ГБ VRAM универсальная Gemma 4 обошла Qwen3-Coder-30B в реальных задачах. Выбор зависит от языка, задачи и железа — стоит протестировать кандидатов на своих типовых задачах.
Нужно ли включать режим «размышлений» для кода? Для автодополнения — нет, его лучше выключить: thinking замедляет ответ и, по тестам, ухудшает следование инструкциям в coding-задачах. Для сложного разбора алгоритма он может помочь, но для повседневной работы с кодом держите его выключенным.
Сколько места на диске займёт Qwen Coder? Зависит от модели: 7B в Q4 — около 5 ГБ, 14B — 9 ГБ, 32B и Qwen3-Coder-30B — порядка 19–20 ГБ. Если держите отдельно base-версию для автодополнения и instruct для чата, закладывайте 50–80 ГБ свободного места.
Qwen2.5-Coder или Qwen3-Coder — что выбрать? Qwen2.5-Coder — проверенная база с огромным числом готовых квантов и размеров под любое железо (от 0,5B до 32B), отлично подходит для автодополнения и чата. Qwen3-Coder новее, заточен под агентный кодинг и большой контекст (256K), но варианты крупнее. Для повседневной работы в редакторе берите Qwen2.5-Coder, для агентных задач — Qwen3-Coder-30B.
Работает ли Qwen Coder с кириллицей в коде и комментариях? Да — модель понимает русские и украинские комментарии и описания задач, хотя сам код и идентификаторы, как принято, на английском. Для постановки задачи на русском («напиши функцию, которая…») Qwen Coder подходит хорошо: общая линейка Qwen сильна в мультиязычности.