



Коротко (TL;DR)
Если в 2026 году спросить в сообществе r/LocalLLaMA, «что поставить локально», в ответе почти наверняка будет Qwen3 от Alibaba. За полтора года это семейство тихо стало выбором по умолчанию — и не из-за маркетинга, а из-за трёх конкретных вещей, которые сошлись в одной модели.
- Коротко (TL;DR)
- Почему Qwen3 — выбор по умолчанию в 2026
- Семейство Qwen3: кто есть кто
- Thinking и Non-Thinking: два режима в одной модели
- Сколько нужно железа: VRAM, кванты и скорость
- Dense 32B или MoE 30B-A3B: что выбрать
- Apache 2.0 против Llama Community License
- Русский и украинский: где Qwen3 впереди
- Запуск: Ollama, LM Studio, llama.cpp, vLLM
- Настройка под себя: контекст, рассуждения и режим API
- Qwen3 против Llama, Gemma и Mistral
- Риски и грабли: цензура и не только
- FAQ
- Свободная лицензия Apache 2.0. В отличие от Llama, Qwen3 можно встраивать в коммерческий продукт без порогов по числу пользователей и без особых ограничений. Это снимает юридическую головную боль.
- Русский и украинский — родные. Qwen3 официально обучен на 119 языках, и оба наших языка явно перечислены в списке. По качеству русского Qwen3 считается лучшим среди открытых моделей — это его сильная сторона для нашей аудитории.
- Два режима в одной модели. Qwen3 умеет «думать» пошагово для сложных задач и отвечать мгновенно для простых — переключается одной командой. Не нужно держать отдельно «быструю» и «умную» версии.
Минимальное железо: модель Qwen3 8B в кванте Q4 умещается в 8 ГБ видеопамяти, а флагманские для дома 32B и MoE-вариант 30B-A3B заходят в 24 ГБ. Главный честный минус — политическая цензура в готовых (instruct) версиях: модель уходит от острых тем про Китай. Разберём, когда это мешает, а когда нет.
Данные в статье актуальны на 16 июня 2026 года.
Почему Qwen3 — выбор по умолчанию в 2026
Сильных открытых моделей много, но Qwen3 собрал редкую комбинацию преимуществ, ни одно из которых по отдельности не уникально, а вместе они и дают «эффект дефолта».
Во-первых, широкая и логичная линейка. От 0,6 млрд параметров для телефона до 235 млрд для сервера — под любое железо есть свой размер, и все они обучены по одному рецепту, так что переход между ними предсказуем.

Во-вторых, сильные результаты в коде и математике. Флагман Qwen3-235B-A22B набирает 85,7 на математическом бенчмарке AIME’24 и 70,7 на LiveCodeBench v5 (по техническому отчёту Qwen, май 2025). Важная оговорка: эти цифры — для самой большой модели в режиме рассуждений, и локально такую не запустить (о причинах ниже). Но и средние модели Qwen3 в своём весе показывают результаты на уровне или выше конкурентов.
В-третьих, зрелая экосистема: на платформе Ollama семейство набрало 30,5 млн загрузок (по данным каталога на июнь 2026), а это значит готовые кванты, инструкции и поддержку во всех популярных бэкендах.
Дальше — по порядку: из чего состоит семейство, как работают режимы рассуждений, что нужно по железу и где подводные камни.
Семейство Qwen3: кто есть кто
Qwen3 вышел 29 апреля 2025 года и включает восемь открытых моделей — шесть «плотных» (dense) и две на архитектуре «смеси экспертов» (MoE). Предобучение шло примерно на 36 триллионах токенов — почти вдвое больше, чем у прошлого поколения Qwen2.5.Модель Тип Параметры Контекст Под какое железо Qwen3 0.6B / 1.7B dense 0,6 / 1,7 млрд 32K Телефон, слабый ПК, CPU Qwen3 4B dense 4 млрд 128K Видеокарта от 6–8 ГБ Qwen3 8B dense 8 млрд 128K 8 ГБ VRAM — рабочая лошадка Qwen3 14B dense 14 млрд 128K 12–16 ГБ VRAM Qwen3 30B-A3B MoE 30 млрд (3 активных) 128K 24 ГБ VRAM, быстрая Qwen3 32B dense 32 млрд 128K 24 ГБ VRAM, максимум качества Qwen3 235B-A22B MoE 235 млрд (22 активных) 128K Сервер, не для дома
У моделей MoE в скобках — число активных параметров: на каждый токен включается лишь часть сети (8 экспертов из 128). Это делает их быстрее «плотных» моделей того же размера, но в память по-прежнему грузятся все веса — об этом подробнее в разделе про железо.
Отдельно стоит знать про эволюцию линейки, иначе легко запутаться. После оригинального Qwen3 (апрель 2025) вышли Qwen3-Next (сентябрь 2025), затем Qwen3.5 (февраль 2026) и Qwen3.6 (апрель 2026). Новые поколения расширили число языков до 201 и добавили мультимодальность. Если вам нужен максимум свежести и работа с изображениями — смотрите в сторону Qwen3.5/3.6; если нужна проверенная база с тоннами готовых квантов — оригинальный Qwen3 по-прежнему отличный выбор. Лицензия Apache 2.0 у всех поколений одинаковая.

Thinking и Non-Thinking: два режима в одной модели
Главная архитектурная фишка Qwen3 — гибридный режим рассуждений. Одна и та же модель умеет работать в двух режимах:
- Thinking Mode (режим размышления) — модель сначала пошагово рассуждает (вывод обёрнут в теги
<think></think>), а потом даёт ответ. Медленнее, но заметно точнее на математике, коде и логике. - Non-Thinking Mode (быстрый режим) — мгновенный ответ без видимых рассуждений. Подходит для простых вопросов, чата, переформулирования.
Переключение — без перезагрузки модели. В коде это параметр enable_thinking=True/False, а прямо в диалоге можно дописать к сообщению команду /think или /no_think. То есть для черновой переписки вы держите модель в быстром режиме, а на сложной задаче включаете рассуждения одной командой.
Практическая тонкость, о которой молчат туториалы: по данным исследования (arXiv, октябрь 2025), Qwen3-8B в режиме /no_think всё равно иногда генерирует внутренние рассуждения — полностью «выключить мышление» удаётся не всегда. На повседневных задачах это незаметно, но если вы считаете токены в API-режиме, имейте в виду.
Ещё один механизм — бюджет рассуждений (thinking budget): можно ограничить, сколько токенов модель тратит на размышление. Когда лимит достигнут, она принудительно переходит к ответу на основе того, что успела обдумать. Удобно, когда нужен баланс между скоростью и качеством.
Сколько нужно железа: VRAM, кванты и скорость
Это ядро статьи. Как и другие локальные модели, Qwen3 запускают в квантованном виде — со сжатием весов до 4–8 бит в формате GGUF. Самый ходовой квант — Q4_K_M: минимальная потеря качества при максимальной экономии памяти.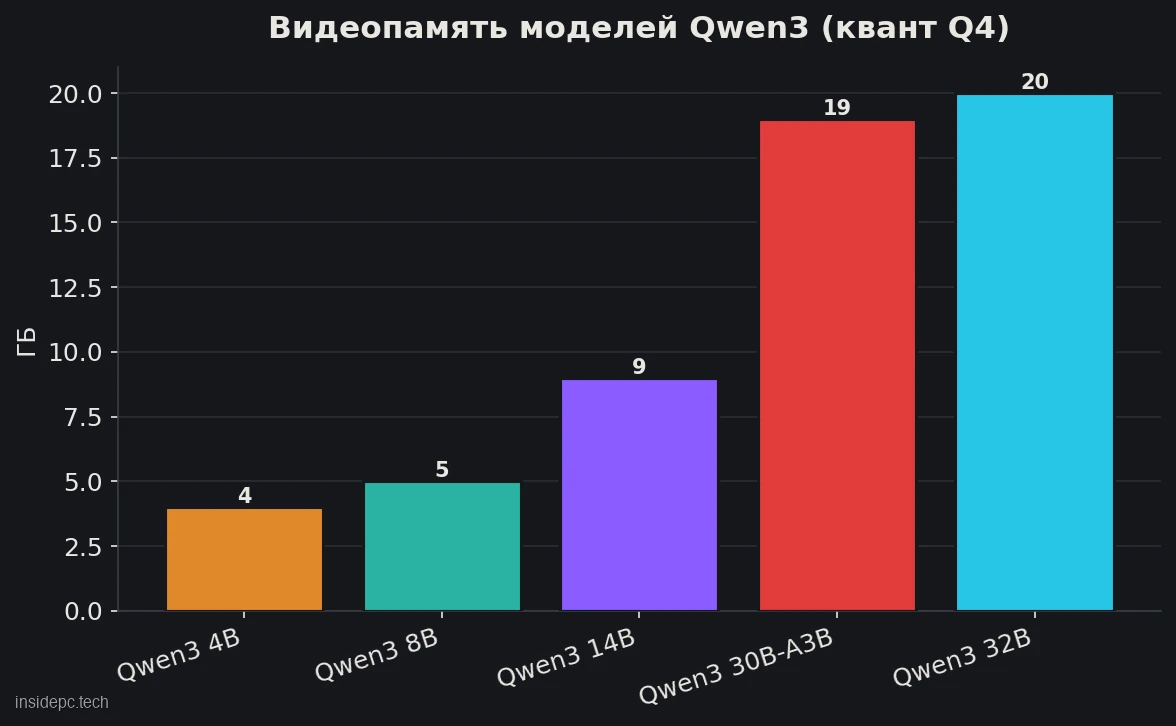
Вот сколько нужно под каждую модель (размеры файлов — по каталогу Ollama, июнь 2026; скорость — по замерам сообщества на RTX 4090 и RX 7900 XTX, кванты указаны):Модель (Q4) Размер файла Комфортное железо Скорость* Qwen3 0.6B–4B ~1–4 ГБ 8 ГБ VRAM, 0.6B — даже CPU очень высокая Qwen3 8B ~5 ГБ (файл) RTX 3060 8 ГБ и выше ~120+ tok/s (RTX 4090, 9B Q5) Qwen3 14B ~9 ГБ (файл) 12–16 ГБ VRAM высокая Qwen3 30B-A3B ~19 ГБ (файл) 24 ГБ VRAM ~34 tok/s (RX 7900 XTX) Qwen3 32B ~20 ГБ (файл) 24 ГБ VRAM ~52 tok/s (RTX 4090, 27B Q4)
*Скорость указана по замерам поколения Qwen3.5 (ближайшего по размеру) на RTX 4090, кроме 30B-A3B (RX 7900 XTX); для оригинального Qwen3 результаты близки, но могут отличаться. Размер в столбце — это файл модели в каталоге Ollama, а не полная потребность в видеопамяти.
Что это значит на практике:
- 8 ГБ VRAM — ваш дом это Qwen3 8B в Q4_K_M. Отличный универсал: чат, перевод, код, базовая логика.
- 12–16 ГБ VRAM — Qwen3 14B, заметный прирост качества, либо 8B в высоком кванте с запасом под контекст.
- 24 ГБ VRAM (RTX 3090/4090) — здесь живут оба «домашних флагмана»: dense 32B и MoE 30B-A3B. Обе в Q4 умещаются в видеопамять целиком.
Важная поправка про память: видеокарта тратит её не только на веса, но и на KV-кэш под контекст диалога. Размер файла модели — это минимум; под длинный контекст добавьте ещё несколько гигабайтов. Поэтому модель, которая по файлу влезает впритык, на окне в 128K токенов может не запуститься.
И отдельная грабля Ollama: по умолчанию он ограничивает контекст примерно 40 тысячами токенов, даже если модель поддерживает 128K. Чтобы задействовать полное окно, явно задайте параметр num_ctx (например, 131072) в чате или в Modelfile — иначе длинные документы будут молча обрезаться.
Цифры скорости — ориентир: они зависят от версии Ollama и llama.cpp, длины контекста и кванта. Свежие замеры под конкретную модель сверяйте на её странице в каталоге Ollama.
Dense 32B или MoE 30B-A3B: что выбрать
На 24 ГБ видеопамяти у вас встаёт интересный выбор между двумя почти одинаковыми по «весу» моделями — и большинство обзоров их не сравнивают честно. Вот суть.
- Qwen3 32B (dense) — задействует все 32 млрд параметров на каждый токен. Максимум качества в своём классе, но медленнее: ~52 токена/с на RTX 4090.
- Qwen3 30B-A3B (MoE) — занимает в памяти примерно столько же (~19 ГБ против ~20 ГБ), но на каждый токен активирует лишь 3 млрд параметров из 30. Итог — заметно быстрее и холоднее, при качестве, близком к dense на многих задачах.
Простое правило: нужна максимальная точность и не жалко скорости — берите dense 32B. Нужен быстрый отзывчивый помощник под повседневные задачи на той же карте — 30B-A3B часто приятнее в работе. На железе с ограниченным охлаждением (мини-ПК, ноутбук) MoE-вариант предпочтительнее из-за меньшей нагрузки.
Apache 2.0 против Llama Community License
Здесь Qwen3 объективно сильнее главного конкурента. Все открытые модели Qwen3 идут под лицензией Apache 2.0 — одной из самых свободных. Что это даёт на практике:
- коммерческое использование без порогов по числу пользователей;
- никаких роялти и обязательных согласований с правообладателем;
- право встраивать, модифицировать и распространять модель, в том числе обучать на ней свои модели.
Сравните с обзором Llama: там действует Llama Community License с порогом в 700 млн пользователей в месяц, запретом учить на выходах Llama другие модели и ограничениями для конкурентов. Для домашнего использования разница незаметна, но если вы строите продукт — особенно с прицелом на масштаб или на обучение своей модели — Apache 2.0 у Qwen3 снимает целый класс юридических рисков.Модель Лицензия Порог пользователей Обучать свои модели на выходах Qwen3 Apache 2.0 нет можно Llama 4 / 3.x Llama Community 700 млн MAU нельзя
Русский и украинский: где Qwen3 впереди
Это наш главный information gain. Qwen3 официально поддерживает 119 языков и диалектов, и в таблице индоевропейской группы официального блога Qwen русский и украинский перечислены явно. Это не «случайно понимает», а заявленная поддержка с репрезентацией в обучающих данных.
На практике это выводит Qwen3 в лидеры открытых моделей по качеству русского. По отзывам сообщества r/LocalLLaMA и независимым тестам именно Qwen3 регулярно называют лучшей открытой моделью для русскоязычных задач, тогда как у Llama русский вообще не входит в официально поддерживаемые языки. Для текстов, перевода и диалога на русском или украинском Qwen3 — самый разумный локальный выбор.
Если вам нужен ещё более широкий охват языков, новые поколения Qwen3.5 и Qwen3.6 расширили список до 201 языка. Но и оригинального Qwen3 с его 119 языками для русского и украинского более чем достаточно.
Практический совет: даже на сильной в русском Qwen3 не пренебрегайте системным промптом с явным указанием языка и стиля — это убирает редкие проскальзывания в английский на технических терминах и делает ответы стабильнее. А для перевода, редактуры и суммаризации русских и украинских текстов локального Qwen3 8B часто достаточно, чтобы полностью отказаться от облачных сервисов: качество приемлемое, данные не покидают компьютер, а платить за токены не нужно.
Запуск: Ollama, LM Studio, llama.cpp, vLLM
Под капотом — всё тот же движок llama.cpp, поверх которого работают удобные обёртки. Выбор зависит от сценария.
Ollama — самый простой старт. Модель скачивается и запускается одной командой (проверено по каталогу Ollama, июнь 2026):
ollama run qwen3:8b # рабочая лошадка, 8 ГБ VRAM
ollama run qwen3:14b # средний класс
ollama run qwen3:30b # MoE 30B-A3B, быстрая на 24 ГБ
ollama run qwen3:32b # dense, максимум качества на 24 ГБ
Ollama сразу поднимает локальный API, совместимый с форматом OpenAI, — удобно для подключения к редакторам кода и ботам. Не забудьте про num_ctx, если нужен длинный контекст (см. раздел про железо).
LM Studio — графический интерфейс с каталогом моделей и ползунками настроек, включая переключатель режима рассуждений. Хороший выбор, если не любите терминал.
vLLM и SGLang — для производительного инференса и серверных сценариев. Здесь режим рассуждений включается явным флагом, например (требуется vLLM не ниже 0.8.4):
vllm serve Qwen/Qwen3-30B-A3B --enable-reasoning --reasoning-parser deepseek_r1
Версии фреймворков быстро меняются — перед запуском сверяйтесь с актуальной документацией Qwen.
Если планируете докупать видеокарту под Qwen3, ориентируйтесь на объём VRAM — подробный разбор в гиде по выбору GPU для ИИ.
Настройка под себя: контекст, рассуждения и режим API
После установки Qwen3 стоит подстроить под свои задачи. Ключевые параметры:
- Длина контекста (num_ctx). Главная настройка для Qwen3: модель держит 128K токенов, но Ollama по умолчанию даёт лишь ~40K. Для длинных документов поднимайте
num_ctxвручную — помня про расход видеопамяти на KV-кэш. - Режим рассуждений. Держите модель в быстром режиме (
/no_think) для чата и переключайте в/thinkна сложных задачах — это экономит время и токены там, где пошаговые рассуждения не нужны. - Температура. Общепринятые ориентиры сообщества: для кода и фактических задач — 0.1–0.3, для свободного текста — 0.6–0.8. В режиме рассуждений температуру лучше не задирать, чтобы цепочка мысли оставалась связной.
- Системный промпт. Для русского и украинского явная инструкция отвечать на нужном языке улучшает результат, хотя Qwen3 и так силён в этих языках.
В Ollama параметры задаются на лету (/set parameter num_ctx 32768) или через Modelfile, где базовая модель, системный промпт и настройки фиксируются в один свой вариант командой ollama create.
Режим API — почему локальный Qwen3 удобен в работе. Ollama сразу поднимает сервер на localhost:11434 с интерфейсом, совместимым с OpenAI. Любой инструмент, рассчитанный на ChatGPT через API, переключается на локальный Qwen3 сменой адреса. Так его подключают к:
- редакторам кода и плагинам автодополнения;
- Telegram- и Discord-ботам;
- скриптам на Python через стандартную библиотеку OpenAI;
- системам RAG и обработки документов.
Все данные при этом остаются на вашем компьютере, а за токены платить не нужно. И отдельный плюс именно Qwen3: благодаря лицензии Apache 2.0 результаты его работы можно использовать в коммерческих продуктах без оглядки на ограничения.
Qwen3 против Llama, Gemma и Mistral
«Лучшей модели вообще» не бывает. Вот честное сравнение Qwen3 с тремя главными соперниками в локальном сегменте (по состоянию на июнь 2026).Критерий Qwen3 Llama Gemma Mistral Small Русский/украинский Лучший Средне Хорошо Средне Код и математика Очень хорошо Хорошо Очень хорошо Хорошо Лицензия Apache 2.0 Community (пороги) Apache 2.0 Apache 2.0 Режим рассуждений Встроенный (гибрид) Нет (отдельные модели) Частично Частично Цензура политики Есть (в instruct) Минимальная Минимальная Минимальная Экосистема / кванты Очень большая Крупнейшая Большая Средняя
Где Qwen3 объективно впереди: русский язык, свободная лицензия и встроенный гибридный reasoning. Где стоит выбрать иначе: если для вас критична свобода от любой политической цензуры — у Llama, Gemma и Mistral её фактически нет (об этом ниже); если нужна максимально крупная экосистема готовых сборок — у Llama она шире.
Риски и грабли: цензура и не только
- Политическая цензура (главный честный минус). Готовые (instruct) версии Qwen3 уходят от острых тем, связанных с политикой Китая, — это задокументировано и независимыми исследованиями (arXiv, 2026), и анализом на Hugging Face, и опытом пользователей r/LocalLLaMA. Важный нюанс: цензура добавляется на этапе тонкой настройки, поэтому базовые (Base) версии модели практически свободны от неё — если фильтр вам мешает, берите Base и донастраивайте под себя. На 99% задач разработки, перевода и анализа цензура не проявляется вовсе, но знать о ней нужно.
- Утечка рассуждений в быстром режиме. Как отмечено выше,
/no_thinkне всегда полностью отключает размышления — для экономии токенов в API это стоит проверять на своих сценариях. - Контекст Ollama по умолчанию урезан. Без явного
num_ctxдлинные документы молча обрезаются на ~40K токенов. - Путаница версий. Qwen3, Qwen3-Next, Qwen3.5, Qwen3.6 — разные поколения с разными возможностями. Сверяйте точное имя модели и её дату.
- Бенчмарки флагмана ≠ домашний опыт. Рекордные цифры (85,7 на AIME) принадлежат модели 235B в режиме рассуждений; локально её не запустить — нужен сервер. Ориентируйтесь на результаты той модели, которая реально влезает в ваше железо.
- MoE не экономит видеопамять. 30B-A3B быстрее, но в память грузятся все 30 млрд весов — на 8 ГБ она не запустится, несмотря на «3B активных».
- Перегрев при долгих сессиях. Тяжёлые модели надолго нагружают видеокарту — следите за температурами, особенно на компактных сборках.
FAQ
Какую модель Qwen3 выбрать для видеокарты на 8 ГБ? Qwen3 8B в кванте Q4_K_M — оптимальный вариант: умещается в 8 ГБ с рабочим контекстом и хорошо тянет чат, перевод и код. Если нужен запас под длинный контекст, берите 4B в более высоком кванте. Модели 14B и крупнее на 8 ГБ уже не поместятся целиком.
Работает ли Qwen3 на процессоре без видеокарты? Да, самые маленькие версии (0.6B и 1.7B) запускаются на CPU, хотя и медленно. Это годится для лёгких задач и экспериментов. Для комфортной работы всё же нужна видеокарта хотя бы на 8 ГБ.
В чём разница между Qwen3 и Qwen3.5/3.6? Qwen3 (апрель 2025) — проверенная база с огромным числом готовых квантов. Qwen3.5 (февраль 2026) и Qwen3.6 (апрель 2026) — новые поколения с поддержкой 201 языка и мультимодальностью (работа с изображениями). Для текстовых задач на русском оригинального Qwen3 достаточно; если нужны картинки или максимум свежести — берите старшие версии.
Как отключить режим рассуждений в Ollama?
Допишите к своему сообщению команду /no_think — модель ответит без пошаговых размышлений. Учтите, что по данным исследований полное отключение работает не всегда: модель может генерировать часть рассуждений даже в быстром режиме.
Сильно ли мешает цензура Qwen3 в обычной работе? Для разработки, перевода, написания текстов и анализа данных — практически нет: цензура касается узкого круга политических тем про Китай. Если эти темы важны для ваших задач, используйте базовую (Base) версию модели вместо instruct — она почти свободна от фильтров.
Qwen3 или Llama — что брать для русского языка? Qwen3. Русский и украинский официально входят в его 119 языков, и по независимым оценкам он лидирует среди открытых моделей в русскоязычных задачах, тогда как у Llama эти языки в официальную поддержку не входят.
Сколько места на диске займёт Qwen3?
Зависит от модели и кванта: Qwen3 8B в Q4 — около 5 ГБ, 14B — около 9 ГБ, а 32B и 30B-A3B — порядка 19–20 ГБ. Если планируете держать несколько моделей под разные задачи, закладывайте 50–100 ГБ свободного места. Ollama хранит скачанные модели в своей папке (~/.ollama/models на Linux и macOS, C:\Users\<имя>\.ollama на Windows); сменить путь можно переменной окружения OLLAMA_MODELS.
Как выбрать модель под свою задачу и железо среди других вариантов — в общем гиде по локальным LLM.










